Comentários
Em qualquer linguagem de programação, comentários são trechos de texto marcados de forma que sejam ignorados pelo compilador ou interpretador.
Na linguagem C, comentários de uma linha são feitos utilizando //, esse estilo de comentário foi adicionado no C99 e antes disso apenas comentários de bloco eram aceitos pela linguagem.
Esse tipo de comentário é ideal para descrições rápidas, geralmente ao lado ou logo acima do trecho de código que se deseja explicar. O ideal é utilizá-los para descrever algo que precise de esclarecimento ou justificava.
double c = 299792458; //Velocidade da luz (m/s)
//Estou fazendo isso por que é muito mais rápido
char *dados = mapearArquivoEmMemoria("teste.txt");
Comentários em várias linhas, também chamados de comentários em bloco, são iniciados com /* e finalizados com */.
Eles geralmente são utilizados para explicar funções, trechos de código mais complexos ou realizar justificativas mais detalhadas.
/*
Desenha o texto informado na posição X e Y informada
Fonte é o nome da fonte, este nome pode ser
NULL caso deseje utilizar a fonte padrão do sistema
*/
void desenhaTexto(const char *texto, int x, int y, const char *fonte);
/*
Estou utilizando criptografia aqui, mas ela é meia boca
porque o patrão pediu isso muito em cima e foi o que deu pra fazer
evite fazer código novo que use criptografia antes de implementar
"criptografiaV2" que deve virar o novo padrão no software
*/
void *dadosCriptografados = criptografiaV1(dados);
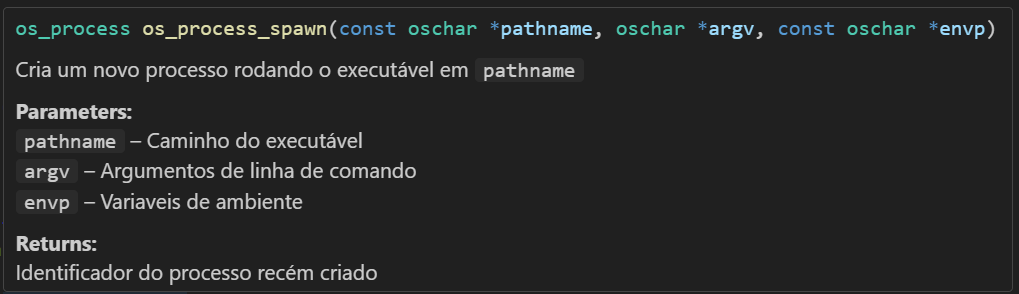
Uma boa prática é usar comentários em funções seguindo um formato como Doxygen ou a Documentação em XML utilizada no Visual Studio. A ideia de usar comentários seguindo estes padrões, é que é possível gerar páginas de documentações a partir deles, assim como eles também ajudam IDEs modernas a gerarem tooltips (menus de contexto) melhores e mais completos.
Por exemplo, podemos declarar esta função utilizando comentários no formato Doxygen :
/**
* @brief Cria um novo processo rodando o executável em `pathname`
*
* @param pathname Caminho do executável
* @param argv Argumentos de linha de comando
* @param envp Variaveis de ambiente
* @return Identificador do processo recém criado
*/
os_process os_process_spawn(const oschar *pathname, oschar *argv, const oschar *envp);
Ao colocar o mouse em cima de um código que esteja utilizando a função os_process_spawn, a IDE Visual Studio Code exibe um tooltip assim :
É importante lembrar que comentários em excesso e/ou em lugares inapropriados podem prejudicar a legibilidade do código, mas isso também não é justificativa para não comentar nada.
Sempre que for fazer um código que precisa de uma justificativa, se pergunte se ele é realmente necessário e se não tem outras alternativas melhores, em alguns casos, pode valer apena sacrificar performance por simplicidade, já em outros, o contrário também pode ser verdade.
Palavras Chave
Palavras chave são palavras reservadas da linguagem que não podem ser usadas em lugares onde um nome arbitrário pode ou deve ser definido. Essas palavras são utilizadas para identificar comandos ou especificações únicas da linguagem.
Lista de palavras chave
Algumas das palavras chave da linguagem foram introduzidas depois, em novos padrões da linguagem, nesses casos, os nomes dos padrões que introduziram a palavra chave estão escritos ao lado na tabela.
As palavras chave presentes na linguagem são :
alignas (C23) | extern | sizeof | _Alignas (C11) |
alignof (C23) | false (C23) | static | _AlignOf (C11) |
auto | float | static_assert (C23) | _Atomic (C11) |
bool | for | struct | _BitInt (C23) |
break | goto | switch | _Bool (C99) |
case | if | thread_local (C23) | _Complex (C99) |
char | inline | true (C23) | _Decimal128 (C23) |
const | int | typedef | _Decimal32 (C23) |
constexpr (C23) | long | typeof (C23) | _Decimal64 (C23) |
continue | nullptr (C23) | typeof_unqual (C23) | _Generic (C11) |
default | register | union | _Imaginary (C99) |
do | restrict (C99) | unsigned | _Noreturn (C11) |
double | return | void | _Static_assert (C11) |
else | short | volatile | _Thread_local (C11) |
enum | signed | while |
A grande maioria das palavras chaves que começam com _ são normalmente utilizadas junto de bibliotecas que definem macros para utilizar as palavras chaves com outros nomes mais simplificados, os nomes com underline foram introduzidos dessa forma inicialmente para evitar conflitos com código já existente.
No C23 alguns desses nomes “simplificados” se tornaram palavras chave nativas da linguagem e o uso da palavra chave utilizando _ se tornou depreciado (suportado mas não recomendado), dispensando também a necessidade de inclusão de uma biblioteca para uso dos nomes “simplificados”.
A tabela a seguir mostra as macros e as bibliotecas para cada palavra chave que começa com _, detalhando incorp. C23 para as macros que foram incorporadas a linguagem no C23 :
| Palavra Chave | Usado como | Definido em |
|---|---|---|
_Alignas (C11) | alignas (incorp. C23) | stdalign.h |
_Alignof (C11) | alignof (incorp. C23) | stdalign.h |
_Atomic (C11) | atomic_ + nomeTipo | stdatomic.h |
_BitInt (C23) | (sem macro) | |
_Bool (C99) | bool (incorp. C23) | stdbool.h |
_Complex (C99) | complex | complex.h |
_Decimal128 (C23) | (sem macro) | |
_Decimal32 (C23) | (sem macro) | |
_Decimal64 (C23) | (sem macro) | |
_Generic (C11) | (sem macro) | |
_Imaginary (C99) | imaginary | complex.h |
_Noreturn (C11) | noreturn (incorp. C23) | stdnoreturn.h |
_Static_assert (C11) | static_assert (incorp. C23) | assert.h |
_Thread_local (C11) | thread_local (incorp. C23) | threads.h |
Sumário das palavras chaves
Muitas das palavras chaves estão relacionadas a outros conceitos e serão explicadas com mais detalhes nos capítulos seguintes.
Essa seção serve como um sumário para demonstrar quais partes do documento apresentam quais palavras chaves.
Sumário das explicações e introduções a palavras chaves presentes no documento :
Operadores - Operadores especiais:sizeof,_AlignOf,_AlignAs,typeof,typeof_unqual.Variáveis - Modificadores de tipos:_Atomic,const,constexpr,restrict,volatile,signed,unsigned.Variáveis - Modificadores de armazenamento:auto,register,static,extern,thread_local.Variáveis - Palavra chave typedef:typedef.Caracteres:char.Inteiros:char,short,int,long,_BitInt.Booleanos:_Bool,bool,false,true.Ponto Flutuante:float,double.Ponto Flutuante - Números complexos e imaginários:_Complex,_Imaginary.Ponto Flutuante - Números decimais:_Decimal32,_Decimal64,_Decimal128.Controle de Fluxo:if,else,switch,case,default,break,goto.Laços de Repetição:continue,while,do,for.Funções:void,return,inline,_Noreturn.Enumerações:enum.Estruturas:struct.Uniões:union.
_Generic
Adicionada no C11, a palavra chave _Generic permite que você escolha uma expressão entre várias baseado no tipo de uma expressão em tempo de compilação.
A sintaxe para uso de _Generic é :
_Generic(expressao-tipo, lista-associacao);
Onde lista-associacao é uma lista de associação de tipos que segue a sintaxe :
nomeTipo : expressao
lista-associacaosegue uma sintaxe similar a palavra chaveswitch, onde há uma lista de possíveis associações para uma mesma expressão, mas ao invés de valores, estamos checando sua associação com tipos.expressao-tipoé uma expressão qualquer, que terá apenas seu tipo avaliado, portanto qualquer efeito colateral não será aplicado, que, obviamente, não pode incluir o operador,.nomeTipoé um tipo qualquer que não seja incompleto ou um array de tamanho variável ou a palavra chavedefault, indicando a expressão que será escolhido caso o tipo daexpressao-tiponão bata com nenhum outro.expressaoé uma expressão qualquer, de qualquer tipo ou valor, que pode inclusive ser uma função.
Exemplo do uso de _Generic para obter nomes de tipos primitivos e verificar qual o tipo utilizado por cada definição :
#include <stdbool.h>
#include <stdlib.h>
#include <stdio.h>
#include <inttypes.h>
#define nometipo(X) _Generic((X)0, \
unsigned char:"unsigned char", \
signed char:"signed char", \
char: "char", \
unsigned short:"unsigned short", \
short:"short", \
unsigned int:"unsigned int", \
int:"int", \
unsigned long:"unsigned long", \
long:"long", \
unsigned long long:"unsigned long long", \
long long:"long long", \
bool:"bool")
int main()
{
printf(
"uint8_t = %s\n"
"uint16_t = %s\n"
"uint32_t = %s\n"
"uint64_t = %s\n"
"size_t = %s\n"
"wchar_t = %s\n",
nometipo(uint8_t), nometipo(uint16_t),
nometipo(uint32_t), nometipo(uint64_t),
nometipo(size_t), nometipo(wchar_t)
);
}
Mas o uso mais comum de _Generic continua sendo para seleção de funções, no exemplo abaixo temos as diversas versões para obter o valor absoluto de um número para cada tipo em uma mesma macro :
#include <stdlib.h>
#include <math.h>
#define abs(X) _Generic(X, \
int:abs, \
long:labs, \
long long:llabs, \
float:fabsf, \
double:fabs, \
long double:fabsl)(X)
int main()
{
int a = abs(1);
long b = abs(1L);
long long c = abs(1LL);
float d = abs(1.0f);
double e = abs(1.0);
long double f = abs(1.0L);
}
Uma das motivações para a inclusão dessa palavra chave na linguagem é a possibilidade de permitir que o usuário implemente funções genéricas para tipos como as introduzidas no C99 pela biblioteca tgmath.h.
As funções da biblioteca tgmath.h originalmente eram implementadas usando extensões de cada compilador, porém o _Generic possibilita que o próprio usuário implemente um padrão similar em seu código.
static_assert
A palavra chave _Static_assert foi adicionada no C11, mas é acessível através da macro static_assert presente na biblioteca assert.h que foi incorporada a linguagem no C23, dispensando a necessidade de incluir a biblioteca.
Essa palavra chave permite que o usuário certifique que uma condição é Verdadeira, caso contrário, um erro de compilação será gerado.
A sintaxe para uso de static_assert é :
#include <assert.h> //Biblioteca para compatibilidade com versões antes do C23
//C11 em diante
static_assert(expressao, mensagem);
//C23 em diante
static_assert(expressao);
Onde :
expressaoé a expressão que será avaliada para determinar se um erro de compilação será gerado.mensagemé um literal de string indicando a mensagem que será exibida quando o erro é gerado, este campo era obrigatório até antes doC23.
Operadores
Os operadores são simbolos utilizados para operar com valores e variaveis.
Os usos dos operadores são diversos e os mesmos são separados em diferentes categorias.
Operadores de Atribuição
O principal operador de atribuição é o =, ele funciona de forma bastante simples :
variavel = valor;
A variável (ou local na memória) a esquerda, recebe o valor a direita.
No geral os operadores de atribuição, são em sua maioria junções do operador = com outros operadores já existentes, portanto vou apenas listar os que existem (aconselho que veja o resto do texto logo a seguir, que explica cada categoria de operadores com mais detalhes)
Para que um valor possa ficar no lado esquerdo de uma atribuição (o lado que recebe), ele deve ao menos indicar um local no qual o valor que está sendo recebido será guardado (seja uma variável, ou o conteúdo em um endereço de memória).
No geral é comum vermos menções disso nos seguintes termos em inglês:
lvalue: Valor que pode sofrer uma atribuição, vem deLeft Value(valor a esquerda)rvalue: Valor que só pode ser usado para leitura, vem deRight Value(Valor a direita)
| Operador | Descrição |
|---|---|
= | Atribuição |
+= | Soma e atribuição |
-= | Subtração e atribuição |
*= | Multiplicação e atribuição |
/= | Divisão e atribuição |
%= | Resto da divisão e atribuição |
<<= | Deslocamento de bit para esquerda e atribuição |
>>= | Deslocamento de bit para direita e atribuição |
&= | AND bit a bit e atribuição |
^= | XOR e atribuição |
⏐= | OR bit a bit e atribuição |
Os operadores de atribuição também geram como “resultado”, o valor atribuido, de forma que seja possível utilizar eles em outras expressões :
//Com isso, x = 10 e y = 15
int x, y, z;
y = (x = 10) + 5;
/*
Todas as três variaveis são iguais a 20 agora
Como a atribuição é avaliada da direita para esquerda,
podemos dizer que o que ocorre é :
Z recebe 20, Y recebe Z, X recebe Y
*/
x = y = z = 20;
Operadores de Aritmética Unária
Existem apenas dois operadores de aritmética unária que são + e -.
Para quem não sabe, unário indica que a operação ocorre com apenas um parâmetro, logo quando utilizamos +x ou -x estamos utilizando a operação unária, mas quando utilizamos x+y ou x-y estamos utilizando realizando outra operação (soma e subtração).
Ao aplicar um dos operadores, temos a promoção de tipos inteiros menores do que int ou unsigned int, para os tipos int ou unsigned int.
O operador + apenas realiza essa promoção, já o operador - inverte o sinal do valor e realiza a promoção :
short a = 50;
a; //O tipo dessa expressão é "short" e valor 50
+a; //O tipo dessa expressão é "int" e valor 50
-a; //O tipo dessa expressão é "int" e valor -50
Operadores Aritméticos
Os operadores aritméticos são utilizados para efetuar as quatro operações matemáticas básicas, junto da operação de resto de divisão, que está intimamente relacionada a divisão.
| Operador | Descrição |
|---|---|
+ | Soma |
- | Subtração |
* | Multiplicação |
/ | Divisão |
% | Resto da divisão |
Acredito que os operadores aritméticos sejam bem intuitivos para quem já estudou matemática, mas na dúvida eis aqui um exemplo demonstrando todos:
int soma, sub, mul, div, rest;
int x = 10;
int y = 5;
soma = x + y; //x + y = 15
sub = x - y; //x - y = 5
mul = x * y; //x * y = 50
div = x / y; //x / y = 2
rest = x % y; //x % y = 0 (não há resto)
7 % 5; //tem resto 2
10 % 3; //tem resto 1
//não podemos dividir por 0, essa operação pode fazer qualquer coisa
//(até mesmo finalizar seu programa)
x / 0;
Operadores de Incremento/Decremento
Estes são operadores que são de certa forma especiais, seu funcionamento é bastante simples, mas suas implicações são muitas, pois causam “efeitos colaterais”, assim como os operadores de atribuição.
No geral dizemos que uma expressão ou função causa efeitos colaterais quando ela tem algum efeito observável além de produzir um valor, um grande exemplo disso seria uma operação que modifica o valor operado, ou realiza operações adicionais como escritas em arquivos.
| Operador | Descrição |
|---|---|
++ | Incremento |
-- | Decremento |
O operador de incremento, aumenta em 1 o valor de uma variável, e o operador de decremento, diminuí em 1 o valor de uma variável, o que é diferente dos operadores de soma e subtração que não modificam a variável e apenas geram um valor.
O curioso desses operadores é que, a posição onde são colocados altera o comportamento, portanto ++x se comporta diferente de x++. Essa diferença se da pelo valor resultante da expressão, pois ao utilizarmos o operador como prefixo (++x ou --x), o valor é modificado primeiro e depois lido, e ao utilizarmos um sufixo (x++ ou x--), o valor é lido e depois modificado.
int i = 0;
i++; //Aumenta "i" em 1
i--; //Diminui "i" em 1
//Neste ponto, i é zero
int x = ++i; //"x" é 1 e "i" é 1 (pois i foi incrementado e depois lido)
int y = i++; //"y" é 1 e "i" é 2 (pois i foi lido e depois incrementado)
int z = --i; //"z" é 1 e "i" é 1 (pois i foi decrementado e depois lido)
int w = i--; //"w" é 1 e "i" é 0 (pois i foi lido e depois decrementado)
Poderiamos dizer que :
++xé equivalente a(x+=1)--xé equivalente a(x-=1)x++é equivalente a lerxe depois executarx+=1em outra linha de códigox--é equivalente a lerxe depois executarx-=1em outra linha de código
Operadores Booleanos
Todas as operações booleanas resultam apenas em Verdadeiro ou Falso, dizer que um valor é “Booleano” significa que ele só pode ter um desses dois valores.
As definições de Verdadeiro e Falso :
Falso: Valor igual a zeroVerdadeiro: Qualquer valor diferente de zero
Essas regras são válidas para qualquer lugar que deseja ler um valor qualquer como booleano.
Porém, para que seja possível atribuir Verdadeiro como um valor único, o valor utilizado para atribuir Verdadeiro na linguagem C é 1.
Portanto todos os operadores booleanos sempre resultam em 0 (Falso) ou 1 (Verdadeiro).
| Operador | Descrição |
|---|---|
== | Igual a |
!= | Diferente de |
> | Maior que |
>= | Maior ou igual a |
< | Menor que |
<= | Menor ou igual a |
! | NOT lógico |
&& | AND lógico |
⏐⏐ | OR lógico |
A maioria dos operadores são auto explicativos ao considerarmos a descrição juntamente ao fato de que todos operadores só retornam Verdadeiro ou Falso.
Com exceção, claro, dos três últimos operadores da tabela:
Not lógico: Opera com apenas um valor, invertendo seu estado deVerdadeiro/Falso, de forma que0vire1e valores diferentes de zero, virem0, sendo literalmente a lógica ao usarNão.AND lógico: Resulta emVerdadeiroquando ambos valores sejamVerdadeiro, sendo literalmente a lógica ao usarE.OR lógico: Resulta emVerdadeiroquando um dos valores éVerdadeiro, sendo literalmente a lógica ao usarOu.
Agora, para exemplificar, vamos pegar de exemplo a seguinte frase :
“João é inteligente, mas não passou na prova”
Logo, “João é inteligente” =
Verdadeiroe “João passou na prova” =FalsoAo usar
Not lógico, “Joãonãoé inteligente”, uma preposição que eraVerdadeirase tornouFalsapois invertemos o sentido dela.Ao usar
AND lógico, “João é inteligenteepassou na prova”, vemos que a frase se tornaFalsapois João não passou na prova.Ao usar
OR lógico, “João é inteligenteoupassou na prova”, a frase se tornaVerdadeira, pois mesmo que não tenha passado, acertamos que João é inteligente.
Avaliação de curto circuito
Os operadores AND lógico e OR lógico apresentam um comportamento extremamente único, a chamada “avaliação de curto circuito”, com ela, os valores só são avaliados quando isso é necessário.
Como assim quando isso é “necessário” ? bem se eu sei que um AND lógico só será Verdadeiro se ambos os valores forem Verdadeiros, ao saber que o primeiro dos valores é Falso, não há necessidade de avaliar o segundo valor para saber o resultado da expressão.
O mesmo se aplica para o OR lógico, se o primeiro valor é Verdadeiro, eu não preciso saber o resultado do segundo.
Logo caso o primeiro valor já seja o suficiente para estabelecer o resultado da expressão, a avaliação do segundo valor é ignorada, isso se torna ainda mais poderoso quando juntamos isso com Funções.
/*
Neste caso, não faria sentido se conectar ao servidor
se ele não estivesse funcionando, a ordem das checagens importa
e a avaliação de curto circuito impede o programa de perder tempo
tentando conectar num servidor que não está de pé
*/
if(servidorEstaVivo() && conectarServidor())
printf("Conectei!\n");
Operadores Bit a Bit
Antes de olhar esta parte sobre operadores bit a bit, aconselho fortemente que veja o capítulo sobre Números Binários, ou deixe este pedaço para depois.
Assume-se ao menos um conhecimento acerca de números binários e que o leitor saiba o que são BITS.
| Operador | Descrição |
|---|---|
~ | NOT bit a bit |
& | AND bit a bit |
⏐ | OR bit a bit |
^ | XOR bit a bit |
<< | Deslocamento de bit para esquerda |
>> | Deslocamento de bit para direita |
NOT bit a bit: Realiza uma inversão de cada bit do valor individualmente.AND bit a bit: Realiza uma operação similar aoAND lógicoem cada bit, gerando um resultado onde apenas os bits em comuns que os dois valores compartilham estão ativos.OR bit a bit: Realiza uma operação similar aoOR lógicoem cada bit, gerando um resultado onde os bits estão ativos a não ser que ambos os valores não tenham aquele bit ativo.XOR bit a bit: Traduzido, é umOU Não Exclusivo, seu papel é similar aoOR lógicoporém se ambos os valores foremVerdadeiros, o resultado éFalso, porém oXORem C não tem versão lógica, portanto ele é sempre bit a bit.Deslocamento de bit para esquerda: Desloca os bits para esquerda, resultando geralmente, numa multiplicação por 2 elevado naX, sendoXo número do deslocamento (claro que para valores com sinal, isso muda pois podemos acabar gerando um número negativo ao alcançar o bit do sinal)Deslocamento de bit para direita: Desloca os bits para direita, resultando geralmente, numa divisão por 2 elevado naX, sendoXo número do deslocamento.
Operações comuns utilizando os operadores bit a bit:
//Conseguir o valor que equivale ao bit Nº X (começando por bit 0)
bit = 1 << X;
//Ativar um bit
valor |= bit;
//Remover um bit
valor &= ~bit;
//Checar se um bit está ativo
if(valor & bit)
printf("Está ativo\n");
//Inverter o estado do bit (com XOR)
valor ^= bit;
Operadores Especiais
A linguagem C também apresenta alguns operadores adicionais que não se encaixam nas outras categorias, estes operadores geralmente fornecem funcionalidades únicas.
| Operador | Descrição |
|---|---|
() | Chamada de função |
, | Operador virgula |
(tipo) | Conversão de tipo |
? : | Ternário |
sizeof | Tamanho de |
_AlignOf | Alinhamento de (C11) |
_Alignas | Alinhar como (C11) |
typeof | Tipo de (C23) |
typeof_unqual | Tipo sem modificadores de (C23) |
Chamada de função
Ao chamar uma função , utilizamos o operador (), preenchido com uma lista separada por virgulas de zero ou mais argumentos, toda chamada de função é precedida de uma expressão que resulta num ponteiro de função (seja o nome direto da função, ou uma variável guardando o endereço de uma função).
Operador virgula
Este operador é utilizado para adicionar uma expressão adicional, ignorando o resultado da expressão anterior, mas ainda levando em consideração os seus efeitos colaterais. Por exemplo ao escrevermos a,b, os efeitos colaterais de a são aplicados, porém, o resultado da expressão como um todo será o resultado de b.
int x;
// O efeito colateral de (x = 10) é aplicado, tornando o valor de X como 10
// Porém o valor lido, é o da expressão X + 5, que será 15.
const int y = x = 10, x + 5;
// Neste caso, Z será 70, pois os efeitos colaterais de ambas
// expressões são aplicadas e o resultado da expressão será
// a última, (2 * x) que é 70
const int z = x = 20, x += 15, 2 * x;
Conversão de tipos
Este operador é utilizado para converter um tipo para outro, algumas conversões tem comportamentos especificos como por exemplo :
Para void: É possível realizar conversões para o tipovoidque simboliza uma ausência de tipo/valor, isso é útil por exemplo para ignorar o retorno de algumas funções intencionalmente quando, por exemplo, configuramos o compilador para avisar quando um retorno de função é ignorado.Inteiros maiores para menores: Ao converter números inteiros que usam mais bytes para tipos inteiros menores, o valor é truncado, cortando fora os bytes que excedem o tamanho do tipo menor.Ponteiro para inteiro: É possível converter ponteiros para tipos inteiros, no geral é aconselhável utilizar o tipointptr_touuintptr_tque naturalmente tem o mesmo tamanho em bytes e desde oC99funcionam de forma garantida se a implementação fornece esses tipos, a conversão de um ponteiro nulo não necessariamente precisa dar 0 ao ser convertida para um inteiro.Inteiro para ponteiro: É possível converter números inteiros para ponteiros, porém não há nenhuma garantia que o valor esteja alinhado ou aponte para uma variável do tipo certo.Ponteiro de valor para ponteiro de valor: Qualquer ponteiro de valor (que não seja de função) pode ser convertido para um tipo ponteiro de “caractere” (char,signed char,unsigned char) para que seja possível copiar o objeto ou ler sua representação interna em bytes, outras conversões são aceitas mas idealmente devem ter um alinhamento adequado.Ponteiro de função <-> ponteiro de valor: Conversões entre esses dois tipos são proibidas, porém, vários compiladores suportam eles como extensões e ao menos no Windows e Linux, eles são necessários para carregar funções de bibliotecas dinâmicas utilizandoGetProcAddressedlsymrespectivamente.Ponteiros para ponto flutuante: Conversões entre ponteiros e variaveis de ponto flutuante são proibidas.
#include <inttypes.h>
//Ignorando retorno
(void)printf("Teste...\n");
//"valor2" é limitado a apenas a metade baixa de "valor1"
int32_t valor1 = 0xF7FFF;
int16_t valor2 = (int16_t)valor1; //0x7FFF = 32767
//dlsym é do tipo "void*", isso efetivamente só funciona
//como uma extensão da linguagem pelos compiladores.
void (*fazCafe)(int);
fazCafe = (void (*)(int)) dlsym(biblioteca,"fazerCafe");
fazCafe(4);
Ternário
O operador ternário apresenta a sintaxe CONDIÇÃO ? VALOR_SE_VERDADE : VALOR_SE_FALSO, e de acordo com o valor de CONDIÇÃO, escolhe qual valor será avaliado e usado como resultado da expressão.
A ideia do operador ternário é substituir o uso de condicionais por algo menor que possa ser utilizado em outras expressões.
Exemplos:
//O seguinte bloco ternário :
valor = condicao ? a : b;
//Tem o mesmo comportamento de :
if(condicao) {
valor = a;
} else {
valor = b;
}
//Este bloco ternario :
valor = condicao1 ? a :
condicao2 ? b :
condicao3 ? c
/* else */: d;
//Tem o mesmo comportamento de :
if(condicao1) {
valor = a;
} else if(condicao2) {
valor = b;
} else if(condicao3) {
valor = c;
} else {
valor = d;
}
Operador sizeof
O operador sizeof pode ser usado para obter o tamanho de qualquer tipo, variável ou valor, diretamente em bytes.
No geral mesmo quando um valor é passado ao sizeof, o valor não é realmente avaliado e sim o tamanho que o tipo daquele valor teria, portanto expressões que ocasionariam em erros ou crashs no programa ao serem avaliadas, não o causam, pois não são realmente avaliadas.
Na maioria dos casos, com exceção de arrays de tamanho variável, o operador sizeof é avaliado durante a compilação, portanto seu uso não afeta o tempo de execução (nesses casos ele é efetivamente uma constante), o tipo do valor resultante do sizeof é sempre do mesmo tipo de size_t.
int arr[40];
//igual a 40 * sizeof(int)
sizeof(arr);
//geralmente 4 nos processadores/compiladores modernos
sizeof(int);
/* É possível utilizar "sizeof" na mesma linha que uma variável
é declarada e mesmo que "*pessoa" seja indefinido, o operador
"sizeof" funciona normalmente */
struct Pessoa *pessoa = malloc(sizeof(*pessoa));
Operador _AlignOf
O operador _AlignOf foi adicionando no C11 junto da biblioteca stdalign.h que incluia definições para usar _AlignOf com o nome alignof.
No C23, o operador alignof foi adicionado a linguagem, dispensando o stdalign.h.
Este operador funciona de forma similar ao sizeof, porém ao invés de obter o tamanho em bytes do tipo, ele obtêm a quantidade de bytes consideradas o requisito de alinhamento do tipo.
O requisito de alinhamento é um número do tipo size_t que indica o número de bytes do qual o endereço deve ser múltiplo para que esse
objeto possa ser alocado.
Algumas arquiteturas proibem alguns acessos a valores não alinhados (por exemplo ler 2 bytes de uma vez de um endereço que tem um valor impar).
Operador _Alignas
Da mesma forma que o operador _AlignOf, foi adicionada no C11com a stdalign.h para permitir seu uso como alignas, que foi incorporado a linguagem no C23, dispensando o stdalign.h.
Este operador é usado para forçar um requisito de alinhamento diferente em variaveis, porém ele não pode ser usado para forçar um requisito de alinhamento menor do que o requisito mínimo do tipo.
A utilidade desse operador é um tanto difícil de entender, mas ele basicamente funciona como uma forma de controlar o alinhamento para possivelmente melhorar a performance.
Um exemplo do seu uso seria alinhar ao tamanho do cache do processador, de forma que variaveis diferentes caiam em linhas diferentes do cache (o que pode otimizar o acesso quando múltiplos threads estão acessando os elementos).
Manter objetos na mesma linha do cache poderia forçar diferentes threads a competir pelo acesso de uma mesma linha de cache (fazendo com que um tenha que “esperar” o outro).
#include <stdalign.h>
#include <stdio.h>
/**
Digamos que cada linha do cache tem 64 bytes
Estou forçando este objeto a estar alinhado ao cache,
logo threads nunca vão "competir" para acessar elementos
próximos
*/
struct alignas(64) Arquivo {
FILE *arq; /* identificador do arquivo */
size_t tam; /* tamanho do arquivo */
};
Operador typeof
O operador typeof foi adicionado apenas no C23, ele sempre resulta num tipo de variável, que pode ser utilizado em todos lugares onde um tipo de variável normalmente seria utilizado (seja na definição de variaveis, parâmetros de função, membros de uma estrutura,etc).
De forma similar ao operador sizeof, ele funciona com tipos e variaveis, e não avalia os valores das variaveis que ele recebe, apenas
as usa para extrair o tipo.
int a;
typeof(a) b; //igual a "int b"
struct Pessoa pessoa;
typeof(&pessoa) ptr = &pessoa;
//Algumas declarações também podem ser feitas
// de uma forma "diferente" usando "typeof" :
//Array de ponteiros de função do tipo "int FUNCAO(int)"
int (*arr[])(int);
//OU
typeof(int(int)) *arr[];
//Três ponteiros para inteiro
int *p,*q,*r;
//OU
typeof(int*) p,q,r;
Operador typeof_unqual
Funciona de maneira similar ao operador typeof, porém todos os modificadores de tipos de variáveis como volatile, const, restrict, _Atomic não são levados em consideração.
Ordem de precedência
A ordem de precedência é a prioridade com a qual os operadores são aplicados.
A associatividade é a ordem que os operandos são avaliados e será abreviada para simbolos de forma a simplificar a tabela :
>: Esquerda para direita<: Direita para esquerda
Os itens mais no topo da tabela a seguir, são os itens de maior prioridade (ordem decrescente):
| Operador(es) | Descrição | Associatividade |
|---|---|---|
++/-- | Incremento/Decremento (sufixo) | > |
() | Chamada de função | > |
[] | Subscrição de array/matriz | > |
. | Acesso de membro de estrutura/união | > |
-> | Acesso de membro de estrutura/união via ponteiro | > |
(tipo){lista} | Literal composto (C99) | > |
++/-- | Incremento/Decremento (prefixo) | < |
+/- | Sinal de valor (ex: +5 ou -5) | < |
!/~ | NOT lógico e bit a bit | < |
(tipo) | Conversão de tipo | < |
* | Indireção (desreferenciar) | < |
& | Endereço de | < |
sizeof | Tamanho de | < |
_AlignOf | Alinhamento de (C11) | < |
*///% | Multiplicação, divisão e resto | > |
+/- | Soma e subtração | > |
<</>> | Deslocamento de bit | > |
</<=/>/>= | Comparações de maior/menor | > |
==/!= | Igual a ou diferente de | > |
& | AND bit a bit | > |
^ | XOR bit a bit | > |
⏐ | OR bit a bit | > |
&& | AND lógico | > |
⏐⏐ | OR lógico | > |
?: | Condição ternária | < |
= | Atribuição | < |
+=/-= | Soma/subtração e atribuição | < |
*=//=/%= | Multiplicação/divisão/resto e atribuição | < |
<<=/>>= | Deslocamento de bit e atribuição | < |
&=/^=/⏐= | AND/XOR/OR bit a bit e atribuição | < |
, | Operador virgula | > |
No geral muitos programadores utilizam parenteses para forçar uma certa ordem de precedência. Isso diminui a necessidade de um estudo mais minucioso dessa tabela, ao mesmo tempo que facilita a leitura do código para pessoas que não a decoraram, ou que tem pouca experiência
Ordem de Avaliação
A ordem de avaliação se refere a ordem com que as operações acontecem, a ordem com que os valores de variáveis são lidos.
No geral, na linguagem C, a ordem com que argumentos de função e subexpressões dentro de uma expressão são avaliadas não é especificada, permitindo que o compilador reordene as operações como desejar (lembrando que nesses casos, a decisão de como o compilador vai ordenar as expressões pode mudar dependendo do nível de otimização especificado).
A verdade é que não existe um conceito de “avaliação da esquerda para direita” ou “avaliação da direita para esquerda” como normalmente encontramos em matemática, as ordens são normalmente definidas pelo próprio compilador.
Um exemplo seria a avaliação de f1() + f2() + f3(), por conta do operador + ser associado com as expressões a sua esquerda e direita, teremos o equivalente a (f1() + f2()) + f3(), porém, a avaliação de f3() pode ocorrer antes de (f1() + f2()).
A dica é, jamais dependa de uma ordem que o compilador pode mudar, faça seu programa de forma que operações que tem o mesmo nível de prioridade, resultam no mesmo valor independente da ordem em que sejam realizadas, caso não seja possível, separe a expressão em mais linhas de código para garantir a ordem de operações desejada.
Pontos de sequência
Normalmente referenciados em inglês, como “sequence points”, se referem a partes do código que garantem que os efeitos colaterais anteriores devem finalizar antes de prosseguir, pontos de sequência servem como “separadores” que garantem a ordem das expressões, sem eles poderiamos ter várias expressões que podem ser realizadas em qualquer ordem.
Os operadores, pontuadores e palavras chaves que servem como pontos de sequência :
- O pontuador
;garante que a expressão antes dele finalize antes de prosseguir. - O operador
&&garante que a expressão a esquerda dele finalize antes de avaliar a expressão a direita dele. - O operador
||garante que a expressão a esquerda dele finalize antes de avaliar a expressão a direita dele. - O operador
,garante que a expressão a esquerda dele finalize antes de avaliar a expressão a direita dele. - Numa chamada de função, todos os argumentos são avaliados antes da chamada de função realmente ocorrer.
- O operador
?garante que o primeiro argumento decondiçãoseja avaliado antes dos outros 2 (expressao-se-verdadeeexpressao-se-falso). - O fim da uma inicialização de variavel, garante que todas expressões usadas para inicializar a variavel sejam finalizadas.
- A expressão dentro de um
ifouswitché avaliada antes de prosseguir. - A expressão de controle em um
whileoudo whileé avaliada antes de repetir o laço. - As três expressões do
for, quando avaliadas, sempre terminam antes da execução da próxima iteração. - A expressão utilizada com a palavra chave
return, é completamente avaliada antes da função retornar.
Um exemplo que podemos usar ao nosso favor para entender melhor os pontos de sequência, é a regra que mais de um efeito colateral numa mesma variavel não pode ocorrer sem um ponto de sequência entre eles:
int i = 0;
i++ + i++; //Vai contra as regras do C (comportamento indefinido)
++i - ++i; //Também vai contra, nesse caso a resposta depende do compilador (pois o compilador é livre pra reordenar as operações)
i++ || i++; //Permitido, pois o "||" forma um ponto de sequência entre as operações
i++,i++; //Também é permitido
i++;i++; //Permitido, pois o ";" separa ambos
Variáveis
Variáveis são, efetivamente, lugares onde valores podem ser lidos ou escritos.
No geral são identificadas unicamente por nomes que definimos no nosso programa, junto com uma segunda descrição que chamamos de “tipo”.
Os tipos de variaveis são nomes predefinidos, que formam uma descrição “do que está sendo guardado”, que ajuda a descrever que tipo de operação deve ser feita para poder ler e escrever na variável que é de um determinado tipo.
Variáveis podem ser utilizadas para descrever todo tipo de dado, e idealmente, devem ter um nome que simplifica o entendimento do seu propósito e uso de forma a facilitar a leitura do código.
A linguagem C diferencia entre nomes em letra maiúscula e letra minúscula, logo variavel, VARIAVEL e VaRiAvEl são considerados nomes diferentes.
Quanto a variáveis, podemos fazer uma analogia simples mas efetiva :
Considere agora, que “variáveis” são caixas, geralmente usamos caixas para guardar coisas.
Porém, nem toda caixa tem o mesmo tamanho ou formato, existem vários
tiposde caixas, para propósitos diferentes.Se tivermos muitas coisas em caixas, fica difícil saber onde fica cada coisa, para isso, geralmente colocamos etiquetas com
nomes, pois isso facilita a organização e o entendimento do propósito de cada caixa.De certa forma,
lerde uma variável é similar ao processo de retirar algo de uma caixa da mesma forma queescreverem uma variável, é similar ao processo de colocar algo em uma caixa.
Modificadores de tipo
Ao declarar variáveis podemos adicionar modificadores, que servem para especificar detalhes adicionais sobre a variável e seu tipo.
| Modificador | Descrição |
|---|---|
_Atomic | Define que as operações de leitura/escrita são atômicas (C11) |
const | Define que a variável não pode mudar seu valor |
constexpr | Define que a variável é uma constante de compilação (C23) |
restrict | Indica que o ponteiro não sofre de aliasing |
volatile | Impede reordenamento e remoção de leitura e escrita |
signed | Usado para definir um inteiro com sinal |
unsigned | Usado para definir um inteiro sem sinal |
_Atomic
Introduzido no C11, o modificador _Atomic indica que as operações de leitura e escrita com um valor são atômicas.
Mas o que seria uma operação atômica? É uma operação que evita o que chamamos de “Condição de corrida” ou no inglês “data race”.
Uma condição de corrida é um problema que pode acontecer quando há mais de um thread (mais de um fluxo de execução) simultâneamente escrevendo/lendo de uma mesma variável ou local na memória.
Em caso do conflito descrito acima, um programa tem uma condição de corrida a menos que uma das condições abaixo seja cumprida :
- Ambas operações de leitura/escrita sejam atômicas
- Uma das operações acontece antes da outra (ou seja, elas não acontecem ao mesmo tempo)
Caso uma condição de corrida ocorra, o comportamento do programa é indefinido, mas na prática o comportamento mais comum é que um valor intermediário antes da atualização completa por uma das partes seja lido pela outra, de forma que ela opere com um valor inválido e os cálculos envolvendo essa variável também tenham resultados “incorretos”.
Ao mesmo tempo que operações atômicas evitam condições de corrida, elas também são consideravelmente mais lentas, por isso só devem ser utilizadas se realmente há um risco de uma condição de corrida ocorrer.
Qualquer compilador pode definir a macro __STDC_NO_ATOMICS__ para indicar que _Atomic não é suportado.
Para entender de forma mais simples como uma condição de corrida ocorre imagine dois fluxos de execução que querem incrementar em 1 um contador.
Imagine que o contador inicia em 0 e a seguinte sequência de operações ocorra :
- Fluxo 1 lê o valor do contador (0)
- Fluxo 1 incrementa o valor do contador no seu registrador (1)
- Fluxo 2 lê o valor do contador (0)
- Fluxo 1 guarda o valor atualizado (1)
- Fluxo 2 incrementa o valor do contador no seu registrador (1)
- Fluxo 2 guarda o valor atualizado (1)
Percebe como um contador que deveria ter 2, acabou resultando no valor 1 ?
É isso que normalmente acontece com uma condição de corrida, valores são atualizados sem levar em consideração modificações do outro fluxo.
Const
O modificador const faz com que o valor não possa ser modificado após sua definição.
Utilizar const ao definir variáveis ajuda a delimitar seu uso e evitar modificações desnecessárias e dependendo do caso pode permitir ou facilitar mais otimizações por parte do compilador ao delimitar melhor como valores serão utilizados.
Outro uso extremamente importante do const é ao utilizar ele com ponteiros em parâmetros de função, pois um const indica que o parâmetro não será modificado pela função, sem a necessidade de explicações adicionais.
//Como demonstra a função abaixo
//Os valores utilizados para calcular um "const" não precisam
//ser constantes
double pythagoras(double a, double b)
{
const double a2 = a * a;
const double b2 = b * b;
const double c = sqrt(a2 + b2);
return c;
}
void test()
{
int v1 = 50;
const int v2 = v1 + 10; //60
v2 = 70; //Erro, não pode modificar constante!
}
//"const" também
void copiaMemoria(const void *fonte, void *destino, size_t tamanho)
{
const char *bfonte = fonte;
char *bdestino = destino;
while(tamanho--)
*bdestino++ = *bfonte++;
}
Como constantes podem ser inicializadas com valores não constantes, elas não podem ser utilizadas como labels para o operador switch, usada para definir enum, inicializar valores definidos como static ou thread_local, bit fields em estruturas e quando utilizados como tamanho de arrays, os arrays resultantes são arrays de tamanho variável.
Constexpr
O modificador constexpr foi adicionado apenas no C23 e indica que a variável é uma constante de compilação.
Uma constante de compilação, é um valor que nunca muda e tem um valor que já é conhecido desde antes do programa iniciar (ou seja, seu valor foi adicionado diretamente no executável, sem necessidade de ser calculado durante a execução).
Dessa forma, um valor constexpr não tem as limitações do modificador const que não pode ser usado em lugares que exigem uma constante de compilação.
//Valor constexpr
constexpr int RODAS_CARRO = 4;
//Pode ser utilizado para inicializar enums
enum RodasDeVeiculos {
RODAS_MOTO = RODAS_CARRO / 2,
RODAS_CAMINHAO_GRANDE = RODAS_CARRO * 2,
};
//Pode ser utilizado como tamanho de array
int tipoRoda[RODAS_CARRO];
//Pode ser utilizado num switch, assim como o enum
switch(quantidadeDeRodas) {
case RODAS_MOTO:
puts("É uma moto");
break;
case RODAS_CARRO:
puts("É um carro");
break;
case RODAS_CAMINHAO_GRANDE:
puts("É um caminhão grande!");
break;
}
//Erro, não pode ser modificado!
RODAS_CARRO = 10;
Restrict
O modificador restrict indica que um ponteiro não sofre de “aliasing”.
O termo “aliasing” neste caso se refere a possibilidade de dois ponteiros distintos apontarem para o mesmo objeto, ou parcialmente, de forma que a modificação de um deles, afete o valor do outro.
Caso haja, por exemplo, uma função que recebe dois ponteiros de mesmo tipo, a cada escrita em um dos ponteiros, pode ser necessário ler novamente do outro ponteiro para que o C garanta o comportamento correto para qualquer entrada.
Portanto, uma função que obviamente não foi construida com este intuito, pode especificar restrict nos ponteiros, indicando que são valores que apontam para objetos distintos, ou mesmo que apontem para um mesmo objeto, indicando que isso não deve ser levado em consideração.
Indicar que ponteiros não sofrem de aliasing permite que o compilador gere um programa mais eficiente, que pode manter em cache/registradores os valores lidos ou executar várias operações simultâneas neles sem se preocupar em tratar uma possível modificação por meio de outros ponteiros.
//Por exemplo, se o compilador assumir aliasing, ele
//precisa fazer uma multiplicação por vez
void multiplicarArray(double *a, double *b, double *resultado, size_t tam)
{
for(size_t i = 0; i < tam; i++)
resultado[i] = a[i] * b[i];
}
/* Porém ao definir que as variaveis não dão "aliasing", o
compilador é livre para utilizar instruções que carregam
e multiplicam multiplos valores de uma vez, assumindo
que uma operação não afeta a outra */
void multiplicarArrayEx(double *restrict a, double *restrict b,
double *restrict resultado, size_t tam)
{
for(size_t i = 0; i < tam; i++)
resultado[i] = a[i] * b[i];
}
Volatile
O modificador volatile indica que leituras e escritas a variável não podem ser reordenadas, removidas por otimização ou lidas de cache.
A necessidade de uso desse modificador geralmente se da quando um valor pode ser modificado de forma imprevisível, ou serve para interfacear ou controlar hardware (controlar saídas, comunicar com HD, placa de rede, tela, GPU, etc).
Existem alguns motivos pelo qual esse modificador pode ser útil:
- Quando a variável pode ser diretamente modificada pelo hardware, ou o valor dela tem influência sobre o hardware
- Quando a variável faz parte de uma memória compartilhada e pode ser modificada por outros processos
- Quando há outros threads que podem modificar a variável
- Quando existe alguma função que modifica a variável e pode ser chamada externamente (como chamadas de procedimento remoto, ou os signals do POSIX que são geralmente chamados pelo próprio kernel)
Signed
Usado como modificador para declarar variáveis de tipos inteiros com sinal (ou seja, que podem ter valores negativos).
Na maioria dos casos, não há necessidade de declarar signed explicitamente, pois o padrão da maioria dos tipos inteiros já são inteiros com sinais, com uma única exceção do tipo char, que por padrão pode ser unsignedou signed, uma escolha que é definida pela implementação da linguagem pelos compiladores.
A única necessidade real de escrever
signedé para utilização do tiposigned char.
Unsigned
Usada como modificador para declarar variáveis de tipos inteiros sem sinal (ou seja, que não podem ter valores negativos).
Inteiros sem sinal tem certas vantagens em relação aos tipos com sinal, no geral por não incluir valores negativos, os tipos sem sinal geralmente conseguem guardar valores até duas vezes maiores do que o valor máximo de uma variável com sinal de tamanho equivalente.
No geral os tipos sem sinal garantem um comportamento circular em caso de overflow (ultrapassar o limite da variável), onde elas “dão a volta” e retornam ao valor 0, da mesma forma que subtrair 1 de 0, faz com que um número sem sinal chegue ao seu valor máximo (este caso é geralmente chamado de “underflow” e é um dos principais motivos para evitar números sem sinal).
Além disso o comportamento para deslocamento é sempre definido, enquanto que para valores com sinal, deslocar para esquerda os bits de um valor negativo é indefinido.
signed char a; //char com sinal (geralmente -128 a 127)
unsigned char b; //char sem sinal (geralmente 0 a 255)
int c; //int com sinal
unsigned int d; //int sem sinal
long long e; //long long com sinal
unsigned long long f; //long long sem sinal
//Valor máximo de um "unsigned char"
unsigned char teste = UCHAR_MAX;
//Neste caso, da overflow e resulta em 0 (isso é garantido pela linguagem)
teste = teste + 1;
//Valor mínimo de um "unsigned char"
unsigned char teste2 = 0;
//Neste caso, ocorre um underflow e o valor resulta em UCHAR_MAX
teste2 -= 1;
//Uma das armadilhas do C que muitos acabam caindo
//Alguns assumiriam que "v2" resultaria em "-2"
//PORÉM, a resposta certa é "2147483646" devido ao
//underflow em (v1-8)
unsigned int v1 = 4;
int v2 = (v1-8)/2;
Modificadores de armazenamento
Os modificadores de armazenamento podem ser utilizados para modificar variáveis ou funções e definem tanto a duração (apenas para variáveis) e vinculação (para ambos).
A duração, neste caso, é o escopo no qual a variável vai continuar existindo, os tipos de duração existentes são :
automática: A variável é armazenada quando o bloco inicia e desalocada quando o bloco é encerrado, isso se aplica a variáveis locais e parâmetros de funções.estática: A variável é armazenada durante toda a execução do programa, e o valor guardado no objeto é inicializado apenas uma vez, antes da execução da funçãomain, isso se aplica a variáveis globais ou variáveis comstaticdentro de funções.thread: A duração da variável é igual a duração do thread na qual ela foi criada e seu valor é inicializado quando o thread é inicializado.alocada: A variável foi alocada dinâmicamente usando alocação de memória dinâmica e pode ser desalocada a qualquer momento pelo próprio programa.
A vinculação, indica os locais onde a função ou variável é acessível e pode ser usada, para facilitar, é importante conhecermos o termo “unidade de tradução” do C.
Uma unidade de tradução é geralmente cada arquivo .c separado junto dos arquivos .h incluidos por ele, cada unidade de tradução é um dos arquivos que você pede para serem compilados pelo compilador.
Dito isso, os tipos de vinculação existentes são :
Sem vinculação: A variável ou função só pode ser referida dentro do mesmo bloco.Interna: A variável só pode ser referida dentro da mesma unidade de tradução.Externa: A variável pode ser referida por qualquer unidade de tradução, ou seja, pode ser referida por outros arquivos.
Os modificadores existentes são :
| Modificador | Descrição |
|---|---|
auto | Duração automática e sem vinculação |
register | Dica para que o compilador guarde a variável em registrador |
static | Duração estática e vinculação interna |
extern | Duração estática e vinculação externa |
thread_local | Duração de thread (C11) |
O padrão de cada tipo é :
- variável local : duração
automáticaesem vinculação - variáveis globais : vinculação
externa - funções : vinculação
externa
auto
O modificador auto é considerado inútil, pois só pode ser aplicado a variáveis locais e já é o comportamento padrão para elas.
register
O modificador register é utilizado para indicar que uma variável deve ser diretamente guardada apenas em registrador, isto é, nas “mãos” do processador, utilizadas para operar com valores, e portanto, o endereço da variável não pode ser acessado.
register implica duração automática e sem vinculação assim como a palavra chave auto.
Antigamente o modificador register era útil, ajudando nas otimizações ao fornecer dicas ao compilador, mas hoje em dia, com a presença de compiladores super inteligentes, eles acabam tendo muito mais informação do que nós sobre uma variedade de parâmetros ao decidir sobre otimizações, diminuindo ou eliminando vantagens que normalmente seriam oferecidas pela palavra chave register.
Apesar disso, vale relembrar que a palavra chave register ainda é a única forma de “proibir” o uso do endereço de uma variável.
static
O modificador static tem dois usos, ele pode ser usado dentro de blocos para definir variáveis que só podem ser acessadas no bloco mas tem duração estática, ou seja, mantêm o valor entre execuções da função e são efetivamente guardadas no mesmo lugar que variáveis globais seriam.
Seu segundo uso é para definir que funções e variáveis globais não afetem outras unidades de tradução, evitando conflitos de nomes e facilitando algumas otimizações (ao garantir que algo nunca vai ser usado externamente, algumas otimizações adicionais se tornam possíveis).
extern
O modificador extern normalmente não precisa ser usado em funções, pois já é o padrão.
Já em variáveis, o modificador funciona como uma “importação” de uma variável já existente, permitindo que ela seja usada no código, mesmo se ela estiver definida em outra unidade de tradução, mas ocasionando em erro caso não nenhuma unidade de tradução tenha a implementação da variável global.
//Caso 1, erro ao compilar, pois ninguém definiu
//a variável sem "extern"
//arquivo teste1.c
extern int a;
//arquivo teste2.c
extern int a;
//Caso 2, definição correta
//arquivo teste1.c
int a;
//arquivo teste2.c
extern int a;
//Nesse caso, teste2.c pode utilizar a variável
//que foi definida em teste1.c
thread_local
De forma similar ao _AlignOf descrito nos operadores, o modificador thread_local foi introduzido no C11 como _Thread_local junto da macro thread_local presente em threads.h, porém no C23, thread_local se tornou efetivamente um modificador válido no C.
O modificador thread_local simplesmente indica que a variável é local do thread, e é criada justamente quando um thread é criado. De forma que cada thread tenha sua própria cópia da variável, sendo ainda possível utilizar static/extern para ajustar o tipo de vinculação.
Palavra chave typedef
A palavra chave typedef é utilizada para definir um novo tipo de variável que é efetivamente um apelido para um tipo já existente.
O typedef também pode ser utilizado para gerar um apelido simplificado para um tipo complexo que tenha modificadores como const, volatile, _Atomic e/ou seja um ponteiro, ponteiro de função, etc.
A sintaxe para uso do typedef é igual a sintaxe de declaração de uma variável, no qual ao invés de criarmos uma variável, o nome que essa variável teria se torna o nome do novo tipo definido.
Essa similaridade se torna ainda mais evidente quando percebemos que de forma similar a declaração de uma variável, podemos declarar vários apelidos com um único typedef :
//Ao criar uma variável :
//Cria um "char" chamado "a"
//Um "ponteiro para char" chamado "b"
//E um "array fixo de char" chamado "c"
char a, *b, c[10];
//De forma similar, ao usar typedef :
//Cria um apelido para "char" chamado "ac"
//Cria um apelido para "ponteiro para char" chamado "bc"
//Cria um apelido para "array fixo de 10 chars" chamado "cc"
typedef char ac, *bc, cc[10];
//Agora é possível criar variáveis usando os apelidos!
ac v1; //char chamado v1
bc v2; //char* chamado v2
cc v3; //char[10] chamado v3
Ao perceber a similaridade entre declarações de variáveis e typedef, é dispensável explicações adicionais de como utilizar typedef com qualquer outra declaração mais complexa de tipos, pois o comportamento é exatamente o mesmo da declaração de uma variável.
Existe apenas uma única exceção desse comportamento do typedef onde é possível criar um apelido para um array de tipo incompleto, que pode ser posteriormente completado :
typedef char caracteres[];
//usa um typedef de um tipo incompleto, que foi completado na declaração
caracteres vogais = {'a','e','i','o','u'};
Variáveis primitivas
Variáveis primitivas são todas variáveis que utilizam tipos que existem inerentemente na linguagem e não dependem da existência de outros tipos.
Pode-se dizer que as variáveis primitivas são os principais blocos para construção de variáveis com tipos compostos, que dependem da existência de outros tipos.
Logo entender bem elas é crucial para entender bem os outros tipos mais complexos.
Os subtópicos nas páginas seguintes detalharão cada tipo de variável primitiva.
Caracteres
Caracteres são representados pelo tipo char, que também representa o menor tipo inteiro.
Isso acontece pois caracteres são representados por códigos númericos, que indicam diferentes caracteres.
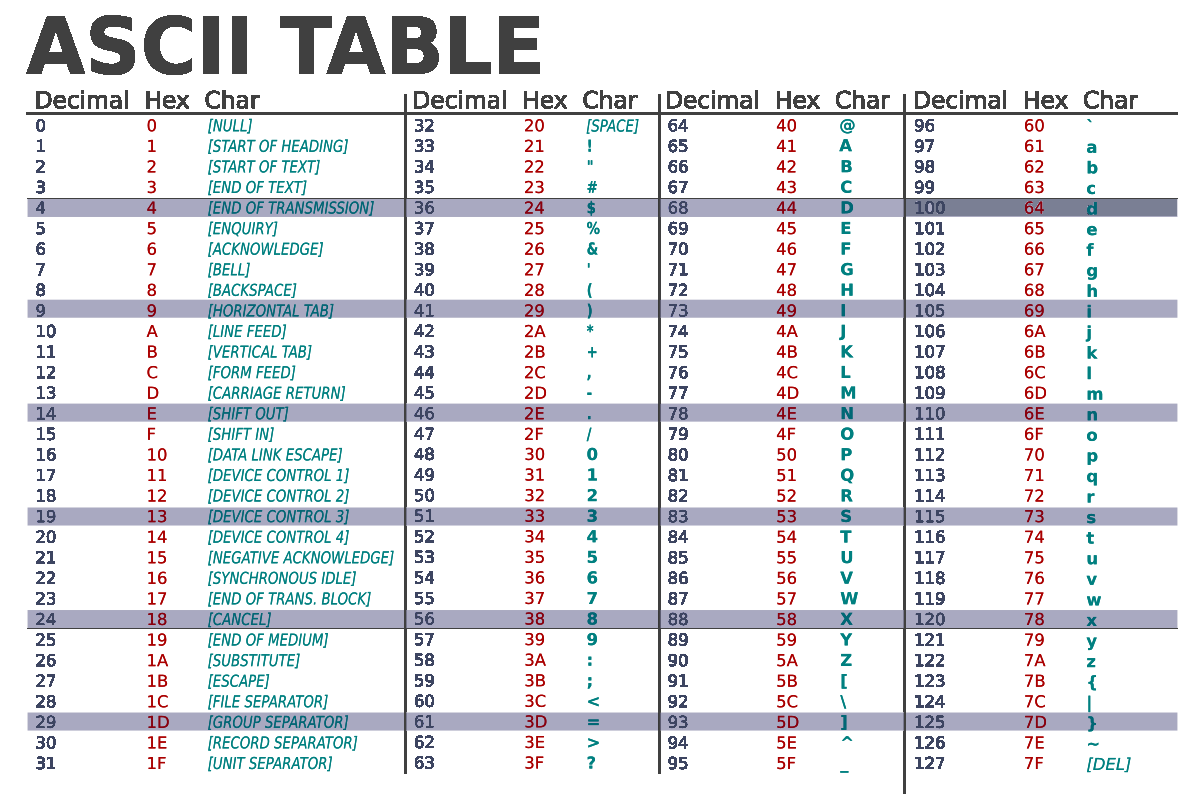
A implementação mais comum e adotada é o padrão ASCII, que estabelece um padrão para caracteres utilizando os código númericos de 0 a 127 para representar 128 caracteres diferentes.
Abaixo uma imagem representando a tabela ASCII:
Exemplo de código utilizando caracteres :
#include <stdio.h>
int main() {
char test = 'A';
putchar(test); //Escreve o caractere 'A'
}
Sequências de escape
Podemos escrever caracteres utilizando sequências de escape que começam com \.
Sendo elas:
\a: Alerta, geralmente toca um beep quando escrito (Bell 0x7)\b: Backspace, usado para apagar uma tecla (0x8)\f: Usado para quebra de página, mantendo a mesma posição horizontal mas em uma nova linha (Form Feed 0xC)\n: Escreve uma nova linha (LF ou line feed 0xA)\r: Volta o cursor para o início da linha (CR ou Carriage Return 0xD), além disso o padrão de nova linha do windows é\r\n\t: Equivalente ao “tab”, insere espaços para formatação (0x9)\v: Tab vertical (0xB)\': Usado para digitar o caractere'pois ele é normalmente usado para literais de caractere\": Usado para digitar o caractere"pois ele é normalmente usado para literais de string\\: Usado para digitar o caractere\pois ele é usado para sequências de escape\OOO: Usado para digitar um caractere em uma string, indicando uma sequência no sistema númerico octal,OOOdeve ser números de0a8\xHH: Usado para digitar caracteres ASCII, diretamente no seu valor em hexadecimal,HHpode ser uma sequência de qualquer tamanho de digitos hexadecimais.\unnnn: Usado para digitar um caractere Unicode com valorU+nnnn(desde oC99).\Unnnnnnnn: Usado para digitar um caractere Unicode com valorU+nnnnnnnn(desde oC99).
Tipos adicionais de caracteres
Existem outros tipos adicionais de caracteres, sendo eles :
wchar_t: Tipo de caractere “largo” definido pela plataforma, no geral é utilizado para caracteres em UTF-16 no windows e UTF-32 no linux/macOs.char8_t: Utilizado para guardar caracteres em UTF-8 e é o mesmo tipo efetivo deunsigned char(adicionado noC23).char16_t: Utilizado para guardar caracteres que ocupam até 16bits (adicionado noC11).char32_t: Utilizado para guardar caracteres que ocupam até 32bits (adicionado noC11).
Estes tipos ajudam também a especificar a intenção do código, pois seria possível usar tipos de inteiros para guardar os códigos de caracteres que são maiores ou mesmo usar unsigned char diretamente para caracteres UTF-8.
Já o tipo wchar_t é especialmente útil no Windows, que internamente usa UTF-16 e exige em muitos casos, uso de strings neste padrão, como wchar_t foi incluido antes mesmo do C11, é possível usar versões mais antigas do C com ele.
Literais de caractere
Para escrever caracteres, podemos utilizar :
'A' //Literal de caractere
L'B' //Literal de caractere do tipo wchar_t
u'C' //Literal de caractere do tipo char16_t (adicionado no C11)
U'💻' //Literal de caractere do tipo char32_t (adicionado no C11)
u8'D' //Literal de caractere em UTF-8 (adicionado no C23)
Também é possível escrever literais para múltiplos caracteres, mas o valor efetivo é definido pela implementação.
- Literais de múltiplos caracteres como
'AB'tem tipoint. - Literais largos de múltiplos caracteres como
L'AB'tem tipowchar_t. - Os especificadores
ueUgeralmente não devem ser usados para literais de múltiplos caracteres, pois não são suportados em compiladores como clang e seu suporte foi totalmente removido noC23.
Apesar de literais de múltiplos caracteres serem definidos por implementação, a maioria dos compiladores, exceto o MSVC (compilador da microsoft), implementa como um valor em big endian alinhado para direita, de forma que \1 seja 0x00000001 e \1\2\3\4 seja 0x01020304.
Literais de múltiplos caracteres são comumente utilizados para definir números “mágicos” usados no início de arquivos para identificar unicamente seu tipo, por exemplo imagens em PNG começam com %PNG, Zips com PK, BMPs com BMP.
Inteiros
Números inteiros são um conjunto de tipos de variaveis primitivas, indicam números sem casas decimais que podem ter valores negativos e positivos, ou limitados para apenas números positivos com o modificador unsigned.
A única diferença entre os diferentes tipos de inteiros são as regras para definição do seu tamanho e limites e algumas particularidades exclusivas dos tipos char, signed char e unsigned char que serão explicados em detalhes na seção sobre ponteiros.
Existem vários tipos de números inteiros, sendo eles (em ordem crescente de tamanho) :
charshortintlonglong long (adicionado no C99)
Regras para tamanho de inteiros
No geral o padrão do C não dá muitas garantias quanto aos tamanhos em bytes de inteiros, a única garantia real é que char é 1 byte e que os tipos “maiores” precisam atender a alguns requisitos mínimos.
Na prática a maioria dos sistemas modernos atende aos padrões conhecidos como “modelos de dados” que são os conjuntos de tamanhos de cada variável :
LP32: Utilizado pelo windows 16bits (não é mais tão moderno assim…)ILP32: Utilizado pelo windows 32bits e sistemas UNIX 32bits (Linux,MacOs e afins)LLP64: Utilizado pelo windows 64bitsLP64: Utilizado por sistemas UNIX 64bits (Linux, MacOs e afins)
Com isso é possível montar a tabela abaixo (relacionando a quantidade de bits de cada tipo) :
| Tipo | Padrão C | LP32 | ILP32 | LLP64 | LP64 |
|---|---|---|---|---|---|
char | Pelo menos 8 | 8 | 8 | 8 | 8 |
short | Pelo menos 16 | 16 | 16 | 16 | 16 |
int | Pelo menos 16 | 16 | 16 | 32 | 32 |
long | Pelo menos 32 | 32 | 32 | 32 | 64 |
long long | Pelo menos 64 | 64 | 64 | 64 | 64 |
Se atendo um pouco mais aos detalhes, o padrão do C não obriga 1 byte a ser 8bits, na verdade um byte é o menor valor endereçável da arquitetura, portanto apesar de todas as arquiteturas modernas usarem 8bits por byte, o padrão do C aceita arquiteturas que não seguem isso e expõe a definição CHAR_BIT que indica o número de bits em um byte.
Isso permitiria por exemplo bizarrices como arquiteturas que tem um byte com 64bits, o que possibilitaria que todos os tipos tivessem apenas 1 byte, logo, quanto a bytes a regra a ser seguida pelo C é a seguinte :
1 == sizeof(char) <= sizeof(short) <= sizeof(int) <= sizeof(long) <= sizeof(long long)
Mas mesmo assim, a maioria das pessoas não está preocupada com arquiteturas obscuras que provavelmente nunca vão ver na vida, na prática as arquiteturas modernas e mesmo sistemas embarcados de hoje em dia em sua grande maioria usam 8bits por byte e a representação de complemento de dois para inteiros com sinal.
Limites de inteiros
Constantes relacionadas a limites de inteiros podem ser encontradas na biblioteca limits.h.
Ao assumir complemento de dois para os inteiros com sinal, podemos definir os seguintes limites para os dados :
| Tamanho em bits | Tem sinal | Limite inferior | Limite superior |
|---|---|---|---|
| 8 | Sim | -128 | 127 |
| 16 | Sim | -32768 | 32768 |
| 32 | Sim | -2147483648 | 2147483647 |
| 64 | Sim | -9223372036854775808 | 9223372036854775807 |
| 8 | Não | 0 | 255 |
| 16 | Não | 0 | 65535 |
| 32 | Não | 0 | 4294967295 |
| 64 | Não | 0 | 18446744073709551616 |
Mas e se eu te disser que você não precisa perder seu tempo decorando a tabela acima?
Todos esses valores podem ser facilmente calculados.
Para inteiros sem sinal o limite é :
\[-\frac{2^N}{2} \text{ até } \frac{2^N}{2}-1\]
Enquanto que para inteiros sem sinal, o limite é
\[0 \text{ até } 2^N-1\]
Onde N é o número de bits, logo fica fácil “descobrir” os limites de um tipo inteiro tendo uma calculadora a disposição.
Tipos de tamanho específico
Para facilitar o manuseio de inteiros, existem algumas definições específicas de tipos que estão presentes na biblioteca padrão pela inttypes.h que foi adicionada no C99.
Lá existem definições para inteiros de 8,16,32 e 64bits e suas respectivas versões com ou sem sinal. Utilizar estes tipos garante um tamanho fixo conhecido e facilita o manuseio dos mesmos além de compatibilidade maior com outros compiladores e processadores.
Eu poderia listar todos eles, mas é mais fácil entender a regra dos nomes, considere que pedaços em colchetes [], são opcionais e / são alternativas ao mesmo valor.
[u]int[_fast/_least]X_t
Xé o número de bits, podendo ser 8, 16, 32 ou 64ué o modificador para uma versão sem sinal do tipo_fasté o modificador para obter o tipo “mais eficiente para manuseio” que tenha pelo menos o tamanho especificado_leasté o modificador para obter o menor tipo que tenha “pelo menos aquele tamanho”- Na ausência de
fasteleast, o tipo tem EXATAMENTE a quantidade de bits emX.
Exemplos :
uint8_t: Tipo sem sinal com exatamente 8bitsint_fast32_t: Tipo com sinal com o tipo mais eficiente que tenha pelo menos 32bitsuint_least64_t: Inteiro sem sinal com pelo menos 64bits
Além destes tipos, existe o intmax_t que contêm o maior tipo inteiro com sinal e uintmax_t que contêm o maior tipo inteiro sem sinal.
Tipos inteiros adicionais
Além destes, existem alguns tipos inteiros adicionais presentes nas bibliotecas inttypes.h e stddef.h (incluida junto com stdlib.h).
Estes tipos são :
| Tipo | Descrição |
|---|---|
ptrdiff_t | Tipo resultante ao subtrair dois ponteiros |
size_t | Tipo que pode guardar o tamanho máximo teórico que um array pode ter |
max_align_t | Tipo que com o maior requisito de alinhamento possível (C11) |
intptr_t | Inteiro com sinal capaz de guardar qualquer ponteiro |
uintptr_t | Inteiro sem sinal capaz de guardar qualquer ponteiro |
O tipo size_t é o tipo resultante de toda expressão sizeof, e é o tipo ideal para guardar o tamanho máximo que objetos, arrays ou qualquer dado possa ter.
O tipo ptrdiff_t é utilizado para guardar diferenças entre ponteiros, e pode ser considerado como uma versão com sinal de size_t, visto que o tipo ssize_t normalmente definido e presente em sistemas POSIX não faz parte do padrão do C.
O propósito do POSIX ao utilizar ssize_t é a possibilidade de utilizar os valores negativos para indicar erros, reservando um bit do valor para erros.
max_align_t no geral é utilizado junto com o operador alignof.
Tipo _BitInt
Adicionado apenas no C23, o tipo é declarado como _BitInt(N) onde N é o número de bits que o tipo deve ter com cada valor de N sendo considerado um tipo diferente.
Os tipos _BitInt ainda podem ter o modificador unsigned e para valores com sinal, o número de N inclui o bit de sinal, de forma que _BitInt(1) não seja um tipo válido (pois não sobra nenhum bit pro valor).
A mesma regra descrita nos limites de inteiros se aplicam para calcular os limites de um valor do tipo _BitInt.
Inteiros definidos pela implementação
Desde o C99, existe a possibilidade dos compiladores terem tipos inteiros adicionais adicionados a linguagem, tipos como __uint128 e __int128 que simbolizam inteiros de 128 bits, porém o suporte e existência desses tipos depende da arquitetura e do compilador utilizado.
Overflow e underflow
Ao tratarmos de números inteiros, é comum o uso dos seguintes termos :
overflow: Em tradução literal, seria um “transbordamento”, esse termo é utilizado para indicar quando chegamos em um valor que vai além do limite que uma variável suporta.underflow: Em tradução literal, seria um “subtransbordamento”, esse termo é utilizado para indicar quando chegamos um valor abaixo do limite mínimo que uma variável suporta.
O comportamento padrão para calcularmos o valor resultante quando ocorre overflow ou underflow é :
overflow:VALOR_MAXIMO + Xse tornaráVALOR_MINIMO + (X - 1)paraX > 0underflow:VALOR_MINIMO - Xse tornaráVALOR_MAXIMO - (X - 1)paraX > 0
Para inteiros com sinal, o comportamento de overflow e underflow é indefinido, portanto qualquer checagem como i + 1 < i é transformada em false durante as otimizações, porém na prática quando um overflow ou underflow acontece e usamos complemento de dois (o que é o padrão), temos o comportamento descrito acima.
O teste abaixo demonstra um exemplo ao escrever um overflow e underflow de um inteiro com sinal de 8bits (lembre-se que pelas regras da linguagens, estamos invocando um comportamento indefinido):
#include <stdio.h>
#include <limits.h>
int main()
{
signed char test1 = SCHAR_MAX;
signed char test2 = SCHAR_MIN;
//"%hhd" é o modificador para escrever um signed char no printf
printf("%hhd %hhd\n", test1 + (signed char)1, test2 - (signed char)1);
}
Já para inteiros sem sinal, o overflow e underflow são definidos, e seguem o mesmo comportamento descrito, o que pode ser preocupante pois 0 - 1 gera o valor máximo, logo o perigo de underflow é muito maior. É por esse motivo que alguns autores aconselham evitar o uso de inteiros sem sinal, justamente pela facilidade de gerar um underflow ao realizar subtrações, no qual devemos ter muito cuidado sempre que realizamos subtrações.
Exemplo de overflow e underflow com inteiros sem sinal (neste caso, este comportamento é definido pela linguagem, garantindo que funcione em qualquer lugar):
#include <stdio.h>
#include <limits.h>
int main()
{
unsigned int test1 = UINT_MAX;
unsigned int test2 = 0;
//"%u" é o modificador para escrever um unsigned int no printf
printf("%u %u\n", test1 + 1U, test2 - 1U);
}
Aritmética Verificada
Desde o C23, a biblioteca stdckdint.h, foi adicionada, permitindo uma forma portável de realizar soma, subtração ou multiplicações checando se a operação teve sucesso sem overflow ou underflow através das macros ckd_add, ckd_sub, ckd_mul.
Todas as macros tem a seguinte sintaxe para chamada :
bool ckd_xxx(tipo1 *resultado, tipo2 a, tipo3 b);
Onde tipo1, tipo2 e tipo3 podem ser tipos diferentes, a verificação realizada é se a operação resultante com a e b pode ser guardada em resultado sem overflow/underflow ou truncamento, sendo tipo1 um ponteiro para o tipo guardando o resultado.
Todas as 3 operações funcionam com qualquer tipo inteiro que não seja char, bool, _BitInt(N), ou enum.
Lembrando que antes da existência dessa biblioteca, essas operações eram fornecidas como extensões de compiladores e, inclusive, são geralmente implementadas apontando as macros para as respectivas extensões já existentes.
Além disso a aritmética verificada geralmente é extremamente eficiente em alguns processadores, devido a presença de registradores de flags do processador que guardam se a última operação aritmética resultou em overflow/underflow, de forma que utilizar essas extensões seja absurdamente mais eficiente do que realizar a checagem por conta.
Para código escrito antes do C23, é possível implementar uma biblioteca que fornece a funcionalidade nos principais compiladores de C :
#if defined(__GNUC__) || defined(__clang__)
#define ckd_add(R, A, B) __builtin_add_overflow((A), (B), (R))
#define ckd_sub(R, A, B) __builtin_sub_overflow((A), (B), (R))
#define ckd_mul(R, A, B) __builtin_mul_overflow((A), (B), (R))
#elif defined(_MSC_VER)
//A Microsoft não fornece uma extensão de compilador "equivalente"
//mas tem uma biblioteca que realiza essas operações
//Utiliza a palavra chave _Generic adicionada no C11 para implementar a aritmética checada
#include <intsafe.h>
#define ckd_add(R, A, B) _Generic(*R, \
signed char:Int8Add, \
unsigned char:Uint8Add, \
short:ShortAdd, \
unsigned short:UShortAdd, \
int:IntAdd, \
unsigned int:UIntAdd, \
long:LongAdd, \
unsigned long: ULongAdd, \
long long:LongLongAdd, \
unsigned long long:ULongLongAdd, \
intptr_t:IntPtrAdd, \
size_t:SizeTAdd, \
ssize_t:SSizeTAdd, \
)(A,B,R)
#define ckd_sub(R, A, B) _Generic(*R, \
signed char:Int8Sub, \
unsigned char:Uint8Sub, \
short:ShortSub, \
unsigned short:UShortSub, \
int:IntSub, \
unsigned int:UIntSub, \
long:LongSub, \
unsigned long: ULongSub, \
long long:LongLongSub, \
unsigned long long:ULongLongSub, \
intptr_t:IntPtrSub, \
size_t:SizeTSub, \
ssize_t:SSizeTSub, \
)(A,B,R)
#define ckd_mul(R, A, B) _Generic(*R, \
signed char:Int8Mult, \
unsigned char:Uint8Mult, \
short:ShortMult, \
unsigned short:UShortMult, \
int:IntMult, \
unsigned int:UIntMult, \
long:LongMult, \
unsigned long: ULongMult, \
long long:LongLongMult, \
unsigned long long:ULongLongMult, \
intptr_t:IntPtrMult, \
size_t:SizeTMult, \
ssize_t:SSizeTMult, \
)(A,B,R)
#endif
Dicas para uso consciente de inteiros
No geral, aconselho utilizar signed char e unsigned char para representar bytes, int/unsigned int para inteiros genéricos onde o tamanho não é problema (todas as plataformas modernas tem geralmente um int de pelo menos 32bits, a menos que sejam processadores embarcados de 16/8 bits ou arquiteturas super específicas).
Em casos onde operações com bits ou tamanhos fixos são necessários, os tipos uintx_t e intx_t são utilizados para especificar um tamanho fixo.
O tipo size_t é importante também pois é normalmente utilizado para indicar tamanhos ou um inteiro do maior tamanho suportado nativamente pela plataforma.
Já o tipo ptrdiff_t é mais raro, mas pode ser usado de maneira similar ao ssize_t definido pelo POSIX (um tamanho de arrays/dados que também pode representar erros, utilizado geralmente em retorno de funções) ou realmente para diferenças entre ponteiros.
Booleanos
Booleanos são valores que indicam um estado de Verdadeiro ou Falso.
No geral ao ler valores booleanos :
Falsoindica um valor igual a zeroVerdadeiroindica um valor diferente de zero
Porém como já foi descrito nos operadores booleanos :
- Expressões booleanas que resultam em
Falsotem o valor 0 - Expressões booleanas que resultam em
Verdadeirotem o valor 1
Logo, é comum termos em programas TRUE (Verdadeiro em inglês) como 1 ou FALSE (Falso em inglês) como 0.
Porém isso nos leva a um dilema, antes do C99, não existia nenhum tipo booleano, logo booleanos eram representados com tipos númericos como int ou unsigned char.
Ocasionando em problemas como o deste exemplo :
#include <stdio.h>
#define TRUE 1 //Verdadeiro em inglês
#define FALSE 0 //Falso em inglês
void testaValor(unsigned char booleana)
{
if(booleana == TRUE)
puts("O valor é verdadeiro");
else
puts("O valor é falso");
}
void testaValor2(unsigned char booleana)
{
if(booleana)
puts("O valor é verdadeiro");
else
puts("O valor é falso");
}
int main() {
unsigned char valor = 5;
testaValor(valor); //Imprime "O valor é falso"
testaValor2(valor); //Imprime "O valor é verdadeiro"
}
Perceba que neste exemplo, duas checagens diferentes reportaram um estado diferente, pois ao checar sem usar comparadores, tivemos o resultado de que valor era Verdadeiro, o que está correto.
Porém ao utilizar a clássica comparação valor == TRUE, como TRUE é apenas uma definição para 1, e valor é 5, por serem números diferentes, o resultado é Falso.
Com este dilema, percebemos que algo que seria extremamente natural em linguagens de alto nível, se tornou um problema sutil, que exigiria cuidados extras ao manusear valores booleanos e que possivelmente seria de difícil detecção.
O tipo booleano
Para resolver este problema o C99 definiu o tipo _Bool e a biblioteca stdbool.h, o conteúdo da stdbool.h é tão pequeno que pode ser escrito aqui :
#if defined __STDC_VERSION__ && __STDC_VERSION__ > 201710L //Checagem para C23
/* bool, true e false são palavras chave da linguagem. */
#else
#define bool _Bool
#define true 1
#define false 0
#endif
O tipo _Bool pode receber qualquer valor, porém ao guardar o valor, ele é automáticamente convertido para 0 ou 1 seguindo a regra de leitura de valores booleanos, permitindo comparações como valor == true sejam verdadeiras mesmo que o valor tenha sido obtido ao executar valor = 5.
Além disso, algumas conversões implicitas para o tipo bool ou _Bool são diferentes das conversões utilizadas para o tipo int :
bool b1 = 0.3; // b1 == 1 (0.3 convertido para int é 0)
bool b2 = 2.0*_Imaginary_I; // b2 == 1 (mas convertido para int é 0)
bool b3 = 0.0 + 3.0*I; // b3 == 1 (mas convertido para int é 0)
O ideal é sempre acessar o tipo utilizando o stdbool.h e as macros de true e false definidas nele, visto que no C23, bool se tornou um tipo único da linguagem, enquanto true e false se tornaram palavras chaves nativas da linguagem.
Ponto Flutuante
Variáveis de ponto flutuante são tipos utilizados para representar números reais, que podem ter casas depois da virgula, ou mesmo para representar números extremamente grandes.
Os tipos padrões de ponto flutuantes existentes são:
float: Ponto flutuante de precisão única.double: Ponto flutuante de precisão dupla.long double: Ponto flutuante de precisão extendida.
Geralmente os números de ponto flutuante obedecem os formatos definidos pelo padrão IEEE-754, apesar de isso não ser garantido pela especificação do C.
Logo o tipo float geralmente tem 32bits e obedece o formato IEEE 754 binary32.
O tipo double geralmente tem 64bits e obedece o formato IEEE 754 binary64.
Já o tipo long double geralmente utiliza um dos seguintes formatos :
No geral as implementações na arquitetura x86 e x86-64 normalmente utilizada em PCs, tendem a utilizar o formato binary64 extendido que tem 80bits suportado nativamente pelo processador, porém alguns compiladores já utilizam o formato binary128.
O compilador da microsoft MSVC, é uma exceção a regra, no qual ele implementa mesmo em x86 e x86-64, long double como binary64 tendo a mesma representação de double.
Além disso, como é a microsoft quem escreve os runtimes padrões do C para windows, geralmente funções como printf vão levar em consideração que long double é 64bits (assim como no MSVC), de forma que nenhum tipo long double seja corretamente escrito quando usado em outros compiladores no windows, exigindo o uso de definições como __USE_MINGW_ANSI_STDIO que forçam o compilador a utilizar suas próprias implementações dessas funções.
Já processadores ARM (utilizados normalmente em celulares e embarcados), geralmente usam o formato binary64 em suas versões 32bits e o formato binary128 nas suas versões 64bits.
Limites dos ponto flutuantes
A seguir, veremos os limites de cada formato de ponto flutuante.
O campo “Maior inteiro” é utilizado para indicar o maior número inteiro que pode ser representado sem utilizar aproximações.
Lembrando que todos os formatos podem representar os mesmos valores com sinal positivos ou negativo, de forma que os limites “inferiores” e “superiores” descritos se refiram ao menor valor positivo e maior valor positivo respectivamente.
O binary64 extendido e o binary128 tem a mesma quantidade de bits reservadas para o expoente, de forma que o range do binary64 extendido seja o mesmo, mas a precisão seja menor.
binary32- Limite inferior : \(1.40129846432481707092372958328991613 * 10{-45}\)
- Limite superior : \(3.40282346638528859811704183484516925 * 10{38}\)
- Maior inteiro : \(2^{24}-1\)
binary64- Limite inferior : \(4.94065645841246544176568792868221372 * 10{-324}\)
- Limite superior : \(1.79769313486231570814527423731704357 * 10{308}\)
- Maior inteiro : \(2^{53} -1\)
binary64 extendido- Limite inferior : \(3.64519953188247460252840593361941982 * 10^{-4951}\)
- Limite superior : \(1.18973149535723176502126385303097021 * 10^{4932}\)
- Maior inteiro : \(2^{64} - 1\)
binary128- Limite inferior : \(3.64519953188247460252840593361941982 * 10^{-4951}\)
- Limite superior : \(1.18973149535723176502126385303097021 * 10^{4932}\)
- Maior inteiro : \(2^{113} - 1\)
Entendendo os limites
Mas agora a pergunta que não quer calar é… como os ponto flutuantes conseguem ter uma faixa tão grande de valores, mesmo tendo uma quantidade de bits similar a inteiros que representam faixas bem menores?
Assumindo o padrão dos formatos do IEEE 754, a verdade é que eles guardam bits separados para sinal, expoente e número, de forma que alguns valores não possam exatamente serem representados com precisão.
Ou seja, para vários números os tipos de ponto flutuante oferecem uma aproximação, inclusive o campo de “Maior inteiro” da seção anterior buscava mostrar o maior valor representável sem aproximações.
O resultado disso na prática é que existem clássicos exemplos de como essas aproximações podem dar errado ou nos levar a erros.
Por exemplo, o código a seguir :
#include <stdio.h>
#include <stdbool.h>
int main()
{
bool resultado = (0.1 + 0.2) == 0.3;
if(resultado)
puts("O resultado é verdadeiro");
else
puts("O resultado é falso");
}
Talvez você fique surpreso em descobrir que o resultado deste programa é :
O resultado é falso
A forma recomendada para indicar que dois números de ponto flutuante são iguais é :
#include <stdbool.h>
#include <float.h>
bool mesmoNumero(double a, double b)
{
if(a == b)
return true;
return (fabs(a-b) <= DBL_EPSILON);
}
int main()
{
bool resultado = mesmoNumero(0.1 + 0.2, 0.3);
if(resultado)
puts("O resultado é verdadeiro");
else
puts("O resultado é falso");
}
Neste caso o resultado é :
O resultado é verdadeiro
A constante definida como DBL_EPSILON ou FLT_EPSILON indica a menor diferença entre 1 e o valor após 1 que é representável, porém essa diferença não é exatamente a diferença mínima entre dois números quaisquer pois ela pode variar um pouco de acordo com o expoente atual.
Geralmente implementações mais avançadas da comparação costumam passar um EPSILON diferente dependendo da faixa de valores que será usada em cada caso.
Valores especiais para ponto flutuante
Os tipos de ponto flutuante tem alguns valores especiais, que podem indicar estados de erro e de operações que normalmente seriam tratadas como exceções.
- Infinito : A macro
INFINITY(que pode ter um valor positivo ou negativo e é definida emmath.h), geralmente é o resultado ao realizar divisões por zero. - 0 negativo : O valor
-0.0é geralmente suportado, a expressão-0.0 == 0éVerdadeira, mas5 / -0.0gera o valor equivalente a-INFINITYpor exemplo. - Não é um número: Geralmente conhecido como
NaN, pode ter várias representações, mas basicamente indica que o número é indefinido/inválido e todas as operações aritméticas envolvendo ele devem resultar emNaNtambém. Além disso oNaNtambém obrigatóriamente deve gerarFalsoquando comparado com ele mesmo, sendo uma forma possível de identificar se o valor éNaN.
Erros de ponto flutuante
Operações de ponto flutuante e funções envolvendo ponto flutuante geralmente reportam erros envolvendo operações (overflow, underflow, divisão por zero, valor inválido, resulto inexato, erro de faixa, etc).
A biblioteca math.h oferece a definição math_errhandling (que por algum motivo, não é suportada no windows), que indica as formas como erros são reportados em um bitmask :
MATH_ERRNO: Tem o valor1, se este bit emmath_errhandlingestiver definido, significa que erros de ponto flutuante e funções relacionadas a elas são reportadas através doerrno, que é uma variável local do thread que indica o código do último erro ocorrido.MATH_ERREXCEPT: Tem o valor2, se este bit emmath_errhandlingestiver definido, significa que erros de ponto flutuante e funções relacionadas a elas são reportadas ao chamarfetestexcepte podem ser limpas ao chamarfeclearexcept.
Lembrando que ambos modos podem ser utilizados para reportar erros, sendo necessário checar.
No geral compiladores no windows não fornecem implementação dessas macros, mas usa o modo definido por MATH_ERREXCEPT.
Uma sugestão para compatibilidade no windows sugere utilizar o seguinte código :
#include <math.h>
#if !defined(MATH_ERRNO)
# define MATH_ERRNO 1
#endif
#if !defined(MATH_ERREXCEPT)
# define MATH_ERREXCEPT 2
#endif
#if !defined(math_errhandling)
# define math_errhandling MATH_ERREXCEPT
#endif
Código exemplo testando exceções :
#include <errno.h>
#include <fenv.h>
#include <math.h>
#include <stdio.h>
#include <float.h>
void testarErrno()
{
if(errno == EDOM)
puts("Valor inválido");
else if(errno == ERANGE)
puts("Valor fora da faixa");
errno = 0; //Limpa o errno para o próximo uso
}
void testarExcecoes()
{
if(fetestexcept(FE_INVALID)) puts("Operação inválida");
if(fetestexcept(FE_DIVBYZERO)) puts("Divisão por zero");
if(fetestexcept(FE_OVERFLOW)) puts("Overflow");
if(fetestexcept(FE_UNDERFLOW)) puts("Underflow");
if(fetestexcept(FE_INEXACT)) puts("Resultado inexato");
//Limpa as exceções, evitando reportar duas vezes
feclearexcept(FE_ALL_EXCEPT);
}
void checaErrosPontoFlutuante(const char *texto)
{
puts(texto);
if(math_errhandling & MATH_ERREXCEPT)
testarExcecoes();
else if(math_errhandling & MATH_ERRNO)
testarErrno();
}
int main()
{
double test;
errno = 0; //Garante que errno está limpo
test = 0.0 / 0.0;
checaErrosPontoFlutuante("1 - 0/0");
test = 5.0 / -0.0;
checaErrosPontoFlutuante("2 - 5/-0");
test = 2 * DBL_MAX;
checaErrosPontoFlutuante("3 - 2 * MAXIMO");
test = DBL_TRUE_MIN / 2;
checaErrosPontoFlutuante("4 - MINIMO / 2");
test = sqrt(2);
checaErrosPontoFlutuante("5 - Raiz de 2");
}
Um teste no windows resultou no seguinte (foi necessário adicionar o código de sugerido para compatibilidade):
1 - 0/0
Operação inválida
2 - 5/-0
Divisão por zero
3 - 2 * MAXIMO
Overflow
Resultado inexato
4 - MINIMO / 2
5 - Raiz de 2
Tipos extras de ponto flutuante
Nos casos onde há uma FPU (Floating Point Unit), uma unidade dedicada para processamento de números de ponto flutuante dentro do processador, é possível que a precisão de certos tipos de ponto flutuante seja menor do que a precisão oferecida nativamente pelo hardware para realizar os cálculos.
Nesses casos, utilizar os tipos de maior precisão suportados em hardware para realizar os cálculos é mais eficiente, além de, claro, ser mais preciso.
Para isso, foram criadas novas definições de tipos de ponto flutuante na biblioteca math.h, aconselháveis para variáveis que guardem cálculos intermediários utilizados para produzir um valor final do tipo indicado :
float_t, como o tipo mais eficiente que tem pelo menos o tamanho defloatdouble_t, como o tipo mais eficiente que tem pelo menos o tamanho dedouble
Alguns detalhes adicionais sobre a implementação são evidenciados pelos diferentes valores da macro FLT_EVAL_METHOD :
0:float_tedouble_tsão equivalentes afloatedoublerespectivamente1:float_tedouble_tsão equivalentes adouble2:float_tedouble_tsão equivalentes along doubleoutro: o formato defloat_tedouble_tsão definidos pela implementação
Números complexos e imaginários
Desde o C99, foram adicionados números complexos a linguagem, que devem ser, idealmente, acessados adicionando a biblioteca complex.h, pois algumas das funcionalidades dependem de macros do complex.h que podem incluir extensões de compilador (de forma que incluir complex.h seja a forma mais portável).
Os números complexos são acessados através do modificador complex que deve ser escrito após o tipo de ponto flutuante (ex: double complex ou float complex) e literais de números imaginários podem ser escritos utilizando a macro I.
Tipos de variáveis para números imaginários podem ser escritos utilizando o modificador imaginary da mesma forma que complex.
A biblioteca complex.h também oferece algumas funções para operar com números imaginários e complexos e o printf apresenta formatadores para realizar a formatação de tais números.
Uma implementação também pode se recusar a fornecer suporte a números imaginários, neste caso indica-se:
- Antes do
C11: A definição de__STDC_IEC_559_COMPLEX__é recomendada para indicar que a implementação suporta números imaginários, mas não obrigatória, o POSIX recomenda checar se_Imaginary_Iestá definido para identificar suporte a números complexos C11: Números imaginários são suportados se__STDC_IEC_559_COMPLEX__estiver definidoC23: Números imaginários são suportados se__STDC_IEC_60559_COMPLEX__estiver definido
Números decimais
Adicionados no C23, os números decimais são números de ponto flutuante com precisão decimal que seguem os formatos especificados pela IEEE 754.
Nele temos os tipos
_Decimal32: Segue o formatodecimal32da IEEE 754_Decimal64: Segue o formatodecimal64da IEEE 754_Decimal128: Segue o formatodecimal128da IEEE 754
Os valores obedecem aos seguintes limites :
decimal32- Limite mínimo : \(±1.000000 * 10^{−95}\)
- Limite máximo : \(±9.999999 * 10^{96}\)
- Precisão: até 7 digitos.
decimal64- Limite mínimo : \(±1.000000000000000 * 10^{−383}\)
- Limite máximo : \(±9.999999999999999 * 10^{384}\)
- Precisão: até 16 digitos.
decimal128- Limite mínimo : \(±0.000000000000000000000000000000000 * 10^{−6143}\)
- Limite máximo : \(±9.999999999999999999999999999999999 * 10^{6144}\)
- Precisão: até 34 digitos.
O suporte a tipos decimais pode ser checado verificando a definição de __STDC_IEC_60559_DFP__.
Controle de fluxo
Normalmente quando executamos programas, a execução percorre linha a linha, ou sendo mais preciso, a execução percorre “statement” por “statement”.
Statement, em tradução literal é uma “declaração”, é simplesmente um comando finalizado por ;, e que não necessáriamente precisa estar em uma linha.
#include <stdio.h>
int main()
{
int x, y, z;
//Vários statements em uma única linha
x = 10; y = 15; z = 20;
//Um statement em múltiplas linhas
printf(
"x = %d\n"
"y = %d\n"
"z = %d\n",
x,y,z
);
}
Este fluxo delimitado por statements sequenciais pode ser desviado e modificado condicionalmente, ao utilizarmos palavras chaves para controle de fluxo.
Laços de repetição também são uma forma de controle de fluxo, porém serão melhor explicados na página seguinte.
If
A palavra chave if, no português “se”, é utilizada para desviar o fluxo de execução caso a condição especificada não seja atendida.
Também podemos dizer isso de outra forma, que o if é utilizado para executar uma parcela de código quando uma condição é atendida.
A sintaxe para escrita é if(CONDIÇÃO), onde CONDIÇÃO é uma expressão qualquer que será avaliada como uma expressão booleana, de forma que valores iguais a 0 sejam Falso e valores diferentes de 0 sejam Verdadeiros.
Exemplo usando if :
#include <stdio.h>
#include <stdlib.h>
int main(int argc, char **argv)
{
char linha[1024];
printf("Escreva um número:");
fgets(linha, sizeof(linha), stdin);
int valor = (int)strtol(linha, NULL, 10);
if(valor > 100)
puts("Escreveu um valor maior que 100");
else
puts("Escreveu um valor que não é maior que 100");
}
No geral quando utilizamos if ou qualquer outra palavra chave de controle de fluxo, podemos colocar blocos {} para especificar múltiplos statements ao invés de apenas um.
Como por exemplo :
if(temCafe) {
prepararCafe();
gritarQueTemCafe();
beberCafe();
} else {
prepararParaApocalipse();
}
Else e Elseif
As palavras chaves else e else if são utilizadas em conjunto com if e outros else if, de forma que seja possível descrever um fluxo alternativo caso a condição anterior não tenha sido Verdadeira.
A palavra else poderia ser traduzida literalmente para “se não”, indicando uma outra abordagem caso a checagem anterior tenha “falhado”.
A palavra chave else é utilizada para delimitar um código que será executado caso todas as condições anteriores em sequência tenham resultado em Falso.
A palavra chave else if é utilizada para executar condicionalmente um código assim como o if, mas que só será avaliada caso todas as condições anteriores em sequência tenham resultado em Falso.
Exemplo utilizando if, else if e else :
if(idade < 3) {
puts("Bebê");
} else if(idade < 12) {
puts("Criança");
} else if(idade < 18) {
puts("Adolescente");
} else if(idade < 30) {
puts("Jovem adulto");
} else if(idade < 65) {
puts("Adulto");
} else {
puts("Idoso");
}
Switch
A palavra chave switch é utilizada para realizar um controle de fluxo condicional para valores especificos de uma variável, geralmente utilizado em conjunto com constantes e enumerações.
Para cada valor que deseja-se checar, utilizamos a palavra chave case, escrevendo case valor:.
Também podemos escrever default: para indicar um código que será executado caso o valor da variável avaliada não seja nenhum dos cases listados, funcionado de maneira similar a palavra chave else.
switch(valor) {
case 1:
case 2:
case 3:
puts("1,2 ou 3");
break;
case 4:
puts("4");
break;
case 5:
puts("5");
break;
default:
puts("Menor que 1 e maior que 5");
break;
}
Percebeu que no exemplo acima, foi usada a palavra chave break também?
Isso foi necessário pois cada case de um switch também apresenta um comportamento que chamamos em inglês de “fallthrough”, que em português seria simplesmente “queda”, pois logo após executar o código em um case, os códigos de outros cases escritos logo após ele, são executados.
Porém ao escrevermos break forçamos o código a sair do switch, evitando que isso aconteça.
Isso ocorre pois em alguns casos é útil termos código que pula para um ponto especifico, mas continua a executar a partir dele, apesar de ser incomum.
Pode acontecer do programador simplesmente esquecer de colocar break, portanto a maioria dos compiladores emite um aviso quando um “fallthrough” pode acontecer em um switch, oferecendo geralmente como extensão de compilador, algum comando para indicar quando um fallthrough é intencional.
Desde o C23 podemos escrever [[falthrough]] para indicar que um fallthrough é intencional, tornando o que antes era uma extensão especifica de compilador que deveria ser escrita de uma forma diferente para cada um, algo padronizado na linguagem.
Exemplo de switch utilizando fallthrough :
//A ideia aqui é listar tudo que pode ser feito em cada nível de acesso
switch(nivelDeAcesso) {
case 3:
puts("Você pode acessar as salas confidenciais");
case 2:
puts("Você pode acessar as salas dos gerentes e cargos de chefia");
case 1:
puts("Você pode acessar a sala dos funcionários");
case 0:
puts("Você pode acessar a sala dos convidados");
break;
default:
puts("Nível de acesso desconhecido");
}
No exemplo acima, temos um caso de fallthrough intencional, onde o nível de acesso mais alto também tem os privilegios menores e portanto devem ser listados também.
O resultado do código acima ao definir nivelDeAcesso para 3 é :
Você pode acessar as salas confidenciais
Você pode acessar as salas dos gerentes e cargos de chefia
Você pode acessar a sala dos funcionários
Você pode acessar a sala dos convidados
Lembrando que os valores em cada caso do switch precisam ser constantes de compilação, logo só podem ser definidos em enumerações, variaveis constexpr e definições de preprocessador (#define).
Goto
Agora temos a palavra chave de controle de fluxo mais controversa de todas, o temido goto.
O goto, no português “vá para”, oferece uma possibilidade de realizarmos saltos indiscriminados do fluxo de execução, se assemelhando a forma como as próprias instruções dos processadores implementam o controle de fluxo.
Para poder realizar um salto com goto, é necessário escrever um “label” (em português, seria rótulo) nomeDoLabel: em qualquer lugar do código, e ao chamar goto nomeDoLabel, a execução do código “salta” para o local onde o label foi escrito.
Um exemplo simples de código utilizando goto :
#include <stdio.h>
#include <stdlib.h>
int lerNumero(const char *mensagem)
{
char linha[1024];
printf(mensagem);
fgets(linha, sizeof(linha), stdin);
return (int) strtol(linha, NULL, 10);
}
int main(int argc, char **argv)
{
puts("== Calculadora de multiplicação ==");
int valor1 = lerNumero("Escreva um número maior que 0:");
if(valor <= 0)
goto sair;
int valor2 = lerNumero("Escreva outro número maior que 0:");
if(valor2 <= 0)
goto sair;
printf("%d x %d = %d\n", valor1, valor2, valor1 * valor2);
sair:
puts("Estou saindo");
}
No exemplo acima, o goto foi utilizado para executar um código em comum na finalização do programa, apesar de existirem outras formas de realizar a mesma coisa, neste caso, utilizar goto é uma das formas mais simples.
Sobre o uso de goto
O goto é ideal nos casos onde há tratamento de erros, necessidade de executar um código em comum na finalização, sair de vários loops aninhados e talvez em alguns outros usos especificos que não saberei citar aqui, inclusive vários projetos de renome como o próprio kernel do Linux usam goto extensivamente pelos propósitos citados aqui.
Porém, muitos professores de faculdade ou de cursos técnicos tem uma tendência a dizer fortemente “Não usem goto”, como se isso fosse uma regra que deve ser seguida sempre e por todos, inclusive muitos chegam a descontar nota caso descubram que “o aluno usou goto no programa”.
A motivação é clara, normalmente ao analisar um programa, basta ver as chaves, identação, e facilmente podemos visualizar o fluxo de um programa, porém a possibilidade de utilizar goto pode contrariar isso, ainda mais se o usarmos de forma indiscriminada e colocarmos gotos que voltam linhas de código, pulam inicialização de variaveis, etc.
Porém um uso consciente de goto não prejudica a legibilidade e pode ser uma solução muito mais simples para vários problemas, considere-o como apenas mais uma ferramenta.
Minha dica é sempre pense com cuidado as possibilidades ao escrever um código e evite cair em falácias como “nunca use isso” , “nunca faça aquilo” sem nem mesmo pensar sobre.
Ao escrever labels de
goto, busque escrever nomes simples e fáceis de entender que exemplifiquem a motivação do pulo ou a ocasião em que ele ocorre.
Laços de repetição
Laços de repetição são formas de controlar o fluxo de execução, de forma que uma parcela de código possa ser executada novamente, é muito comum que as pessoas se refiram a eles pelo nome inglês “loop”.
Ao aliar laços de repetição com a modificação de variaveis, podemos efetivamente ter um comportamento diferente mesmo repetindo os mesmos comandos.
Da mesma forma que o if, as palavras chave while, do while e for, podem executar um único statement sem a necessidade de usar chaves ({}) ou vários statements ao colocar eles entre chaves.
Controle de fluxo dos laços de repetição
Ao executar laços de repetição, existem duas palavras chave usadas para controlar o fluxo em um laço.
Uma delas é o break, no português “quebrar”, usada para sair do laço de repetição forçadamente.
A segunda é o continue, no português “continuar”, usada para pular para a próxima iteração.
O termo iteração se refere a uma das execuções da repetição, de forma que executar 3 vezes o conteúdo de um loop sejam “3 iterações”, ou acessar todos elementos de uma lista em um laço de repetição seja normalmente dito como “iterar uma lista”.
While
A palavra chave while, no português “enquanto”, é de certa forma similar ao if, porém ao final de cada execução, o fluxo de execução novamente volta a antes da condição ser checada.
Portanto, o while repete a execução do código enquanto sua condição for Verdadeira, e a condição é avaliada uma vez por iteração.
Abaixo um programa que calcula tabuada, usando while :
#include <stdlib.h>
#include <stdio.h>
int lerNumero(const char *texto)
{
char linha[1024];
fgets(linha, sizeof(linha), stdin);
return (int) strtol(linha, NULL, 10);
}
int main()
{
int valor = lerNumero("Digite um número de 1 a 10:");
if(valor < 1 || valor > 10) {
puts("Digitou um valor inválido");
return 1; //Finaliza o programa
}
int n = 1;
while(n <= 10) {
printf("%d x %d = %d\n", valor, n, valor * n);
n++;
}
}
Lembrando que é possível realizar um laço de repetição infinito utilizando while(1) por exemplo, nesses casos o normal é que haja uma condição com break para sair do loop.
Do While
O do while é bastante similar ao while, a diferença é que a condição do laço é checada no final, sendo mais eficiente/ideal para casos onde a condição naturalmente se encaixa no fim.
A ordem para escrita do do while é do conteudo while(condição), de forma que do x++; while(x < 10); seja uma forma válida para escrever, mas o mais comum é usando chaves no lugar do conteudo.
Exemplo de uso do do while :
#include <stdio.h>
int main()
{
int i = 0;
do {
printf("%d\n", i);
i++;
} while (i < 5);
}
For
A palavra chave for, no português “para”, é normalmente utilizada para iterar sobre listas, arrays, strings (textos), etc.
Porém o for é separado em 3 campos:
for(pre-execução; condição; pós-iteração)
- O campo de pre-execução, que pode ser vazio, inclui um único statement que é executado antes de checar o campo
condiçãopela primeira vez, ele também pode conter uma declaração de variável (que só vai existir dentro dofor). - O campo de condição, é similar ao campo de condição de um
while, porém quando este campo está vazio, considera-se um loop infinito (similar awhile(1)). - O campo da pós-iteração, que pode ser vazio, é um único statement (que não deve ter
;) que é executado após cada iteração do laço, geralmente utilizado para modificar alguma variável usada dentro do laço.
Lembrando que no for, os statements não devem ter ;, e o ; é meramente o separador entre os campos e deve estar incluso, mesmo se o campo estiver vazio.
Dessa forma, um loop infinito com for pode ser feito utilizando for(;;).
Exemplo do laço de repetição for usado para escrever todos valores de um array :
//Esta é uma "macro" que calcula o tamanho do array
#define ARRAY_SIZE(X) (sizeof(X)/sizeof(*X))
int main()
{
//Este é um array, uma variável que indica uma lista de valores sequenciais
//Vamos falar mais sobre ele mais tarde
int numeros[5] = {53,37,84,28,39};
//É muito comum o uso do nome "i" para criar um indice ao iterar
//sobre arrays, o padrão (criar indice; checar faixa; incrementar) é muito comum
for(int i = 0; i < ARRAY_SIZE(numeros); i++) {
printf("%d\n", numeros[i]);
}
}
Funções
Funções são parcelas de código “reutilizável”, escritas para que possamos dar um nome a um pedaço de código e reutilzá-lo em diversas situações, possívelmente com parâmetros diferentes.
As principais vantagens ao utilizar funções são :
- Reutilização de código
- Organização do código por meio de nomes bem definidos
- Possibilidade de parametrizar um código
- Diminuição de dependências externas
Funções são declaradas utilizando a sintaxe tipoRetorno NomeFunção(parametros) :
tipoRetornoindica o tipo do valor resultante de uma função, que pode ser atribuido a uma variável ou usado em outras expressões, podemos escrevervoidpara indicar que a função não resulta em um valor.NomeFunçãoé o nome dado a função, utilizado ao chamarparametrossão os parâmetros que devem ser repassados ao chamar a função, é uma lista com a definição de zero ou mais variaveis, separadas por virgula.
Para retornar um valor em uma função é utilizado o operador return, ele finaliza a execução da função, similar a forma como o operador break finaliza um laço de repetição.
Porém ao finalizar uma função que resulta em um valor, é necessário informar o valor ao escrever return e o uso da palavra chave return em funções assim é obrigatório (todos os caminhos devem ter um retorno).
Exemplos de funções :
#include <stdio.h>
#include <stdlib.h>
#include <math.h>
//realiza a soma de dois números, retornando a soma
int soma(int v1, int v2)
{
return v1 + v2;
}
/* Em muitos casos, quando queremos retornar mais de um valor,
utilizamos um "parâmetro como ponteiro" para retornar valores
adicionais, neste caso temos uma função bhaskara que retorna se
a operação deu certo, e preenche x1 e x2 que são passados via ponteiro */
bool bhaskara(double a, double b, double c,
double *restrict x1, double *restrict x2)
{
const double delta = b*b - 4*a*c;
//Raiz de número negativo é um número imaginário!
if(delta < 0)
return false;
const double raizDelta = sqrt(delta);
if(x1 != NULL)
*x1 = (-b + raizDelta) / (2 * a);
if(x2 != NULL)
*x2 = (-b - raizDelta) / (2 * a);
return true;
}
//Função main testando ambas
int main()
{
int resultado1 = soma(2,3); //5
printf("A soma resultou em %d\n", resultado1);
double r1;
double r2;
if(bhaskara(2, -3, -5, &r1, &r2))
printf("Bhaskara resultou em %.2f e %.2f\n", r1, r2);
else
printf("Bhaskara deu negativo!\n");
}
Também é importante mencionar que desde o C99, é possível acessar o nome da função atual utilizando a macro __func__, que é tratado como uma variável constante e de duração estática (que claramente só será incluida na memória do programa se for utilizada).
Ponto de entrada
Em todas as aplicações feitas em C, exceto as que não usam o ambiente de execução padrão do C, precisam escrever uma função especial denominada main.
O main é o chamado “ponto de entrada” do programa, é onde o seu programa em C começa a executar.
Existem duas formas “padronizadas” de escrever o ponto de entrada.
A primeira, sem parâmetros :
int main() { /* conteúdo */ }
A segunda, que recebe :
argc, indica a quantidade de argumentos da linha de comandoargv, uma lista com os argumentos da linha de comando
int main(int argc, char *argv[]) {/* conteúdo */}
Os argumentos da linha de comando são os valores repassados a um programa quando ele inicia.
Quando iniciamos um programa pelo terminal, a linha de texto do comando utilizado para chamar o programa é enviada ao programa e cada argumento separado por espaço vira um elemento diferente de argv e a quantia de argumentos é repassada através de argc.
Historicamente o primeiro argumento da linha de comando de um programa é o caminho do arquivo utilizado para chamar o programa.
Porém, apesar dessa regra ser seguida no geral pelos terminais de qualquer sistema operacional, vale lembrar que isso não é totalmente garantido.
Qualquer programa pode diretamente chamar as funções de baixo nível para iniciar um processo diretamente como a CreateProcessW no windows, execve no linux ou posix_spawn presente no linux e implementada como chamada de sistema no macOs.
Ao chamar essas funções diretamente, é possível ignorar essa convenção histórica, o que apesar de incomum, é uma possibilidade.
Por exemplo ao executar um programa escrevendo o seguinte :
programa teste.txt -t 50
Teremos argc = 4 e os valores de argv serão:
argv[0] = "programa"
argv[1] = "teste.txt"
argv[2] = "-t"
argv[3] = "50"
Retorno da função main
A função main retorna um valor do tipo int que indica um status de finalização que é retornado ao sistema operacional.
Retornar da primeira chamada da função main é equivalente a chamar a função exit, onde o retorno do main será o código de status repassado ao sistema.
Para indicar uma execução bem sucedida, usa-se o valor 0 ou a macro EXIT_SUCCESS definida na stdlib.h.
Para indicar um erro ou falha na execução, usa-se um valor diferente de 0, geralmente positivo ou a macro EXIT_FAILURE definida também na stdlib.h.
Esses códigos de status podem ser acessados pelo terminal diretamente após executar um programa utilizando a variável %errorlevel% no Windows ou $? no bash em linux ou macOs.
Podemos fazer um programa que justamente testa isso :
#include <stdlib.h>
//Converte o texto do primeiro argumento em inteiro e retorna ele no main
//De forma que o código de status do sistema seja igual ao número passado de argumento
int main(int argc, char **argv)
{
return (argc > 1) ? (int) strtol(argv[1]) : EXIT_SUCCESS;
}
Para testar no windows :
testaerro.exe 5
echo %errorlevel%
Para testar no linux ou macOs :
./testaerro 5
echo $?
Também é importante lembrar que desde o C99, não é necessário escrever return na função main, pois a ausência de return indica que o valor retornado será 0 (só se aplica ao main).
Declaração de funções
Se uma função é definida no C, ela geralmente deve ser definida antes da função que a utiliza, sem isso, compilar o programa resulta em um erro de compilação.
Porém, existe uma forma de burlar isso, declarando a função sem definir ou implementar ela, esse tipo de declaração também é chamado como uma declaração de um “protótipo de função”.
Exemplo :
//Declaração, a forma como a função é
int soma(int v1, int v2);
int main()
{
printf("1 + 2 = %d\n", soma(1,2));
}
//Definição, escreve a implementação da função
int soma(int v1, int v2)
{
return v1 + v2;
}
Quando declaramos uma função, estamos especificando como a função deve ser chamada e quais parâmetros ela deve receber, logo toda informação relevante para chamar a função está presente.
Mas a explicação real do que realmente acontece quando declaramos uma função é um pouco mais complexa.
Ao declarar uma função, estamos basicamente dizendo ao compilador “confia em mim, essa função claramente existe”, o compilador, por sua vez, decide acreditar em você até os últimos momentos.
Mesmo se a função não existir, a etapa de compilação que compila o código de uma unidade de tradução ainda vai funcionar, e seu código é compilado indicando que ele tem uma dependência em uma função com aquele nome.
O problema real ocorre quando chegamos a última etapa, a junção de todos os códigos compilados de todas as unidades de tradução, é neste momento que o compilador checa se a função que você queria existe em algum lugar, se não existir, teremos o erro undefined reference (referência indefinida), que indica que algo que deveria estar lá, na verdade não está.
Isso significa na prática que uma declaração de função também é uma forma de importar funções externas, declarando que ela existe no seu código.
Por exemplo o seguinte código funciona apenas se compilarmos ambos arquivos juntos :
//Arquivo1.c
#include <stdio.h>
void dizerOi()
{
puts("Ola mundo!");
}
//Fim do arquivo1.c
//Arquivo2.c
void dizerOi();
int main()
{
dizerOi();
}
//Fim do arquivo2.c
No exemplo acima, o código no arquivo2.c importa a função presente no arquivo1.c e a chama, se compilarmos apenas arquivo1.c teremos um código que carece da função main e se compilarmos apenas arquivo2.c teremos um erro de undefined reference.
De forma que esse código só funcione se ambos forem compilados juntos.
Diferença entre f() e f(void)
Até antes do C23, declarar uma função com f() é diferente de declarar uma função como f(void), f() representa uma função que aceita um número qualquer de argumentos enquanto f(void) representa uma função que não aceita argumentos.
Lembrando que esses detalhes só servem para a DECLARAÇÃO da função, mas na DEFINIÇÃO, f() ainda representa uma função que não aceita argumentos.
O código abaixo exemplifica isso:
void f(); //Declaração, aceita qualquer número de argumentos
f(2); //Permitido
void f(void); //Declaração, não aceita argumentos
f(2); //Erro de compilação
//Definição, não aceita argumentos
void f() {
}
//Definição, também não aceita argumentos
void f(void) {
}
Funções variádicas
Funções variádicas são funções que tem a capacidade de receber um número variável de argumentos.
Para escrever funções variádicas, devemos colocar ... como o último argumento de uma função, antes do C23 era necessário ter ao menos um argumento além do ..., porém no C23 essa obrigatoriedade foi removida.
Exemplo de função variadica :
int printf(const char *restrict format, ...);
Para utilizar os argumentos de uma função variádica, é necessário utilizar as macros definidas na biblioteca stdarg.h junto do tipo va_list que indica a lista de argumento variádicos.
Descrições das macros, bem como dos seus argumentos (que estão descritos entre parenteses):
-
va_start(LISTA,INICIO): a macrova_startinicializa a variávelLISTAdo tipova_listque aparece logo após o argumentoINICIO, sendo necessário informar o argumentoINICIOsempre que houver outro argumento antes dos argumentos variádicos (o que é obrigatório antes doC23). -
va_arg(LISTA,TIPO): a macrova_argretorna o próximo valor do tipo informado emTIPOda variávelLISTAdo tipova_listque foi inicializada comva_start, a ideia é que a cada chamada deva_argum argumento é extraido e ava_list“avança de posição”. -
va_copy(DESTINO,FONTE): Adicionado noC99, copia a variávelFONTEdo tipova_listpara a variávelDESTINOtambém do tipova_list, sendo necessário chamarva_endpara cada uma das listas. -
va_end(LISTA): Finaliza a variávelLISTAque foi inicializada comva_start, a ideia é que normalmente essa funcionalidade é implementada usando a stack e usarva_endlimpa a stack utilizada porLISTA.
Abaixo um exemplo de uma função de argumentos variádicos que calcula uma média aritmética.
#include <stdarg.h>
#include <stdio.h>
double calculaMedia(int quantidade, ...)
{
double soma = 0;
va_list argumentos;
va_start(argumentos);
for(int i = 0; i < quantidade; i++)
soma += va_arg(argumentos, double);
va_end(argumentos);
//Evita divisão por zero ou com números negativos...
if(quantidade <= 0)
return 0;
return (soma / quantidade);
}
int main()
{
const int quant = 3;
const double prova1 = 5.7;
const double prova2 = 8.4;
const double prova3 = 9.2;
double media = calculaMedia(quant, prova1, prova2, prova3);
printf("A media das notas é %.2f\n", media);
}
Apesar do C23 ter removido a obrigatoriedade de outros argumentos, é normal que seja necessário adicionar ao menos um argumento obrigatório, para que seja possível saber quantos argumentos são.
Também é interessante saber que algumas funções do padrão do C como printf e scanf e suas variações, que normalmente são funções variádicas, também tem outras variações que começam com v como vprintf e vscanf que aceitam um parâmetro do tipo va_list.
Isso pode ser utilizado por exemplo, para implementar uma função variádica que faça algum tratamento adicional antes de chamar essas funções, por exemplo :
#include <stdlib.h>
#include <stdio.h>
#include <stdarg.h>
/*
A função "scanf" normalmente é extremamente problemática para
leitura de entrada do usuário no terminal, pois pode manter coisas
pendentes no buffer de leitura
A própria documentação do manpages aponta isso e relembra a dificuldade
de usar "scanf" corretamente
Utilizar "fgets" para leitura e possivelmente depois uma função separada
de conversão como "sscanf"/"strtol"/"strtod"/"strtof" é melhor para ler
entrada do usuário, porém é mais complexo
Aqui vamos mostrar como podemos fazer a combinação "fgets" + "sscanf" ficar
transparente de forma que funcione como um "scanf" porém sem o problema de
leitura pendente.
Vale lembrar, que o "scanf" é capaz de lidar com entradas enormes e as lê
sob demanda, enquanto aqui estou tentando ler a linha inteira de uma vez,
portanto "scanf" é ideal para leituras maiores (acima dos 4KB que defini)
enquanto essa função se adequa melhor para leituras simples escritas pelo
usuário.
*/
int scanf_user(const char *restrict format, ...)
{
char line[4096];
if(fgets(line, sizeof(line), stdin) == NULL)
return feof(stdin) ? EOF : 0;
va_list args;
va_start(args, format);
int result = vsscanf(line, format, args);
va_end(args);
return result;
}
int main()
{
int test1, test2;
scanf_user("%d\n", &test1);
scanf_user("%d\n", &test2);
printf("%d e %d\n", test1, test2);
}
Para testar a diferença prática do código acima, experimente escrever abacate na primeira entrada e 10 na segunda, e depois trocar as chamadas de scanf_user para scanf e testar novamente do mesmo jeito.
Modificadores
Ainda existem 2 modificadores utilizados em funções, que fornecem dicas para o compilador, sendo eles inline e _Noreturn.
Inline
O modificador inline é utilizado como uma dica para o compilador, indicando que chamar a função, deve idealmente evitar uma chamada “real” da função e apenas inserir as instruções contidas nela diretamente no local onde ela foi chamada.
Em funções com vinculação interna, o modificador inline pode ser usado normalmente (static inline).
A regra do C é que “se todas as declarações de funções especificam inline sem extern então a definição naquela unidade de tradução é uma definição inline”, logo se em algum lugar de uma unidade de tradução escrevermos extern inline void funcao1(); por exemplo, todas as definições da função funcao1 mesmo tendo inline, não serão tratadas como inline.
Na prática isso significa que o ideal é utilizarmos sempre static inline e opcionalmente, podemos fornecer em uma das unidades de traduções compiladas, uma única versão “não inline” da função que tenha o mesmo nome.
Motivação por trás do uso de inline
Chamar funções muitas vezes é custoso comparado com algumas instruções mais simples e chamar funções bilhões de vezes pode ter um custo relevante comparado a executar diretamente suas instruções.
Porém, o compilador é livre para ignorar a presença ou ausência desse modificador, fazendo o inline de funções que são pequenas e não tem o modificador inline ou decidindo mesmo numa função que o tenha que é mais eficiente chamar a função do que gerar cópias enormes de um código que é chamado em vários lugares e é grande.
Os compiladores de hoje em dia são cada vez mais inteligentes, portanto é difícil saber se inline realmente fará alguma diferença, a melhor maneira de saber isso é testando, para isso o Compiler Explorer é uma ótima alternativa que permite visualizar o assembly gerado ao compilar.
_Noreturn
O modificador _Noreturn pode ser utilizado como noreturn ao adicionar a biblioteca stdnoreturn.h, no C23 ele foi depreciado e substituito pelo atributo [[noreturn]].
Este modificador indica que a função não vai retornar sob hipótese alguma, pois provavelmente vai utilizar exit ou algum outro mecanismo como longjmp que modifique o fluxo de execução impedindo o retorno.
Se existir a remota possibilidade da função retornar, como no caso de funções como o execve do linux, que apesar de não retornar caso bem sucedida, ainda pode falhar, o ideal é não marcar a função como noreturn.
Existem dois motivos principais para marcar uma função como noreturn, a possibilidade de otimizações adicionais pelo compilador e avisos melhores por parte do compilador, que pode possivelmente indicar quando código é escrito após a chamada de uma função noreturn ou mesmo o uso da palavra chave return dentro dela.
Variáveis Derivadas
O nome variável derivada, indica variáveis que dependem da existência de outros tipos de variáveis para existir e são muitas vezes “geradas” através de definições pela linguagem (como estruturas, arrays, uniões e enumerações).
Entenda que como os tipos derivados são gerados ou definidos em termos de tipos primitivos, um domínio e entendimento maior das variáveis primitivas acaba sendo um requisito para um entedimento mais completo dos tipos derivados.
Enumerações
Enumerações são tipos de dados que definem um intervalo limitado de números inteiros. Eles são efetivamente equivalentes a tipos inteiros primitivos.
Utilizar enumerações geralmente permite uma integração melhor com ferramentas de debug e avisos do compilador, demonstrando a intenção do programador de usar um número que faz parte de um conjunto limitado de valores.
Declaração de enum
Novos tipos de enum podem ser gerados utilizando a palavra chave enum e suas definições tem escopo (ou seja, um enum gerado dentro de um bloco {} só existe dentro dele).
No C, ao declarar um novo tipo enum usando, por exemplo, enum NovoTipo, é necessário utilizar enum NovoTipo no tipo da variável para criar uma variável que tenha o tipo do enum criado, enquanto que no C++, pode ser utilizado tanto enum NovoTipo como apenas NovoTipo.
As definições de enum seguem a seguinte sintaxe :
enum NomeDoEnum{
ConstantesDoEnum
}VariaveisCriadas;
NomeDoEnumindica o nome do enum, usado para definir novas variáveis do tipo do enum, este campo é opcional, caso esteja ausente o enum gerado é “anônimo” e não pode ser criado fora da declaração do enum (neste caso seu tipo não tem nome mas existe).ConstantesDoEnumé uma lista, que deve conter ao menos um elemento, de nomes de constantes que serão geradas, separadas por virgula (geralmente uma em cada linha), que podem, opcionalmente, ser inicializados com uma expressão constante (isso será explicado em mais detalhes a seguir).VariaveisCriadasé opcional e indica uma lista separada por virgula de variáveis que serão criadas junto da declaração do enum com o tipo que está sendo declarado, é a única forma de criar variáveis do tipo de um enum anônimo (além claro, do uso detypeofcom uma variável criada desta forma).
Logo uma enumeração que busca ter valores inteiros indicando dias da semana pode ser escrita da seguinte forma:
enum DiasDaSemana{
SEGUNDA_FEIRA,
TERCA_FEIRA,
QUARTA_FEIRA,
QUINTA_FEIRA,
SEXTA_FEIRA,
SABADO,
DOMINGO
};
Neste caso os valores seguem uma sequência, com SEGUNDA_FEIRA sendo 0 e DOMINGO sendo 6.
O primeiro campo do enum sempre começa em 0, a menos que seu valor seja definido com uma expressão constante, já os outros campos tem o valor do campo anterior + 1.
É possível, declarar os possíveis valores de enums com qualquer expressão constante usando = VALOR após a declaração do nome do valor do enum, onde VALOR é uma expressão constante que pode incluir constantes definidas previamente na mesma declaração de enum.
Isso pode ser visto no exemplo abaixo:
enum VersoesWindows{
WINDOWS98 = 98,
WINDOWS2000 = 2000,
WINDOWS7 = 7,
WINDOWS8, //Tem valor 8
WINDOWS10 = 10,
WINDOWS11, //Tem valor 11
WINDOWS_MAIS_RECENTE = WINDOWS11, //Usa uma constante declarada neste mesmo enum
};
Regras para tipo compatível
Até antes do C23, todas as constantes definidas em um enum são consideradas como do tipo int a não ser que elas não possam ser representadas por ele, neste caso os valores são ajustados para o menor tipo de inteiro com sinal ou sem sinal que consiga representar o número.
Vale lembrar que apesar das constantes do enum serem normalmente do tipo int, o tipo efetivo que uma variável do tipo de um enum pode ser qualquer tipo inteiro, incluindo char, que tenha capacidade suficiente para guardar qualquer valor definido no enum.
Vários compiladores geralmente oferecem flags de compilação especificas para forçar tipos enum a serem menores ou não, oferecendo opção para que tipos menores do que int sejam utilizados caso seja possível.
Devido a falta de garantia quanto ao tamanho real de um enum, é comum que as pessoas evitem enum onde é necessário um tamanho fixo e garantido, ou escrevam constantes com valores altos que forcem um determinado limite (como por exemplo uma constante com 0xFFFFFFFF para forçar um enum a ter ao menos 32bits).
No C23, as regras anteriores ainda se aplicam, porém, existe uma nova forma de declaração que inclui : TIPO, onde TIPO é o tipo que será utilizado para representação do enum.
Todas as constantes de um enum declarado desse forma tem o tipo que foi definido explicitamente.
Aqui temos um exemplo de como ficariam as flags da função SetWindowPos da API do Windows, em um enum, utilizando as funcionalidades do C23 para forçar o valor como inteiro sem sinal de 32bits:
#include <inttypes.h>
enum SetWindowPosFlags : uin32_t {
SWP_NOSIZE = 0x1,
SWP_NOMOVE = 0x2,
SWP_NOZORDER = 0x4,
SWP_NOREDRAW = 0x8,
SWP_NOACTIVATE = 0x10,
SWP_FRAMECHANGED = 0x20,
SWP_HIDEWINDOW = 0x80,
SWP_NOCOPYBITS = 0x100,
SWP_NOREPOSITION = 0x200,
SWP_NOSENDCHANGING = 0x400,
SWP_DEFERERASE = 0x2000,
SWP_ASYNCWINDOWPOS = 0x4000,
};
Usos de enums
Existem algumas técnicas interessantes que podem ser feitas com enum, essa seção busca compartilhar essas ideias para que você possa aplicar em seu código, algumas dessas dicas provavelmente envolvem constantes no geral e podem ser realizadas da mesma forma usando o preprocessador com #define.
1 - enum para constantes de números inteiros
Antes do advento da palavra chave constexpr, utilizar enum era uma das únicas formas de definir constantes de números inteiros em C sem depender do preprocessador (#define), e mesmo com constexpr ainda é uma forma muito simples e menos verbosa para declaração de múltiplas constantes relacionadas.
Ao definir um enum anônimo e não declarar nenhuma variável do tipo do enum, temos efetivamente algo muito similar a criação de constantes.
enum{
RODAS_CARRO = 4,
RODAS_MOTO = 2,
RODAS_ONIBUS = 8,
RODAS_CAMINHAO = 14,
};
2 - Tamanho do enum
É muito comum utilizarmos enum para indicar um entre uma lista de possíveis etapas, valores, objetos, etc.
Em alguns casos é importante sabermos quantos itens existem no total, porém a linguagem C não oferece nenhuma funcionalidade para tal, ao menos nenhuma que independa de extensões de compilador.
Como toda enumeração sempre começa em 0, caso nenhuma declaração de constante no enum pule valores, é possível saber o tamanho ao definir um último item adicional e se limitar a adicionar novos itens sempre antes deste último item.
O exemplo abaixo demonstra isso :
enum UtensiliosCozinha {
UTEN_COZINHA_FACA,
UTEN_COZINHA_GARFO,
UTEN_COZINHA_COLHER,
UTEN_COZINHA_ESPATULA,
UTEN_COZINHA_PEGADOR_MASSA,
/* Adicionar novos itens acima */
UTEN_COZINHA_QUANTIDADE, //Sempre tem o número de itens do enum
};
3 - enum com bitmask
Neste caso é bem comum em vários headers em C utilizar #define para isso, da mesma forma enum pode ser utilizado nos mesmos casos, portanto o que está descrito aqui é muito mais uma técnica genérica usada com constantes do que efetivamente com enum.
O nome “bitmask” significa “máscara de bits”, e é uma técnica que envolve o uso dos bits para codificar valores, geralmente com cada bit representando um valor booleano.
É possível, por exemplo, colocar até 32 valores booleanos simultâneos em um mesmo bitmask que resida em um inteiro de 32bits, isso significa que é possível condensar múltiplas opções e estados em um mesmo valor e possivelmente checar qualquer combinação deles de forma muito mais simples e eficiente.
A ideia é que assim como descrito nos operadores bit a bit, é possível realizar operações separadas que checam bits em separado de um mesmo valor.
No exemplo abaixo temos um uso de bitmask para indicar status negativos de um RPG:
#include <stdio.h>
//É comum utilizarmos (1 << X) ou números em hexadecimal ao definirmos bitmasks
enum StatusNegativo{
ESTADO_PETRIFICADO = 1 << 0,
ESTADO_CONGELADO = 1 << 1,
ESTADO_CONFUSO = 1 << 2,
ESTADO_QUEIMANDO = 1 << 3,
ESTADO_ENVENENADO = 1 << 4,
ESTADO_SANGRANDO = 1 << 5,
ESTADO_DOENTE = 1 << 6,
//Caos ocorre quando temos os 3 estados (confusão, queimando e doente)
ESTADO_CAOS = ESTADO_DOENTE | ESTADO_CONFUSO | ESTADO_QUEIMANDO,
};
void reportaStatus(enum StatusNegativo status)
{
if(status & ESTADO_PETRIFICADO) puts("Você está petrificado");
if(status & ESTADO_CONGELADO) puts("Você está congelado");
if(status & ESTADO_CONFUSO) puts("Você está confuso");
if(status & ESTADO_QUEIMANDO) puts("Você está queimando");
if(status & ESTADO_ENVENENADO) puts("Você está envenenado");
if(status & ESTADO_SANGRANDO) puts("Você está sangrando");
if(status & ESTADO_DOENTE) puts("Você está doente");
if((status & ESTADO_CAOS) == ESTADO_CAOS)
puts("Você está no estado CAOS!");
}
int main()
{
reportaStatus(ESTADO_DOENTE | ESTADO_CONFUSO);
}
4 - enum local
Como o enum obedece o escopo atual, é possível utilizá-lo para definir constantes que só existem dentro de uma função, logo são privadas e não afetam o escopo global.
Exemplo :
void teste()
{
enum{
ETAPA1,
ETAPA2,
ETAPA3,
ETAPA4,
NUM_ETAPAS
};
for(int i = ETAPA1; i < NUM_ETAPAS; i++) {
//Código ...
}
}
Arrays
Arrays (ou vetores), são tipos que consistem em uma sequência, contínua na memória, de valores de um mesmo tipo. Usar arrays é uma forma de garantir que todos os seus elementos são sequenciais na memória.
Essa garantia também vem com uma grande vantagem, a possibilidade de acessar qualquer elemento do array ao utilizar um número inteiro que indicando a posição a ser acessada.
Tal número inteiro utilizado para indicar uma posição ou elemento no array é normalmente chamado de índice.
Declaração de arrays
A declaração de arrays é similar a de tipos primitivos, porém com a adição de [TAMANHO], onde TAMANHO é um número inteiro indicando o tamanho do array.
O acesso aos elementos do array, que se da pelo operador [], sempre inicia pelo índice 0 até o índice TAMANHO-1, considerando que TAMANHO foi o valor usado para declarar o array.
Exemplo :
int valores[10]; //Array com 10 elementos
valores[0] = 10; //Primeiro elemento
valores[9] = 100; //Último elemento
//(o tamanho é 10, então ele só vai de 0 a 9)
valores[10] = 50; //ERRADO! Não façam isso em casa!!
Vale lembrar que o índice usado para acessar o array pode ser qualquer expressão que resulte em um número inteiro, incluindo variáveis e funções, sendo normalmente utilizados em conjunto com laços de repetição.
O exemplo abaixo demonstra um cálculo do quadrado de vários números em um laço de repetição com array :
int quadradosPerfeitos[10] = {1,2,3,4,5,6,7,8,9,10};
for(int i = 0; i < 10; i++)
quadradosPerfeitos[i] *= quadradosPerfeitos[i];
//Quadrados perfeitos agora tem {1,4,9,16,25,36,49,64,81,100}
Quando escrevemos o nome do array sozinho, sem o operador [], teremos efetivamente um endereço do ínicio do array, similar ao uso de &variavel com outros tipos.
Também é importante mencionar que o operador de atribuição = não pode ser usado diretamente no array após sua declaração, de forma que array = array2 seja inválido, enquanto array[0] = array2[0] é válido.
Quando utilizamos o operador sizeof em arrays teremos o tamanho total do array considerando a soma total do tamanho de todos elementos.
Entrando em mais detalhes, existem 3 variações de arrays : arrays de tamanho constante, arrays de tamanho variável ou arrays de tamanho desconhecido.
Arrays de tamanho constante
Arrays são considerados como arrays de tamanho constante quando são inicializados com uma expressão de inteiro constante (definições de preprocessador, sizeof, constexpr ou enum) e seu tipo não inclui um array de tamanho variável.
Exemplo com várias formas de definir tamanhos de array :
#define TAM_ARRAY 10
enum {
TAM_ARRAY2 = 20
};
constexpr int TAM_ARRAY3 = 30; //C23 apenas
int main() {
const int TAM_ARRAY4 = 40;
int arr1[TAM_ARRAY]; //Array de tamanho constante
int arr2[TAM_ARRAY2]; //Array de tamanho constante
int arr3[TAM_ARRAY3]; //Array de tamanho constante
int arr4[TAM_ARRAY4]; //Array de tamanho variável
//(consts não são expressões constantes)
int arr5[8*sizeof(char)]; //Array de tamanho constante
}
Arrays de tamanho constante também podem ser inicializados com blocos, geralmente utilizando chaves {}, nesses casos o tamanho do array pode ser omitido, pois ele pode ser deduzido pela quantidade de elementos.
Existem alguns casos particulares onde arrays podem ser inicializados a partir de strings, desde que o tipo do array seja compatível com o da string.
Se houver uma inicialização, sempre que um elemento não for especificado, o valor padrão colocado nele será 0, portanto é normal utilizar {0} para inicializar todos elementos como zero.
//Inicializa com os 5 elementos já preenchidos
int arr1[5] = {1,2,3,4,5};
//arr2 tem efetivamente tamanho 10
int arr2[] = {1,2,3,4,5,6,7,8,9,10};
//str começa com 'a','b','c','\0' e tem tamanho 40
char str[40] = "abc";
//Tem tamanho 5 ('a','b','c','d','\0')
char str2[] = "abcd";
//Também tem tamanho 5
wchar_t str3[] = L"abcd";
//Nesse caso, todos os 400 elementos são zero
int arr3[400] = {0};
Em alguns lugares podemos ver o uso de
{}para inicializar todos elementos para 0.Essa forma de escrita só foi adicionada no
C23, mas está desde muito antes no C++ e é suportado pelo GCC como uma extensão de compilador, o ideal é utilizar sempre{0}para garantir uma maior compatibilidade.
Desde o C99 é possível também utilizar inicializadores designados para inicializar alguns elementos de posições especificas de um array.
Esse tipo de inicialização é particularmente útil quando combinado com enumerações, ou quando queremos pular a inicialização de valores ou inicializar os elementos de um array fora de ordem.
Exemplo usando inicializadores designados para vincular elementos de um enum a um array.
#include <assert.h>
#define ICON_PATH "/usr/config/icons"
//Calcula o tamanho de um array
#define ARRAY_SIZE(X) (sizeof(X)/sizeof(*X))
enum ProgramIcons{
PROGRAM_MAIN_ICON,
PROGRAM_CONFIG_ICON,
PROGRAM_FILE_ICON,
PROGRAM_DELETE_ICON,
/* Adicionar novos elementos acima */
PROGRAM_ICON_AMOUNT
};
//Array com o caminho do arquivo de cada icone da lista
const char *iconPath[] = {
[PROGRAM_MAIN_ICON] = ICON_PATH "/main.png",
[PROGRAM_CONFIG_ICON] = ICON_PATH "/cfg.png",
[PROGRAM_FILE_ICON] = ICON_PATH "/fileico.png",
[PROGRAM_DELETE_ICON] = ICON_PATH "/deleteico.png"
};
int main()
{
//Causa problema ao compilar quando o tamanho do array
//não bate com o enum
static_assert(PROGRAM_ICON_AMOUNT != ARRAY_SIZE(iconPath), "Atualize o array!!");
}
Arrays de tamanho variável
Desde o C99, quando inicializamos um array com um valor que não é uma expressão constante como por exemplo com valores de variáveis temos a criação de um array de tamanho variável.
Os arrays de tamanho variável normalmente são chamados de VLA, uma sigla do seu nome em inglês “Variable Length Array”.
O tamanho de um array de tamanho variável funciona de forma similar ao valor de variáveis locais com o modificador const, o tamanho do array é sempre redefinido ao executar a linha que o declara porém seu tamanho não muda no período entre sua criação e destruição.
Assim como arrays de tamanho constante, arrays de tamanho variável também não podem ter tamanho 0, portanto é importante sempre checar e evitar que o número utilizado para inicializar ele seja um número inteiro com valor maior ou igual a 1.
O operador sizeof funciona em arrays de tamanho variável e gera um tamanho correto para o array, porém os valores gerados não são constantes de compilação.
Exemplo da criação de um array de tamanho variável :
#include <stdlib.h>
#include <stdio.h>
int lerNumero()
{
char linha[1024];
fgets(linha, sizeof(linha), stdin);
return (int)strtol(linha, NULL, 10);
}
int main()
{
const int n = lerNumero();
if(n > 100) {
puts("O número informado é muito grande!");
return 1;
}
int array[n]; //Criação de um VLA com n elementos
printf("Array tem %zu bytes no total\n", sizeof(array));
}
Arrays de tamanho variável não podem ter duração estática, pois ela normalmente indica que o valor é pre-alocado durante a inicialização do programa, e como é impossível saber antecipadamente o tamanho, isso não pode ser feito.
Eles também não podem ter vinculação externa, de forma que VLAs só possam existir dentro de funções.
Desde o C11 um compilador pode definir __STDC_NO_VLA__ para 1 de forma a indicar que VLA e tipos derivados de VLA não sejam suportados.
Arrays de tamanho desconhecido
Arrays de tamanho desconhecido são declarado ao não especificar um tamanho nem um inicializador, utilizando apenas [], são considerados pela linguagem como um “tipo incompleto”.
Tipos incompletos são tipos onde não há informação suficiente para saber o tamanho efetivo e que podem ser eventualmente completados ao fornecer uma declaração com tamanho.
No caso de arrays, eles podem ser acessados, mas utilizar o operador sizeof resulta em erro, pois o tamanho do array não é conhecido.
Arrays como parâmetros de função
Ao serem colocados como argumentos de função, arrays, na verdade, “decaem” para ponteiros.
Mas o que quer dizer “decair” neste caso? Bom, eles efetivamente se tornam parâmetros equivalentes a ponteiros, logo utilizar o operador sizeof resulta no tamanho de um ponteiro e não no tamanho do array, o que pode ser um tanto confuso para iniciantes na linguagem.
Dessa forma, quando repassamos um array, não temos uma cópia do array e sim uma referência que acessa diretamente ele, permitindo também que ele seja modificado diretamente.
//Essa definição
int funcao(int parametro[10]);
//É equivalente a
int funcao(int *parametro);
int fun2(int param[10])
{
printf("%zu\n", sizeof(param)); //Equivalente a sizeof(int*)
}
int main()
{
int a[10];
printf("%zu\n", sizeof(a)); //Equivalente a sizeof(int) * 10
}
Você deve estar se perguntando “por que o C faz isso?”, a resposta é que passar arrays grandes via ponteiro é muito mais eficiente do que realizar cópias dos valores, a intenção por trás da escolha é clara e bastante compreensível de um ponto de vista de performance.
Apesar de existirem alguns casos onde arrays pequenos poderiam ser copiados de forma eficiente, o decaimento para ponteiros impede isso, a resposta nestes casos é fazer uma estrutura que inclua o array, pois estruturas podem ser copiadas, mesmo se incluirem um array dentro delas.
Um uso interessante de arrays como parâmetro é quando usamos em conjunto do modificador static, ao utilizar o operador static dentro dos colchetes [] seguido de um tamanho, obrigamos o array recebido via ponteiro a ter “pelo menos” o tamanho especificado, porém sizeof continua resultando no tamanho de um ponteiro.
Ao utilizarmos static podemos permitir que o compilador de C realize otimizações adicionais que normalmente não seriam possíveis sem essa garantia ou gerar avisos quando passamos um array que tem tamanho menor do que o definido.
void preencheTabuada(double valor, double tabuada[static 10])
{
for(int i = 0; i < 10; i++) {
tabuada[i] = valor * (i + 1);
}
}
int main()
{
double tabuada1[10];
double tabuada2[9];
//Funciona normalmente
preencheTabuada(8.0, tabuada1);
//Errado, provavelmente vai gerar um aviso no compilador
//ou causa comportamento indefinido
preencheTabuada(5.0, tabuada2);
}
Arrays multidimensionais
Quando o tipo do elemento de um array é outro array, dizemos que este é um array multidimensional.
Chamamos de dimensões, os campos necessários para acessar um array e subscrito ou índice os números utilizados em tais campos para acessar um array.
Ao definirmos um array, podemos especificar, através de um número entre colchetes, uma das dimensões do array, a quantidade de dimensões que um array pode ter é limitada apenas pela quantidade de memória disponível.
Lembrando que não importa quantas dimensões especificarmos em um array, ele ainda será sequencial na memória, o que muda é a forma com que acessamos ele e não sua representação interna.
Num array de duas dimensões a[3][4], por exemplo, teremos um número de elementos equivalente a 3 * 4, a mesma quantidade do array b[12] de uma dimensão, a dimensão mais a direita é sempre a parte que é contínua na memória.
Continuando esse exemplo no código :
int a[3][4];
int b[12];
//como ambos tem o mesmo número de elementos :
sizeof(a) == sizeof(b); //Essa expressão é verdadeira
a[0][0]; //Acessar a[0][0] é análogo a acessar b[0]
a[0][1]; //Acessar a[0][1] é análogo a acessar b[1]
a[1][0]; //Acessar a[1][0] é análogo a acessar b[4]
//Logo levando em consideração isso, podemos dizer que
a[x][y];
//É equivalente a acessar
b[4 * x + y];
/*
Logo, ao definirmos um array de multiplas dimensões, estamos definido um "ganho"
para cada indice e introduzindo uma forma mais simplificada de acessar o array,
que normalmente seria feita com cálculos mais complexos e extensos
*/
De uma maneira mais visual e simples, abaixo temos uma imagem que demonstra essa equivalência de um array de uma dimensão com um de duas dimensões :
Observe como o array a tem uma quantidade de elementos total equivalente ao array multidimensional b.
Da mesma forma, ambos são sequenciais na memória, você pode pensar nos quadrados coloridos abaixo de a como a “verdadeira” representação de b na memória, enquanto a representação abaixo de b como a representação lógica que estamos dando a essa memória quando a distribuimos em uma matriz.
A imagem também descreve a forma com que acessamos elementos ao usarmos indices em a e b, ao descrever quais elementos acessamos ao aumentar os valores de i e j.
Dica ao usar arrays multidimensionais
Ao utilizarmos um array de múltiplas dimensões também é importante lembrarmos que iterar primeiro pelos indices mais a direita é mais eficiente, pois estamos efetivamente acessando a memória de maneira sequencial.
O exemplo abaixo demonstra as duas formas de acesso de uma maneira mais clara :
#define LINHAS 10
#define COLUNAS 20
void teste()
{
int matriz[COLUNAS][LINHAS];
//Esta forma é menos eficiente
for(int i = 0; i < LINHAS; i++) {
for(int j = 0; j < COLUNAS; j++) {
matriz[j][i] = 10;
}
}
//Esta forma é mais eficiente
for(int i = 0; i < COLUNAS; i++) {
for(int j = 0; j < LINHAS; j++) {
matriz[i][j] = 10;
}
}
}
Usos de arrays multidimensionais
Utilizar um array de múltiplas dimensões geralmente é útil para representar uma variadade de coisas, alguns exemplos são :
- Matrizes Matemáticas
- Pixels em uma tela ou imagem (posição X e Y como índices)
- Video (Número do frame, posição X e posição Y como índices)
- Tabelas (linha e coluna como índices)
- Tabuleiro de Xadrez, jogo da cobrinha (linha e coluna também)
- Traduções do programa para outras linguas (qual lingua e qual texto como índices)
- Blocos em um jogo como minecraft (posições X,Y,Z como índice)
Abaixo um exemplo de uma representação simples de um pedaço de um teclado QWERTY :
char achaTecla(int x, int y) {
//ç não pode ser representado com apenas um "char"
char teclado[3][10] = {
{'q','w','e','r','t','y','u','i','o','p'},
{'a','s','d','f','g','h','j','k','l','?'},
{'z','x','c','v','b','n','m',',','.',';'}
};
return teclado[y][x];
}
Estruturas
Estruturas são tipos de dados compostos por um conjunto de outros tipos existentes, que são alocados de forma sequencial na memória, respeitando a mesma ordem declarada na estrutura.
Estruturas também são chamadas de “registro” que é o nome mais comum no português para se referir ao conceito de programação de um tipo de variável composto por um conjunto de outros tipos, no geral em C é muito comum nos referirmos como apenas struct, que é o mesmo nome da palavra chave utilizada para declarar uma estrutura.
Cada estrutura é composta de campos nomeados que podem ser de qualquer tipo, esses campos normalmente são chamados de “membros” e serão referidos dessa forma ao longo do texto.
Declaração de estruturas
Estruturas são declaradas utilizando a seguinte sintaxe :
struct atributos nomeDaEstrutura {
listaCampos
} variaveis;
Onde :
atributos: São atributos introduzidos noC23que são opcionais, porém caso sejam incluídos, devem ser declarados nessa posição da declaração da estrutura.nomeDaEstrutura: Indica o nome da estrutura, usado para definir novas variáveis do tipo da estrutura, este campo é opcional, caso esteja ausente a estrutura gerada é “anônima” e não pode ser criada fora da declaração da estrutura (neste caso seu tipo não tem nome mas existe).listaCampos: Uma lista de zero ou mais campos definindo os membros de uma estrutura, onde cada membro é composto pelo nome do tipo, nome do membro e um ponto e virgula.variaveis: é opcional e indica uma lista separada por virgula de variáveis que serão criadas junto da declaração da estrutura com o tipo que está sendo declarado, é a única forma de criar variáveis do tipo de uma estrutura anônima (além claro, do uso detypeofcom uma variável criada desta forma).
Lembrando que os campos de uma estrutura devem ter tamanho conhecido portanto não podem ser tipos incompletos, com a única exceção do campo de array flexível, que será detalhado depois.
Vale lembrar que toda declaração de uma estrutura tem escopo, portanto é possível, assim como em um enum, declarar estruturas locais que só existem dentro de um bloco.
Inicialização de Estruturas
De forma similar a arrays, estruturas também podem ser inicializadas utilizando chaves {} e desde o C99, podem utilizar inicializadores designados com o nome dos campos.
Exemplo de declaração de uma estrutura definido dados de uma pessoa, junto com 3 formas diferentes de inicialização :
#include <string.h>
//Numa implementação onde "int" é 4 bytes, sizeof(struct Pessoa) tem 104 bytes.
struct Pessoa {
char nome[85];
char cpf[15]; //XXX.XXX.XXX-XX
int idade;
};
int main()
{
//Campos são preenchidos na mesma ordem da estrutura
//e se não forem preenchidos, terão o valor 0
//Inicialização comum
struct Pessoa pessoa1 = {"Joao", "123.456.789-10", 25};
//Utilizando inicializadores designados
struct Pessoa pessoa2 = {
.nome = "Lucia",
.cpf = "987.173.762-28",
.idade = 22
};
//Atribuindo valores a uma estrutura não inicializada
struct Pessoa pessoa3;
strcpy(pessoa3.nome, "Carlos");
strcpy(pessoa3.cpf, "982.238.372-59");
pessoa3.idade = 35;
}
Vale lembrar que no C++ os inicializados designados precisam estar na mesma ordem de declaração dos membros da estrutura, porém, no C eles podem estar fora de ordem.
Antes do C23, de forma similar a arrays, para inicializar todos elementos de uma estrutura em 0, é necessário utilizar {0}.
Estruturas incompletas
Mesmo se uma estrutura ainda não foi declarada, ponteiros para ela podem ser criados, neste caso, a estrutura é efetivamente um tipo incompleto, impossibilitando o uso de sizeof ou acesso aos seus valores.
Ponteiros para estruturas incompletas não podem ser utilizados para ler/escrever valores, mas podem ser repassados para outras funções, o que é muito comum no padrão “pimpl”.
Exemplo de declarações envolvendo estruturas incompletas :
//Neste caso, uma lista encadeada tem um ponteiro
//do próprio tipo (que durante a declaração ainda é incompleto)
struct ListaEncadeada{
struct ListaEncadeada *proximo;
void *dado;
};
//Neste caso é feito um ponteiro para "struct Pessoa"
//Antes da definição, o tipo é inicialmente incompleto,
//mas é completado após a definição de "struct Pessoa"
struct VetorPessoa {
size_t quantidade;
struct Pessoa *pessoas;
};
struct Pessoa {
char nome[85];
char cpf[15]; //XXX.XXX.XXX-XX
int idade;
};
pimpl
O padrão pimpl (pointer to implementation ou “ponteiro para implementação” no português), é utilizado para encapsular e remover ou limitar o acesso aos campos da estrutura, impedindo efetivamente que código externo dependa da forma como os dados da estrutura são organizados.
O exemplo mais comum desse padrão sendo aplicado na prática é o próprio tipo FILE* presente na biblioteca padrão do C na stdio.h, isso ocorre pois a forma de representar um arquivo pode ser diferente entre sistemas operacionais ou até entre diferentes versões da biblioteca padrão.
Esse padrão normalmente é aplicado ao definir em um arquivo de cabeçário, o protótipo de funções que operam com um ponteiro da estrutura, sem declarar efetivamente a estrutura, a mantendo como um tipo incompleto. Enquanto, ao mesmo tempo, define um arquivo que implementa e define as funções e a estrutura.
Exemplo do uso do padrão "pimpl" para mapear um arquivo em memória no windows
//Código do .h (cabeçário)
#ifndef ARQUIVO_MAPEADO_H
#define ARQUIVO_MAPEADO_H
//Define um typedef que será utilizado pelas funções
typedef struct ArquivoMapeado ArquivoMapeado;
ArquivoMapeado *mapearArquivoEmMemoria(const char *caminho);
void *acessarArquivoMapeado(ArquivoMapeado *mapa);
size_t tamanhoArquivoMapeado(ArquivoMapeado *mapa);
void fecharArquivoMapeado(ArquivoMapeado *mapa);
#endif
//Código do .c para Windows
#include "arquivoMapeado.h"
#include <stdlib.h>
#include <windows.h>
struct ArquivoMapeado {
HANDLE objeto; /* Objeto do mapa de memoria */
void *dados; /* Ponteiro para dados*/
size_t tamanho; /* Tamanho do arquivo */
};
ArquivoMapeado *mapearArquivoEmMemoria(const char *caminho)
{
HANDLE arquivo = CreateFileA(caminho, GENERIC_READ | GENERIC_WRITE,
FILE_SHARE_READ, NULL, OPEN_EXISTING,
FILE_ATTRIBUTE_NORMAL, NULL);
if(arquivo == INVALID_HANDLE_VALUE)
return NULL;
struct ArquivoMapeado *mapa = malloc(sizeof(*mapa));
mapa->objeto = CreateFileMappingW(arquivo, NULL, PAGE_READWRITE | SEC_COMMIT,
0, 0, NULL);
mapa->dados = NULL;
if(mapa->objeto == NULL)
goto mapa_falhou;
DWORD tamAlto;
mapa->dados = MapViewOfFile(mapa->objeto, FILE_MAP_ALL_ACCESS, 0, 0, 0);
mapa->tamanho = GetFileSize(arquivo, &tamAlto);
//Caso "size_t" seja 64bits, adiciona a parte alta do tamanho
if(sizeof(size_t) == 8)
mapa->tamanho |= (size_t)tamAlto << 32;
mapa_falhou:
CloseHandle(arquivo);
return mapa;
}
void *acessarArquivoMapeado(ArquivoMapeado *mapa)
{
return mapa->dados;
}
size_t tamanhoArquivoMapeado(ArquivoMapeado *mapa)
{
return mapa->tamanho;
}
void fecharArquivoMapeado(ArquivoMapeado *mapa)
{
if(mapa == NULL)
return; //Proteção contra ponteiro nulo
if(mapa->dados != NULL)
UnmapViewOfFile(mapa->dados);
if(mapa->objeto != NULL)
CloseHandle(mapa->objeto);
free(mapa);
}
No caso descrito acima, poderiamos implementar outra versão do arquivo .c que funcione para linux sem a necessidade de mudarmos o código que chama essas funções, oferecendo uma flexibilidade e facilidade para tornar o código portável.
Membro de array flexível
Desde o C99, a definição de uma estrutura pode incluir como seu último membro um campo de array “incompleto”, onde o tamanho não é especificado.
O tamanho de tal membro não é incluido no tamanho da estrutura ao utilizar sizeof, esta estratégia normalmente é utilizada quando planejamos alocar dinamicamente a estrutura, reservando um espaço variável para o último campo.
Exemplo de uso do membro de array flexível para criação de um vetor dinâmico que guarda o tamanho do array :
#include <stdlib.h>
#define TAM_VETOR 20
struct VetorDouble{
size_t tam;
double dados[];
};
int main()
{
struct VetorDouble *vetor = malloc(sizeof(*vetor) + TAM_VETOR * sizeof(double));
vetor->tam = TAM_VETOR;
for(size_t i = 0; i < vetor->tam; i++)
vetor->dados[i] = (double)(i * i);
}
Membro de estrutura ou união anônima
Desde o C11, cada membro de uma estrutura ou união anônima que foi declarada dentro de uma estrutura é considerado como um membro direto dela.
Essa definição funciona de forma recursiva, portanto se uma estrutura ou união anônima tiver mais membros na mesma condição, todos os membros serão incorporados pela estrutura não anônima.
Exemplificando, a forma de acesso da estrutura a seguir :
struct Teste1 {
int a;
struct {
int b;
int c;
};
int d;
};
//Exemplo de uso
struct Teste1 test;
test.c = 10;
É exatamente a mesma forma com que acessariamos :
struct Teste2 {
int a;
int b;
int c;
int d;
};
//Exemplo de uso
struct Teste2 test;
test.c = 10;
No geral, essa regra normalmente é utilizada em conjunto com uniões para simplificar o acesso a alguns membros.
Alguns lugares usam macros especificas para lidar com versões anteriores do C que não suportam membros de estruturas ou uniões anônimas, a microsoft por exemplo utiliza macros como DUMMYSTRUCTNAME e DUMMYUNIONNAME que definem um nome caso não haja esse suporte.
Campos de bits
Campos de bits ou no inglês “bit fields”, são uma forma alternativa de declarar membros em uma estrutura, permitindo a escolha da quantidade de bits que o campo deverá ocupar.
Com isso é possível ter vários membros que compartilham do mesmo byte de outros membros, portanto o endereço de um membro declarado com campo de bits não pode ser utilizado.
Campos de bits são declarados com a seguinte sintaxe :
tipo identificador : tamanho;
tipoé o tipo do membro de campo de bits declarado, lembrando que há várias limitações no tipo de um campo de bit, que serão detalhadas em seguida.identificadoré o nome do membro, que é opcional, pois uma declaração de campo de bits também pode ser utilizada apenas para inserir um “buraco” com a quantidade de bits especificada na estrutura.tamanhoé a quantidade de bits que o campo deve ter.
Os tipos que um campo de bits podem ter são limitados a :
unsigned int: O campo de bits é um inteiro sem sinal (ex:unsigned int b : 3;tem os limites[0, 7])signed int: O campo de bits é um inteiro com sinal, reservando 1 dos bits para o sinal (signed int b : 3;tem os limites[-4,3])int: O campo de bits é um inteiro que pode ou não ter sinal, dependendo da implementação do compilador.bool: Pode ser utilizado para campos de bits de tamanho igual a 1, segue o mesmo comportamento de uma variável booleana._BitInt: Também pode ser utilizado para campos de bits com ou sem o modificadorunsigned.
No geral, apesar de ser definido pela implementação, o comportamento mais comum com campos de bits é que os valores são agrupados para compartilhar os bytes de um mesmo tipo.
Ao definir o tipo do bit field, a quantidade de bytes que o tipo fora de um bit field normalmente ocuparia é reservada para todos os campos de bit seguintes que usem o mesmo tipo, ou sua respectiva versão com ou sem sinal.
Para entender melhor, os exemplos a seguir, vamos levar em consideração :
C23ou a bibliotecastdbool.hjá incluidaboolcom 1 byteshortcom 2 bytes e permitido em bit fieldsintcom 4 bytes- Arquitetura onde 1 byte é 8bits
- Desconsiderar bytes extras colocado para alinhar membros e a estrutura
Neste exemplo teriamos uma estrutura com 5 bytes, pois 4 bytes foram reservados para os próximos bitfields de tipo int/unsigned int/signed int, porém como logo em seguida encontramos um do tipo bool que é diferente, houve uma outra reserva de mais 1 byte.
struct BitField1 {
unsigned int membro1 : 1;
bool membro2 : 1;
};
Neste outro exemplo, teriamos uma estrutura de 1 byte, pois utilizamos apenas tipo bool em todos os campos, o ocupando totalmente :
struct BitField2 {
bool membro1 : 1;
bool membro2 : 1;
bool membro3 : 1;
bool membro4 : 1;
bool membro5 : 1;
bool membro6 : 1;
bool membro7 : 1;
bool membro8 : 1;
};
Neste caso, temos 6 bytes, pois os membros 1 até o 3 ocupam totalmente os 32bits ocupados por um int e os membros 4 a 5 ocupam os 16bits ocupados por um short.
struct BitField3 {
unsigned int membro1 : 4;
signed int membro2 : 16;
unsigned int membro3 : 12;
unsigned short membro4 : 8;
signed short membro5 : 8;
}
Dito isso, há vários outros detalhes sobre campos de bits que também são “definidos pela implementação” :
- Se um campo de bits do tipo
inttem ou não sinal - Se tipos além dos mencionados acima são suportados em campos de bits (ex:
short,long,char, etc) - Se tipos atômicos são permitidos em um campo de bits
- Se a ordem dos bits de campos de bits em sequência é da esquerda para direita ou da direita para esquerda.
Alinhamento de estruturas
Ao definir estruturas, compiladores são livres para adicionar bytes extras de forma a garantir que os membros da estrutura estejam alinhados.
Cada tipo primitivo tem um número de bytes considerado como “requisito de alinhamento” diferente e diz-se que um campo está “alinhado” quando seu endereço e tamanho são múltiplos do requisito de alinhamento.
O padrão do C apenas especifica que bytes extras podem ser adicionados por questão de alinhamento, mas não entra em detalhes sobre a forma como isso deve ser feito, mantendo esse detalhe como “definido pela implementação”, repassando a responsabilidade aos compiladores e especificações de ABI para cada plataforma.
Para quem não sabe, ABI é uma sigla para “Application Binary Interface” e especifica a forma em comum que diferentes programas devem se comunicar em uma mesma plataforma, geralmente especificando convenções de chamada, requisitos de alinhamento e vários outros detalhes.
Lembrando que a ordem dos bit fields, apesar de definido pela implementação, geralmente acaba sendo definido pelas regras de ABI da arquitetura, arquiteturas ARM e x86 geralmente é da direita para esquerda, sendo a representação mais “comum”.
A forma mais precisa e efetiva de descobrir como exatamente o alinhamento e bitfields são lidados, é ler documentos que especificam esse comportamento, como por exemplo :
ABI x86-64 WindowsABI x86-64 SystemVABI ARM WindowsABI ARM64 WindowsDetalhes de implementação do GCC para ARM
No geral é possível saber quando uma estrutura teve bytes extras adicionais devido ao alinhamento quando o tamanho resultante de sizeof da estrutura, excede a soma total do tamanho de todos os seus membros.
Também é importante citar que a maioria dos compiladores oferece alguma extensão que permite forçar o alinhamento de uma estrutura, isso é particularmente útil quando estamos lendo um formato de arquivo ou realizando uma comunicação entre diferentes aplicações e queremos forçar o compilador a não alinhar os membros da estrutura.
Comportamento convencional ao alinhar estruturas
Apesar do padrão do C não especificar nada, vamos falar do comportamento mais convencional das implementações em relação ao alinhamento, que pode ou não estar correto para a sua plataforma (mas provavelmente está).
Então as seções seguintes não devem ser levadas ao pé de letra, pois podem não refletir todos os ambientes e compiladores disponíveis.
Requisitos de alinhamento
No geral o requisito de alinhamento de cada tipo geralmente é exatamente o tamanho do maior tipo primitivo ou ponteiro que o compõem.
Logo todo tipo primitivo ou ponteiro tem requisito de alinhamento igual ao seu tamanho em bytes, no caso dos ponteiros, me refiro a sizeof(void*) e não o tamanho do tipo que o ponteiro representa.
Arrays terão sempre requisito de alinhamento igual ao tipo usado para formar um array, arrays de char terão o mesmo requisito de um char, arrays de int terão o requisito de um int e assim por diante.
Estruturas seguem a mesma regra, terão o requisito de alinhamento igual ao membro com o maior requisito de alinhamento.
Ordem de declaração e alinhamento
No geral, “buracos de bytes” são adicionados logo após o membro que deseja ser alinhado e tanto os seus membros quanto a estrutura como um todo geralmente são alinhados.
Devido ao comportamento de uma estrutura de manter os seus elementos sequenciais na memória EXATAMENTE na forma como foram declarados, a ordem dos elementos pode alterar o tamanho da estrutura.
Observe o exemplo abaixo que demonstra isso :
#include <assert.h>
#include <inttypes.h>
struct teste1{
int16_t a;
int32_t b;
int16_t c;
};
struct teste2 {
int32_t b;
int16_t a;
int16_t c;
};
int main()
{
static_assert(sizeof(struct teste1) == sizeof(struct teste2),
"Alinhamento diferente");
}
No caso descrito acima, o código não compila, pois o static_assert falha indicando que o tamanho das duas estruturas são diferentes.
Devido a regra de que os elementos de uma estrutura são colocados exatamente na ordem declarada, existe uma necessidade de adicionar 2 bytes adicionais após a e c na estrutura teste1, devido ao requisito de alinhamento de 4 bytes.
Ao mesmo tempo, a estrutura teste2 não precisa de alinhamento, pois os valores a e c estão seguidos um do outro na memória, formando, juntos, 4 bytes.
Dessa forma sizeof(struct teste1) será 12 devido ao requisito de alinhamento, enquanto sizeof(struct teste2) será 8.
Offset de membros
A biblioteca stddef.h (incluida junto com stdlib.h) inclui a macro offsetof, que pode ser utilizada para calcular o offset em bytes de um membro de uma estrutura.
Exemplo de uso:
#include <stddef.h>
struct Test1 {
int v1;
char v2;
short v3;
};
//valor do offset, terá (sizeof(int))
offsetof(struct Test1, v2);
//valor do offset
// terá (sizeof(int) + sizeof(char))
//junto de um possível offset usado para alinhar
offsetof(struct Teste1, v3);
Uniões
Uniões são tipos de dados compostos por um conjunto de outros tipos existentes, similar a estruturas, mas que compartilham a mesma memória para todos os seus membros.
O tamanho efetivo de um union é igual ao tamanho do seu maior membro.
A sintaxe para definição de uma união é exatamente a mesma utilizada para definição de estruturas, porém ao invés de escrevermos struct, utlizaremos a palavra chave union.
A regra para estruturas anônimas também se aplicam para definição de union.
Inicialização de uniões
Ao inicializar uma união utilizando chaves {}, apenas o primeiro membro de uma união é inicializado a menos que um inicializador designado (adicionado no C99) seja utilizado.
#include <inttypes.h>
union Num32 {
int32_t i32;
uint32_t u32;
float f32;
};
int main()
{
//Inicializará o campo "i32"
union Num32 a = {5};
//Inicializará o campo "f32"
union Num32 b = {.f32 = 1.0f};
//Não recomendado, pois tentará inicializar "i32" com um float
union Num32 c = {5.0f};
}
Reinterpretação de tipos
Um uso muito comum de uniões é a possibilidade de realizar o que chamamos de reinterpretação de tipos, o que é comumente chamado no inglês de “type punning”.
O uso de uniões para esse propósito é permitido desde o C99, mas é comportamento indefinido no C++ e em versões anteriores do C.
A reinterpretação de tipos seria efetivamente ler o valor de um tipo como se ele fosse outro, ao escrever em um dos membros do union e ler o valor por outro.
No exemplo abaixo, o uso de um union para reinterpretar um float e ler sua representação interna :
#include <stdio.h>
#include <stdlib.h>
#include <inttypes.h>
union ieee754_float {
float f32;
struct {
unsigned int fracao : 23;
unsigned int expoente : 8;
unsigned int sinal : 1;
};
};
float lerFloat()
{
char linha[1024];
fgets(linha, sizeof(linha), stdin);
return strtof(linha, NULL);
}
int main()
{
union ieee754_float valor;
printf("Escreva um ponto flutuante: ");
valor.f32 = lerFloat();
printf("sinal = %u\n"
"expoente = %u\n"
"fracao = %u\n",
valor.sinal, valor.expoente, valor.fracao);
}
Lembrando que o código acima funciona para processadores de arquiteturas ARM e x86 que tenham ordenação de bytes em little endian, porém, o mesmo sistema pode não funcionar em outras arquiteturas devido a forma como variáveis de ponto flutuante e bitfields são ordenados.
Em sistemas linux é comum a presença do cabeçário iee754.h que tenta tratar dessas diferenças com diretivas de preprocessador.
Usos de uniões
Existem algumas técnicas interessantes que podem ser feitas com union, essa seção busca compartilhar essas ideias para que você possa aplicar em seu código.
1 - Bitmask e booleanas
Geralmente ao utilizar o padrão de bitmask e separar várias flags em um único inteiro, temos um padrão que é um pouco mais complexo de utilizar do que bit fields de campos booleanos, mas que é mais flexível para definir ou checar múltiplas variaveis de uma vez.
Utilizando uniões, podemos juntar ambos em um único tipo, o exemplo abaixo demonstra isso extendendo o exemplo de RPG utilizado em enumerações:
#include <inttypes.h>
#include <stdbool.h>
#include <stdio.h>
enum {
ESTADO_PETRIFICADO = 1 << 0,
ESTADO_CONGELADO = 1 << 1,
ESTADO_CONFUSO = 1 << 2,
ESTADO_QUEIMANDO = 1 << 3,
ESTADO_ENVENENADO = 1 << 4,
ESTADO_SANGRANDO = 1 << 5,
ESTADO_DOENTE = 1 << 6,
ESTADO_CAOS = ESTADO_DOENTE | ESTADO_CONFUSO | ESTADO_QUEIMANDO,
};
struct DadosPersonagem {
const char *nome;
int vida;
//União e estrutura anônima
union {
struct {
bool petrificado : 1;
bool congelado : 1;
bool confuso : 1;
bool queimando : 1;
bool envenenado : 1;
bool sangrando : 1;
bool doente : 1;
};
uint32_t estado;
};
};
int main()
{
struct DadosPersonagem personagem = {
.nome = "Jonas",
.vida = 100,
.confuso = true,
.doente = true,
.queimando = true
};
//É possível checar multiplos valores de uma vez
if((personagem.estado & ESTADO_CAOS) == ESTADO_CAOS)
puts("Personagem no estado CAOS");
//Mas também podemos checar individualmente cada bit
if(personagem.doente)
puts("Personagem está doente");
}
2 - Pseudo Polimorfismo
É possível implementar um pseudo polimorfismo utilizando uniões, geralmente utilizando um número inteiro ou enumeração para indicar qual tipo é atualmente representado.
Isso é extremamente útil para representar tipos variantes, campos utilizados para repassar mensagens ou dados similares.
Um exemplo com definições de tipos que poderiam ser usados para representar um JSON :
enum TipoJson{
TIPO_JSON_NUMERO,
TIPO_JSON_STRING,
TIPO_JSON_OBJETO,
TIPO_JSON_BOOLEANA,
TIPO_JSON_LISTA,
TIPO_JSON_NULL,
};
struct CampoJson {
enum TipoJson tipo;
//Todos os tipos da união compartilham a mesma memória
union {
double numero;
const char *string;
bool booleana;
struct CampoJson *lista;
struct ObjetoJson *objeto;
};
};
struct ChaveValorJson {
const char *chave;
struct CampoJson valor;
};
struct ObjetoJson {
size_t tamanho;
struct ChaveValorJson *campos;
};
Outros exemplos de uso real de union para este propósito :
- A estrutura
INPUTdo windows utilizada na funçãoSendInputpara representar entrada de mouse, teclado ou hardware. - A união
SDL_Eventutilizada para representar qualquer evento de janela ou do sistema pela biblioteca SDL. - A união
XEvent, utilizada pelo X11, gerenciador de janelas normalmente utilizado no linux, para representar eventos de janela. - A união
iwreq_datautilizada em conjunto com a funçãoioctl(que receberá um número indicando o comando, sendo o inteiro que diferencia o tipo neste caso) para receber/enviar dados para o driver de rede no linux.
Ponteiros
Um ponteiro é um tipo de variavel utilizado para se referir a uma variável de outro tipo ou função. Ponteiros também podem referênciar o “nada”, indicado pelo valor especial de ponteiro nulo.
Ponteiros são classificados em duas categorias distintas, ponteiros para dados que referenciam outras variáveis e ponteiros para funções, que permitem referenciar e chamar funções via referência.
Declaração de ponteiros
Para declarar um ponteiro utilizamos a seguinte sintaxe :
* atributos modificadores nome
//exemplo
int *a; //Ponteiro para int
float **b; //Ponteiro de ponteiro para float
const char *c; //Ponteiro para caractere constante
char *const d; //Ponteiro constante para caractere
- O asterisco é obrigatório e indica a declaração do ponteiro
atributossão opcionais e indicam os atributos adicionados na linguagem noC23, eles devem sempre aparecer após o asterico mas antes dosmodificadorese donome.modificadoressão opcionais e indicam modificadores comoconst,restrict,volatile, etc.nomeindica o nome da variavel criada ou outro*.
Lembrando que modificadores antes do asterisco, afetam o dado (ex: const char* = ponteiro modificável para dado constante) e após o asterisco afetam o ponteiro em sí (ex: char *const= ponteiro constante para dado modificável).
Explicação
Um ponteiro atua guardando um “endereço de memória”, que pode ser utilizado para ler e escrever em outras variaveis ou no caso de ponteiros de função, executá-las.
Pense neles como um link para uma página, um atalho para um arquivo, um endereço de uma casa, basicamente uma informação utilizada para te levar a outra, permitindo um acesso direto mas sem ser uma cópia completa.
Este termo será útil ao longo do texto, normalmente chamamos de “indireção” a necessidade de ler e acessar um endereço de memória para efetivamente ter acesso a uma variável, ponteiros podem ter vários “níveis de indireção”, sinalizados pela quantidade de asteriscos usados na declaração da variável.
Como interpretar a sintaxe de ponteiros
Cada asterisco utilizado para declarar um ponteiro indica um nível de indireção necessário para “chegar efetivamente” no tipo apontado, essa é a maneira pretendida pelos autores da linguagem para interpretarmos a sintaxe de ponteiros.
Por exemplo, é comum ver as duas interpretações diferentes, geralmente associadas até mesmo a forma como os programadores formatam a declaração da variável :
const char **a; //Interpretação "a"
const char** b; //Interpretação "b"
Interpretação a: Após duas indireções, teremos o tipoconst char.Interpretação b: Temos um ponteiro de ponteiro paraconst char.
A diferença, apesar de sutil, é que na interpretação a estamos preocupados com o “tipo efetivo após indireções”, enquanto na interpretação b com o “tipo final gerado na declaração”.
Ambas as interpretações são válidas, porém infelizmente a linguagem favorece a interpretação a, apresentando casos onde a interpretação b pode levar o programador ao erro ou confusão com a sintaxe para declarar ponteiros mais complexos:
//Neste caso :
//a é "const char**"
//b é apenas "const char"
const char** a, b;
//Neste caso, agora correto :
//Ambos tem o tipo "const char**"
const char **c, **d;
//Se removermos o asterisco e o parenteses
//teremos exatamente a sintaxe de função!
void funcao(); //Declaração de função
void (*funcaoptr)(); //Ponteiro de função
//Se utilizarmos *arr, ele se torna um array de 10 elementos
//Logo, *arrptr também se torna um array de 10 elementos após a indireção
int arr[20][10]; //Matriz
int (*arrptr)[10]; //Ponteiro para matriz
Ponteiros para dados
Ponteiros para dados podem ser inicializados utilizando o resultado do operador de endereço & aplicado a uma variavel.
int v1;
int *p1 = &v1; //p1 agora tem o endereço de "v1"
*p1 = 10; //Escreve em v1
int v2[10]; //Array de 10 elementos
int (*p2)[10] = &v2; //Ponteiro para array de 10 elementos
(*p2)[0] = 10; //Escreve em v2[0]
int v3[20]; //Array de 20 elementos
int *p3 = v3; //Aponta para o array
*p3 = 20; //Escreve em v3[0]
struct{
int n;
}v4; //Estrutura com um inteiro
int *p4 = &v4.n; //Aponta para o membro
*p4 = 30; //Escreve em v4.n
A sintaxe para uso de ponteiros pode ser um tanto confusa de inicio, mas na verdade ela é bem similar ao uso de arrays, o examplo abaixo demonstra isso :
int array[10];
int *ptr = array;
//O operador de dereferenciar ponteiros funciona igual ao [0]
//e funciona tanto para arrays, quanto para ponteiros
*array = 10; //Escreve 10 em array[0]
*ptr = 20; //Escreve 20 em array[0]
//Mesmo comportamento
array[0] = 30;
ptr[0] = 40;
//Diferente
sizeof(array); //Igual a sizeof(int) * 10
sizeof(ptr); //Igual a sizeof(int*)
array++; //Proibido, não podemos mudar o inicio do array!
ptr++; //Permitido, agora ptr[0] modificará array[1]
ptr[0] = 30; //Modifica array[1] devido ao incremento do ponteiro
ptr--; //Permitido, agora ptr[0] novamente modificará array[0]
//Existe uma outra diferença quanto a arrays
//Usar o operador & faz com que recebamos um ponteiro para array
array; //Equivale a "int*"
&array; //Equivale a "int(*)[10]"
ptr; //Equivale a "int*"
&ptr; //Equivale a "int**"
Basicamente, ponteiros tem um comportamento similar a arrays, porém o operador sizeof relatará o tamanho de um ponteiro e podemos somar/subtrair da variável do ponteiro para avançar/retroceder elementos.
Neste caso, podemos pensar num ponteiro como uma junção de “array” + “indice” em um único valor.
Comparações de ponteiros de dados também funcionam, comparações de igualdade podem checar se ponteiros apontam para o mesmo endereço, já comparações de maior/menor funcionam apenas com ponteiros que apontam para um mesmo array, ou para diferentes membros de uma mesma estrutura.
Quando utilizamos ponteiros para estruturas, o operador -> pode ser utilizado para acessar os membros de uma estrutura via ponteiro, facilitando a sintaxe :
int main()
{
struct Pessoa{
const char *nome;
int idade;
}pessoa;
struct Pessoa *joao = &pessoa;
//Com o operador "->"
joao->nome = "Joao da Silva";
joao->idade = 25;
//Sem o operador "->"
(*joao).nome = "Joao da Silva";
(*joao).idade = 25;
}
Quando somamos ou subtraimos um ponteiro, obtemos um ponteiro avançando/retrocedendo elementos equivalente a soma/subtração, logo ptr+1 é equivalente a &ptr[1].
Esse comportamento também demonstra a importância do tipo do ponteiro, pois digamos que ptr represente um ponteiro para um tipo que tem 8 bytes e esteja no endereço 0x200, ptr+1 estará no endereço 0x208, logo somar 1 no ponteiro, na verdade está somando 8 internamente.
O exemplo abaixo, demonstra algumas operações aritméticas que podem ser realizadas com ponteiros :
int arr[10];
int *inicio = arr;
int *fim = &arr[9];
//9, diferenças entre ponteiros resultam na quantidade de elementos entre eles
ptrdiff_t diff = fim - inicio;
//10, o tamanho do array!
ptrdiff_t tam = (fim - inicio + 1);
//estas três expressões tem o mesmo endereço :
inicio+1;
&inicio[1];
&arr[1];
//estas três, tem o mesmo endereço também :
fim-1;
&fim[-1];
&arr[8];
Além disso, um fato curioso sobre o operador [] pode ser visto no exemplo abaixo :
int x = 0;
int array[10];
//Isso aqui
array[5] = 10;
//É equivalente a
*(array + 5) = 10;
//Logo ambos são equivalentes :
array[x];
*(array + x);
//Devido a forma como o C implementa o operador []
//Isso aqui funciona :
x[array];
//Pois será o equivalente a
*(x + array);
//A ordem da soma não importa, portanto, funciona
Ponteiros para funções
Ponteiros de função guardam referências para funções e podem ser utilizados para chamá-las.
Podemos dizer que toda função já é um ponteiro de função, pois quando escrevemos uma função sem colocar parenteses, temos efetivamente o endereço dela.
De forma que assim como ponteiros de dados tem uma sintaxe muito similar a arrays, ponteiros de função tem uma sintaxe muito similar a funções.
Para declarar um ponteiro de função, temos uma sintaxe muito similar a utilizada ao declarar funções :
//Declaração de função
tipoRetorno NomeFunção(parametros);
//Declaração de ponteiro de função
tipoRetorno (*NomeVariavel)(parametros);
Basicamente a mesma sintaxe, porém com o nome entre parenteses com um asterisco, indicando que há uma indireção para acessar efetivamente a função.
Para chamar uma função via ponteiro, a sintaxe é exatamente a mesma utilizada para chamar funções :
#include <stdio.h>
int main()
{
//Similar a declaração de função, mas com um parenteses a mais
int (*puts2)(const char*) = puts;
puts("Testando puts");
puts2("Testando outro puts"); //Igual a chamada de função normal
}
Para ponteiros de função, apenas a comparações de igualdade são aceitas pelo padrão da linguagem, já todas as outras operações como soma, subtração, maior/menor não estão definidas.
Ponteiro Nulo
O ponteiro nulo é um valor especial que indica que a variavel atualmente representa uma referência vazia, ou seja, “nada”.
É um valor constantemente utilizado para indicar um erro, ausência de valor, entre outras situações excepcionais.
No geral a linguagem C tem um tratamento um tanto “especial” para indicar um ponteiro nulo, algo que ainda hoje causa confusão e desentendimentos.
Toda vez que atribuimos um valor que é “uma constante de compilação inteira de valor 0” a um ponteiro, ele magicamente se transforma no “valor de ponteiro nulo”, que pode ou não ser representado internamente como 0 (todos bits em 0).
Da mesma forma, a comparação de igualdade de um ponteiro nulo com 0 é sempre Verdadeira, mesmo que o hardware use um número diferente internamente.
Logo isso indica que “para linguagem C” o ponteiro nulo é sempre 0, porém para o hardware isso pode ser diferente, as arquiteturas modernas resolveram esse problema definindo em hardware o ponteiro nulo como 0, assim como o padrão POSIX exige que ponteiros nulos sejam representados em hardware com todos bits em 0.
Um exemplo demonstrando este comportamento, assumindo uma arquitetura onde o ponteiro nulo não é 0:
enum {
NULO_1 = 0,
};
#define NULO_2 0
int main()
{
const int nulo3 = 0;
int arr[5];
void *p = arr;
memset(p, 0, sizeof(p)); //Define como 0, e não ponteiro nulo
p = NULO_1; //Define como ponteiro nulo
p = NULO_2; //Define como ponteiro nulo
p = nulo3; //Define como 0, pois nulo3 não é constante de compilação
}
No geral é muito comum programas utilizarem a função memset com o valor 0 para inicializar uma estrutura, isso faz com que o código não seja portável para arquiteturas antigas ou de embarcados onde o valor em hardware para o ponteiro nulo não seja 0, mas não há problema algum em escrever código assim, desde que não seja utilizado em tais arquiteturas.
Macro NULL
Geralmente quando queremos atribuir ou comparar um ponteiro nulo, utilizamos a macro NULL definida em stdlib.h, stdio.h e vários outros headers padrões do C, usada para gerar a constante de ponteiro nulo.
Sobre ela, qualquer implementação pode escolher uma entre as seguintes opções para implementar a macro :
0(void*)0nullptr(desdeC23)
O principal problema neste caso é a possibilidade da utilização de 0, que em alguns contextos, será tratada como int e não void*, causando problemas em interações com funções com parâmetros variádicos, operador sizeof, operador _Generic do C11 ou typeof do C23.
O padrão POSIX determina que toda implementação de C deve utilizar NULL como (void*)0, evitando os problemas citados.
nullptr
No C23 foi adicionado a palavra chave nullptr que tem uma funcionalidade similar a NULL, criada para resolver problemas devido a possibilidade de NULL ser 0 e não (void*)0 que tem um tipo próprio, nullptr_t.
Isso levou as seguintes vantagens:
- Compatibilidade maior com C++
- Dispensa necessidade de incluir as bibliotecas padrão só pela definição de
NULL - Tipo especifico para uso em
_Generic - Solução para problemas ao usar
typeof - Solução para problemas que ocorreriam caso
NULLfosse0
Tamanho de um ponteiro
O tamanho de um ponteiro é vinculado diretamente a arquitetura do processador, sistema operacional e compilador, então seu valor geralmente é dependente de uma variadade de fatores.
Nos sistemas modernos é comum que o tamanho dos ponteiros seja exatamente a quantidade de bits da arquitetura e o tamanho dos registradores em hardware, logo programas de 32bits tem ponteiros de 32bits (4 bytes) e programas 64bits tem ponteiros de 64bits (8 bytes).
No geral os ponteiros, tem sempre o mesmo tamanho independente do tipo que referenciam :
sizeof(char*) = sizeof(double*) = sizeof(void*)
Assim como o mesmo ocorre entre ponteiros de função :
sizeof(void (*)()) = sizeof(int (*)(float))
Alguns sistemas embarcados ou mais antigos tem sua memória separada em segmentos, os compiladores para essas arquiteturas geralmente suportam um modificador extra far como extensão de compilador, que permite criar ponteiros “maiores” que podem referenciar dados que estejam em outros segmentos.
Ponteiros para funções e ponteiros para dados não necessariamente precisam ter o mesmo tamanho, em algumas arquiteturas antigas e sistemas embarcados o código de máquina e dados ficam em segmentos de memória separados, possibilitando tamanhos diferentes de endereçamento.
Porém, todo sistema operacional moderno utiliza ponteiros de função e de dados com o mesmo tamanho, inclusive a especificação POSIX para sistemas UNIX portáveis exige essa igualdade.
Programa que escreve um endereço e os tamanhos de ponteiros :
#include <stdio.h>
int main()
{
int valor;
int *p = &valor;
printf("%p\n" //%p é o formatador para ponteiros
"tamanho int* = %zu\n" //%zu é o formatador para "size_t"
"tamanho void* = %zu\n"
"tamanho ponteiro funcao = %zu\n",
p, sizeof(p), sizeof(void*), sizeof(void (*)()));
}
Ponteiro void
No C é muito comum o uso do tipo void* para representar ponteiros, como todo ponteiro de dados tem o mesmo tamanho, podemos ter um parâmetro que indica um ponteiro de dados “genérico” com o void*.
A ideia é que não é possível acessar seu valor, pois ele aponta para um objeto de tipo inexistente (void), não é possível somar/subtrair o ponteiro, pois não se sabe seu tamanho.
Qualquer ponteiro de dados pode ser implicitamente convertido para void* (tanto no C quanto no C++), e qualquer ponteiro void* pode ser implicitamente convertido para qualquer outro tipo de ponteiro (apenas no C).
Na prática isso significa que podemos passar qualquer ponteiro a uma função que aceita void*, mas se a função deseja acessá-los, ela deve fazer um cast ou passar para uma variável que seja um ponteiro de um tipo conhecido.
É muito comum o uso do cast para o tipo char* para somar ou subtrair um ponteiro void* num offset em bytes.
Ao mesmo tempo que funções como malloc que retornam void*, podem ser diretamente atribuidas a qualquer variavel de ponteiro sem necessidade de cast (no C apenas).
Strict aliasing
Uma das regras mais violadas e mal entendidas do C é a regra de strict aliasing que indica que valores com um tipo efetivo T1 não podem ser acessados por um ponteiro para um outro tipo T2.
As exceções para essa regra são :
- Se o tipo
T2forchar,signed charouunsigned char, pois os tipos de “caractere” são efetivamente considerados pela linguagem como tipos especiais próprios para manipular bytes. - O tipo
T1e o tipoT2são variações com e sem sinal do mesmo tipo. T1seja umastructonde o primeiro elemento é do tipoT2T1seja umunione o último elemento escrito nele seja do tipoT2, lembrando que acessá-lo por um ponteiro paraT2só será válido enquanto a ultima escrita emT1ainda for em um membro cujo tipo sejaT2.
No casos onde uma variável do tipo T1 é um union que contêm o tipo T2, mas o último elemento escrito nela não é do tipo T2, o acesso via ponteiro de T2 apontando para essa variável só pode ser realizado usando a própria variavel que é T1 ou um ponteiro para ela que seja do tipo T1.
O exemplo abaixo demonstra dois acessos, um inválido e um válido, seguindo essas regras:
//Inválido (tipos incompatíveis)
float a;
int *b = (int*)&a;
*b = 10;
//Válido (tipo T2 é um tipo de caractere)
float c;
char *d = (char*)&c;
*d = 10;
Fazer um cast do ponteiro de uma struct para o tipo do primeiro membro não viola o strict aliasing, esse mecanismo é normalmente utilizado para implementar o conceito de herança da programação orientada a objetos em C :
struct Animal {
int altura;
int idade;
};
struct Gato {
struct Animal base;
int raca; //Imagine que é um enum com a raça do gato
};
struct Gato gato;
(struct Animal*)&gato; //Essa conversão é permitida
A ideia inicial dessa regra foi permitir uma otimização que posteriormente poderia ser habilitada manualmente com a palavra chave restrict :
//Como "int" e "double" são tipos diferentes
//assume-se que "tam" e "arrdbl" apontam SEMPRE para endereços diferentes
void preencheDouble(int *tam, double *arrdbl, double valor)
{
//Neste caso, "tam" pode ser lido uma única vez da memória e guardado em cache
for(int i = 0; i < *tam; i++)
*arrdbl++ = valor;
}
//Como ambos tem o mesmo tipo
//O compilador não pode assumir que "tam" e "arrint" apontam para endereços diferentes
void preencheInteiro(int *tam, int *arrint, int valor)
{
//Neste caso, "tam" deve ser lido novamente a cada escrita em "arrint"
for(int i = 0; i < *tam; i++)
*arrint++ = valor;
}
A diferença parece incrivelmente sutil, mas essa regra permite que o compilador de C otimize acessos a tipos diferentes que atendam a ela assumindo que aliasing NUNCA acontecerá, ao mesmo tempo que permite que ele remova ou inultilize código que viole as regras de aliasing.
Em contrapartida, quando a regra não se aplicar, os compiladores de C são proibidos de realizarem esse tipo de otimização, dependendo do uso manual da palavra chave restrict.
Em alguns casos, a única forma de realizar um cast de ponteiros e ainda respeitar essa regra é realizar uma cópia dos dados via memcpy ou depender de extensões de compiladores, motivo pelo qual muitos desenvolvedores, inclusive Linus Torvalds o criador do Linux, criticam muito a existência e motivação da regra.
Lembrando que mesmo ao utilizar memcpy, muitos compiladores modernos consideram a função como uma operação inerente da linguagem e percebem sua intenção em usar ela no lugar de um cast, não realizando efetivamente uma cópia no código final, mas isso geralmente só acontece nas versões com otimização.
Em muitos compiladores, as otimizações relacionadas a aliasing podem não estar presentes nas versões de debug/desenvolvimento, portanto se escrevermos um código que viole essas regras, ele pode funcionar durante os testes mas falhar na versão final com otimizações.
Muitos compiladores também fornecem como extensão, uma forma de indicar “quando um ponteiro pode causar um aliasing proposital” ou opções de compilador como -fno-strict-aliasing que forçam o compilador a desconsiderar essa regra, o kernel do Linux e vários outros projetos usam essa opção e realizam controle manual dessa otimização pela palavra chave restrict.
Usos de ponteiros
Ponteiros podem ser utilizados para implementar uma série de funcionalidades e ao entender cada uma delas, teremos um entendimento mais completo do conceito de ponteiros.
Algumas das funcionalidades que podem ser implementadas com ponteiros :
- Passagem por referência
- Acesso a variáveis alocadas dinamicamente
- Parâmetros opcionais
- Múltiplos retornos
- Callbacks
Passagem por referência
O conceito de passagem de valor por referência envolve a forma como passamos variáveis a funções.
Sempre que passamos um parâmetro a uma função, consideramos que a função recebe uma “cópia” do parâmetro original, logo qualquer modificação na cópia não altera a variável original que foi copiada, chamamos isso de “passagem por valor”.
Podemos dizer que essa noção muda quando utilizamos ponteiro, pois ponteiros são capazes de modificar a variável original ao utilizarmos seu endereço.
Quando passamos um parâmetro a uma função, que permita que essa função leia ou modifique diretamente a variável original sem criar cópias, dizemos que essa é uma “passagem por referência”.
Exemplo de passagem de valor vs passagem por referência :
#include <stdio.h>
void modificaPorValor(int valor, int novoValor)
{
valor = novoValor;
}
void modificaPorReferencia(int *valor, int novoValor)
{
*valor = novoValor;
}
int main()
{
int teste = 5; //O valor original é 5
modificaPorValor(teste, 10); //Não consegue modificar, teste ainda é 5
printf("%d\n", teste);
modificaPorReferencia(&teste, 10); //Consegue modificar, teste agora é 10
printf("%d\n", teste);
}
Numa analogia simples, podemos pensar na situação onde queremos mostrar com detalhes uma foto a um amigo.
Uma “passagem por valor” envolveria enviar a foto pelo whatsapp, discord ou qualquer outra rede social para que ele tenha sua própria cópia.
Uma “passagem por referência” seria deixarmos ele segurar seu celular para que ele mesmo possa ver e dar zoom, mas isso também possibilita que nessa situação, ele apague a foto original.
Passagem por valor ou referência?
Entenda que, mesmo quando utilizamos uma “passagem por referência”, uma cópia ainda ocorre, mas o que é efetivamente copiado é o endereço, e não o valor da variavel.
Em muitos casos o uso de ponteiros para passsagem de referência é realizado pensando em evitar cópias dos valores, mas em alguns casos a passagem de valor pode ser mais eficiente do que a de referência.
O fator determinante reside no tamanho em bytes de um ponteiro junto do leve custo adicional de acessar o valor via uma indireção.
No geral, podemos começar considerar repassar um valor via ponteiro/referência como mais eficiente do que por valor quando :
sizeof(tipo) > sizeof(void*)
E consideramos que é recomendado que o valor seja passado via ponteiro quando :
sizeof(tipo) > (2 * sizeof(void*))
Importante lembrar que é muito comum passar variáveis com tipo struct via ponteiro devido a possibilidade de adicionarmos novos membros no futuro.
Acesso a variáveis alocadas dinamicamente
Aqui vai uma leve introdução ao assunto, que será explicado com detalhes em outro capítulo.
Na biblioteca stdlib.h existem as funções malloc, realloc e free que permitem um gerenciamento manual de memória, onde podemos solicitar uma quantia de bytes a ser utilizada pelo nosso programa e posteriormente devolver a quantia solicitada, para que possa ser reutilizada em outra solicitação ou por outros programas.
Ao utilizar alocação dinamica, recebemos efetivamente um ponteiro para um bloco de memória que esteja livre e tenha pelo menos o tamanho solicitado, a questão é que o local exato desse bloco é decidido na hora e provavelmente será diferente a cada execução do programa.
Logo, é impossível utilizar essa memória dinâmica sem utilizar ponteiros, pois precisamos de uma variável que possa guardar e acessar esse local “imprevisível” que conterá nossos dados.
Parâmetros opcionais com ponteiros nulos
É possível utilizar o valor de ponteiro nulo (com a constante NULL), para indicar um valor opcional ausente :
#include <stdlib.h>
#include <stdio.h>
//Entrada é um texto "opcional" que será imprimido antes de ler o terminal
int lerInteiro(const char *entrada) {
char linha[1024];
if(entrada != NULL)
fputs(entrada, stdout);
fgets(linha, sizeof(linha), stdin);
return (int)strtol(linha, NULL, 10);
}
O padrão é ideal para tipos que já são ponteiros, como strings, estruturas, etc.
O mesmo padrão poderia ser utilizado para tipos primitivos como inteiros e números de ponto flutuante, porém é muito difícil justificar essa escolha por dois motivos:
- Passar tipos primitivos via ponteiro é, no geral, menos eficiente.
- A necessidade de representar um valor “inválido” pode ser suprida ao reservar um dos possíveis valores (como por exemplo
0ou no caso de ponto flutuanteNaN) como o “valor inválido”.
Multiplos retornos
Algumas linguagens de programação permitem múltiplos retornos, um exemplo disso é a linguagem Python :
#Retorna o número e o nome da empresa
def telefoneEmpresa():
return 987317364, "Pedro Pneus"
Porém a linguagem C suporta apenas um único valor de retorno, há alguns motivos para tal :
- Aproxima a linguagem da implementação do retorno de funções nas arquiteturas de processadores e convenções de chamada (onde o resultado é geralmente colocado em um registrador específico).
- Aproxima a linguagem do sentido matemático de uma função, onde há sempre apenas um resultado.
Há três formas de burlar essa limitação :
- Encapsular os dados em um tipo
struct, que pode ser retornado diretamente (não é aconselhável para dados grandes, pois gera cópias custosas) - Passar um ou mais parâmetros “adicionais” como ponteiros, e fazer com que a função os preencha.
- Apesar de não recomendado, é possível utilizar variáveis globais para atingir o mesmo resultado.
A forma mais simples é utilizar ponteiros para preencher os parâmetros adicionais, levando até alguns autores a realizar uma separação entre parâmetros de entrada, saída ou entrada e saída.
#include <math.h>
/* Podemos considerar `r` como um parâmetro de saída
ele é um array de 2 elementos com as duas respostas da bhaskara */
bool bhaskara(double a, double b, double c, double *r)
{
double delta = b*b - 4*a*c;
if(delta < 0)
return false;
double raizDelta = sqrt(delta);
r[0] = (-b + raizDelta) / (2*a);
r[1] = (-b - raizDelta) / (2*a);
return true;
}
No caso citado acima, temos 3 retornos, um bool indicando sucesso/falha da bhaskara, e mais dois double em um array indicando a resposta da bhaskara.
Uma dica é agrupar os valores em
structou arrays, o que diminui a quantidade de ponteiros que precisam ser repassados a função.
Callback
Chamamos de callback uma função que é guardada numa variável para que possa ser executada posteriormente.
Na linguagem C, a forma efetiva de fazermos um callback é utilizando ponteiros de função, geralmente repassado como parâmetro a uma outra função.
Um exemplo bem comum é o uso das funções bsearch e qsort que utilizam uma função de parâmetro para realizar a operação de comparar elementos :
#include <stdlib.h>
#include <stdio.h>
#define ARRAY_SIZE(X) (sizeof(X)/sizeof(*X))
//Realiza comparação entre os valores
// (retornando 0 se iguais, positivo se v1>v2, negativo se v1<v2)
int compara_int(const void *v1, const void *v2)
{
const int *i1 = v1;
const int *i2 = v2;
return *i1 - *i2;
}
int main()
{
int lista[] = {20,30,40,50,10};
//qsort recebe um ponteiro para "compara_int" de parâmetro
// e chama a função internamente usada para ordenar os elementos
qsort(lista, ARRAY_SIZE(lista), sizeof(*lista), compara_int);
//Printa a lista ordenada
for(int i = 0; i < ARRAY_SIZE(lista); i++)
printf("%d ", lista[i]);
putchar('\n');
}
No geral callbacks são utilizados para :
- Efetuar uma ação quando algo ocorre ou após o termino de uma ação/processo (geralmente utilizado com bibliotecas e/ou funções do sistema).
- Ao enumerar informações, podemos utilizar callbacks para efetuar uma ação para cada informação obtida, sem a necessidade de montar uma lista (evitando alocações de memória).
- Permitir uma flexbilização maior, onde a responsabilidade de especificar como algo será feito é repassada ao usuário (como é o caso da função de comparação do
qsortebsearch).
Strings
Strings, no português chamadas de “cadeias de caracteres”, são variáveis que guardam textos, estes que podem ser utilizados para praticamente qualquer coisa, desde nomes, comandos, expressões matemáticas, configurações, etc.
Em muitas linguagens de programação de alto nível, strings são consideradas como um tipo “separado” de dados, geralmente são imutáveis (modificar uma string significa gerar uma nova string, permitindo que strings sejam repassadas por referência de forma “segura”).
Na linguagem C, não existe especificamente um “tipo string”, strings são arrays de caracteres, geralmente repassada via ponteiro como const char* para strings não modificáveis, ou char* para strings que podem ser modificadas.
Mas ai fica a pergunta, se passarmos um único const char* como vamos saber o tamanho do array ?
A resposta é que, geralmente, utiliza-se o caractere nulo '\0' que na prática, tem o valor 0. Consideramos que uma string “acabou” quando, ao ler um caractere, ela tem valor igual a \0.
Logo uma string declarada como :
"Hello World\n"
Será na prática, um array que contenha :
'H' 'e' 'l' 'l' 'o' ' ' 'W' 'o' 'r' 'l' 'd' '\n' '\0'
Dessa forma, poderiamos fazer um código que “descobre” o tamanho de uma string, lembrando que na prática a função strlen da biblioteca string.h é muito mais otimizada:
#include <stdlib.h>
#include <stdio.h>
int tamanhoString(const char *str)
{
const char *c = str;
while(*c != '\0')
c++;
return (c - str);
}
int main()
{
int tam = tamanhoString("abcdefghij");
printf("A string tem tamanho %d\n", tam);
}
Como strings são apenas “ponteiros para arrays” existem várias operações que podem ser realizadas com elas :
"25" + 1 // "5" (avança um caractere)
"comida"[3] // 'm' (pega o 4° caractere)
*"abc" // 'a' (pega o 1° caractere)
[1]"BIFE" // 'I' (pega o 2° caractere)
//Descontamos 1 por causa do \0 em "Hello "
//"World" (pula a frase "Hello ")
"Hello World" + sizeof("Hello ") - 1
Literais de strings
Quando escrevemos uma string diretamente como no exemplo abaixo :
char *teste1 = "Ola, mundo!";
const char *teste2 = "Ola, como vão?";
char *teste3 = "Ola, mundo!";
const char *teste4 = "Ola, como vão?";
Temos uma string “literal”, que inicialmente é um array com o tamanho da string (lembrando que há uma reserva de 1 byte para o \0) mas que pode ser implicitamente convertido para um ponteiro e será trocado para um array constante ou não constante dependendo da variável que o recebe.
Em qualquer um dos casos o compilador provavelmente terá a string inteira já guardada dentro do executável, para que ela seja alocada junto da inicialização do programa, tornando tudo mais eficiente.
No caso do teste1, como não temos um ponteiro constante, o compilador provavelmente colocará a string numa região com permissão de escrita e será obrigado a reservar uma cópia separada para teste3 caso não consiga garantir que nenhum dos dois modificou a string.
No caso do teste2, como o ponteiro aponta para um dado constante, o compilador provavelmente colocará a string numa região de apenas leitura, de forma que o programa seja finalizado caso alguém tente modificar a string em teste2, a variável teste4 receberá uma referência para a mesma string, pois como ela é imutável, podendo ser reutilizada, diminuindo o uso de memória.
Sobre strings literais, também é interessante mencionar que strings separadas apenas por espaços/nova linha, são consideradas como parte da mesma string :
#define PASTA_RECURSOS "/home/pi/resources"
PASTA_RECURSOS "/imagem1.png" //Este texto
"/home/pi/resources/imagem1.png" //É igual a este
//Este texto
"como vai\n"
"você?\n"
//É igual a este
"como vai\nvocê?\n"
Para digitar aspas e outros caracteres especiais numa string literal, utilizamos a mesma sintaxe das sequências de escape descritas no capítulo sobre caracteres.
Encoding
Antes de falar sobre os tipos de strings literais, precisamos falar sobre encodings.
Encoding, no contexto de strings (que seria “codificação” em português), é o padrão no qual decidimos quais códigos númericos utilizamos para indicar cada caractere, no geral todo encoding moderno extende o padrão ASCII, de forma que os códigos númericos 0 a 127 definidos no padrão ASCII ainda representem os mesmos caracteres.
Antes de contiinuar, é importante também entender o termo code unit que simboliza um dos números utilizados para representar um caractere, em alguns casos, mais de um número é utilizado para representar um único caractere, houvendo uma distinção entre code unit vs caracteres (em aalguns encodings, um caractere pode ser formado por mais de um code unit).
Um resumo da história dos Encodings
O padrão ASCII era relativamente limitado, pois não suportava acentuações, caracteres japoneses, chineses, etc. Foi ai que surgiram diferentes codificações que buscavam adicionar mais caracteres ao padrão ASCII.
Vários padrões surgiram extendendo ASCII, como Latin-1, Shift-JIS, entre outros. O problema é que essas novas codificações não conversavam entre sí, de forma que não fosse possível codificar um caractere japonês em Latin-1 e não haja acentuação em Shift-JIS e um mesmo valor númerico representasse coisas diferentes em cada codificação.
Para solucionar o problema dos formatos incompatíveis, surgiu o padrão conhecido como Unicode, que buscava uma representação universal para todo e qualquer caractere.
Foi então que, em 1993, surgiram as codificações UCS-2 e UCS-4, usando respectivamente 16bits e 32bits para representar caracteres e sem nenhum mecanismo para usar mais de um code unit por caractere, muitos acreditaram que 16bits seria o suficiente para representar todos caracteres, levando a grande adoção do padrão UCS-2, inclusive de várias gigantes da tecnologia como Apple (MacOs, iOs), Sun (Java), Microsoft (Windows) que participavam do consórcio Unicode que definia os padrões Unicode.
UTF-8, surgiu em 1993, é um formato compatível com ASCII puro que usa 8bits porcode unit, podendo ter de 1 a 4code unitspor caractereUTF-16, surgiu em 1996 como uma solução para aqueles que adotaramUCS-2, é um formato que usa 16bits porcode unit, podendo ter de 1 a 2code unitspor caractereUTF-32, é um sinônimo do formatoUCS-4, onde cadacode unitocupa 32bits e representa qualquer caractere
É por estes motivos históricos, a grande adoção de UCS-2, que ainda hoje, muitos softwares e linguagens de programação utilizam UTF-16, mesmo que o formato UTF-8 seja mais compacto e eficiente. Agravado pelo fato que muitos sistemas e linguagens novas escolhem usar UTF-16 ainda hoje, pelo simples fato que sistemas com os quais eles desejam comunicar ou operar ainda estão usando UTF-16.
Unicode
Os caracteres do padrão Unicode são dividos em “planos” e “blocos”, cada plano é uma divisão de 65536 valores divididos em vários “blocos” que servem como categorias.
O valor númerico de caracteres Unicode geralmente são expressados com o prefixo U+ seguido de um número em hexadecimal, logo U+00A0 representa o caractere Unicode cujo código númerico é o número hexadecimal A0, esses valores são denominados code points.
A faixa de valores do Unicode é definido como de U+0000 até U+10FFFF, utilizando efetivamente 21 bits. Um site bom para consultar os caracteres disponíveis no Unicode é o Compart.
Inclusive, por questões de compatibilidade, os valores na faixa de U+0000 até U+00FF representam os mesmos caracteres do encoding Latin-1.
Todos os encodings que respeitam o padrão Unicode, tentam representar os mesmos valores númericos. Logo, o que muda entre os diferentes encodings é a forma de extrair o valor númerico ou como ocorre no caso do UCS-2 (que é considerado obsoleto), uma impossibilidade de representar todos caracteres.
UTF-8
O formato UTF-8 codifica os valores dos codepoints Unicode da seguinte forma (considerando U+uvwxyz) :
| Faixa de codepoints | Byte 1 | Byte 2 | Byte 3 | Byte 4 |
|---|---|---|---|---|
| U+0000 até U+007F | 0yyyzzzz | |||
| U+0080 até U+07FF | 110xxxyy | 10yyzzzz | ||
| U+0800 até U+FFFF | 1110wwww | 10xxxxyy | 10yyzzzz | |
| U+010000 até U+10FFFF | 11110uvv | 10vvwwww | 10xxxxyy | 10yyzzzz |
Nem todos os bits de cada byte são utilizados como valor efetivo, isso permite uma retrocompatibilidade com ASCII. Permitindo que você busque por caracteres ASCII como \n usando funções como strchr dentro de uma string UTF-8, sem medo de cair num pedaço que é usado para representar um caractere que precisa de 2,3 ou 4 bytes.
Para iterar “por caracteres” em uma string UTF-8, devemos extrair os codepoints da string, o código abaixo implementa isso :
#include <stdio.h>
#include <uchar.h>
#ifdef _WIN32
#include <Windows.h>
#endif
/* Extrai um codepoint e avança a string para o próximo caractere */
static char32_t utf8_next_codepoint(const char **text)
{
const char* ptr = *text;
char32_t codepoint = '\0';
int size;
if ((ptr[0]&0xF8) == 0xF0) {
if (((ptr[1]&0xC0)^0x80) || ((ptr[2]&0xC0)^0x80) || ((ptr[3]&0xC0)^0x80))
return codepoint;
codepoint = ((ptr[0]&0x07) << 18) | ((ptr[1]&0x3F) << 12) |
((ptr[2]&0x3F) << 6) | (ptr[3]&0x3F);
size = 4;
} else if ((ptr[0]&0xF0) == 0xE0) {
if (((ptr[1]&0xC0)^0x80) || ((ptr[2]&0xC0)^0x80))
return codepoint;
codepoint = ((ptr[0]&0x0F) << 12) | ((ptr[1]&0x3F) << 6) | (ptr[2]&0x3F);
size = 3;
} else if ((ptr[0]&0xE0) == 0xC0) {
if ((ptr[1]&0xC0)^0x80)
return codepoint;
codepoint = ((ptr[0]&0x1F) << 6) | (ptr[1]&0x3F);
size = 2;
} else {
codepoint = ptr[0];
size = 1;
}
*text += size;
return codepoint;
}
/* Converte o codepoint para UTF-8 */
static int codepoint_to_utf8(char32_t codepoint, char *utf8)
{
int size;
if(codepoint <= 0x007F) {
utf8[0] = (char)codepoint;
size = 1;
} else if(codepoint <= 0x07FF) {
utf8[0] = 0xC0 | (codepoint >> 6);
utf8[1] = 0x80 | (codepoint & 0x3F);
size = 2;
} else if(codepoint <= 0xFFFF) {
utf8[0] = 0xE0 | (codepoint >> 12);
utf8[1] = 0x80 | ((codepoint >> 6) & 0x3F);
utf8[2] = 0x80 | (codepoint & 0x3F);
size = 3;
} else if(codepoint <= 0x10FFFF) {
utf8[0] = 0xF0 | (codepoint >> 18);
utf8[1] = 0x80 | ((codepoint >> 12) & 0x3F);
utf8[2] = 0x80 | ((codepoint >> 6) & 0x3F);
utf8[3] = 0x80 | (codepoint & 0x3F);
size = 4;
} else {
size = 0;
}
return size;
}
int main()
{
#ifdef _WIN32 /* Necessário no Windows para configurar
saída do terminal para UTF-8 */
SetConsoleOutputCP(CP_UTF8);
#endif
const char *text = (u8"💻: Olá humano");
char32_t codepoint;
while(codepoint = utf8_next_codepoint(&text)) {
char utf8[5] = {0}; //4 bytes no máximo por codepoint + '\0'
codepoint_to_utf8(codepoint, utf8);
printf("%s = U+%04X\n", utf8, codepoint);
}
}
UTF-16
O formato UTF-16 é similar ao UTF-8, porém utiliza 16bits por code unit. A principal vantagem para uso do UTF-16 é que na maioria dos casos, os caracteres usados para suportar múltiplas línguas fazem parte do plano Unicode BMP (Basic Multilingual Plane, ou no português Plano Multilíngue Básico) que podem ser representados por um único code unit em UTF-16, permitindo que na maioria dos casos, a quantidade de code units seja igual a quantidade de code points.
Porém, como na maioria dos casos os caracteres mais utilizados são os presentes no padrão ASCII, o formato UTF-8 acaba sendo mais eficiente na maior parte dos casos, exceto na representação de alguns caracteres japonêses e chineses, onde o formato UTF-8 usa 3 bytes e o UTF-16 usa 2.
Para representação dos codepoints Unicode, o UTF-16 utiliza as seguintes conversões :
Valores na faixa U+0000 até U+D7FF e na faixa U+E000 até U+FFFF são representados por um único code unit em UTF-16, a faixa U+D800 até U+DFFF tem um propósito especial.
Para representar valores na faixa de U+010000 até U+10FFFF são utilizados o que chamamos de par substituto (ou no inglês “surrogate pair”), onde seguimos a sequência de decodificação :
0x10000é subtraido docodepoint, de forma que sobre um número de 20bits na faixa de0x00000–0xFFFFF.- Os 10 bits mais significativos desse número (na faixa
0x000-0x3FF) são adicionados ao número0xD800para formar o primeirocode unitna faixa0xD800-0xDBFF - Os 10 bits menos significativos desse número (na faixa
0x000-0x3FF) são adicionados ao número0xDC00para formar o segundocode unitna faixa0xDC00-0xDFFF
#include <stdio.h>
#include <uchar.h>
static char32_t utf16_next_codepoint(const char16_t **text)
{
const char16_t* ptr = *text;
char32_t codepoint = '\0';
if(*ptr <= 0xD7FF || *ptr >= 0xE000) {
codepoint = *ptr;
*text += 1;
} else if(*ptr >= 0xD800 && *ptr <= 0xDBFF) { //UTF16LE (little endian)
codepoint = 0x10000 + ((*ptr - 0xD800) << 10) + (ptr[1] - 0xDC00);
*text += 2;
} else if(*ptr >= 0xDC00 && *ptr <= 0xDBFF) { //UTF16BE (big endian)
codepoint = 0x10000 + ((*ptr - 0xDC00) << 10) + (ptr[1] - 0xD800);
*text += 2;
}
return codepoint;
}
int main()
{
const char16_t *text = u"💻: Olá humano";
char32_t codepoint;
while(codepoint = utf16_next_codepoint(&text))
printf("Codepoint = U+%04X\n", codepoint);
}
UTF-32
O formato UTF-32 é bastante simples, todos seus code units representam exatamente um codepoint Unicode, logo ele tem exatamente os mesmos valores e não há necessidade de conversão.
Podemos dizer que o UTF-32 seria basicamente o UTF-8 ou UTF-16 “descomprimido”, onde a única vantagem é o acesso O(1) a qualquer caractere, dado um array de caracteres em UTF-32, com a desvantagem do uso de memória adicional, que pode também prejudicar a performance.
O formato se tornou sinônimo de UCS-4, pois na época da formulação o UCS-4 era definido como tendo até 31bits reservados para caracteres, enquanto o UTF-32 foi concebido tendo a faixa de valores U+0000 até U+10FFFF de 21bits, mais tarde ambos foram padronizados como sinônimos (onde UCS-4 passou a ter a mesma definição).
Tipos de strings literais
Existem 5 tipos diferentes de string literais no C :
"T1" //String literal
u8"T2" //String literal UTF-8 (C11)
u"T3" //String literal UTF-16 (C11)
U"T4" //String literal UTF-32 (C11)
L"T5" //String literal "wide"
String literal: Uma string literal padrão, utiliza um encoding definido pelo compilador, mas geralmente usa exatamente o mesmo encoding usado no arquivo de texto onde o código fonte se encontra, tem tipochar[N].String literal UTF-8 (C11): Uma string literal que é sempre em UTF-8, independente do compilador, tem tipochar[N](ouchar8_t[N]noC23).String literal UTF-16 (C11): Uma string literal que é sempre em UTF-16, independente do compilador, tem tipochar16_t[N].String literal UTF-32 (C11): Uma string literal que é sempre em UTF-32, independente do compilador, tem tipochar32_t[N].String literal "wide": Uma string literal longa, com encoding definido pelo compilador, no geral éUTF-32em sistemas baseados em Unix eUTF-16no Windows, tem tipowchar_t[N].
Inicialização de strings
Podemos também utilizar strings literais para inicializar arrays :
#include <string.h>
char arr[] = "Abc"; //Neste caso, arr tem tamanho 4, com 'A','b','c','\0'
const char str2[] = "def"; //Podemos inicializar arrays constantes também
char str3[10];
str3 = "abcdef" //Errado, isso só funciona na inicialização
//Essa é uma das formas de copiar a string (usando a função strcpy)
strcpy(str3, "abcdef");
//Ou com a própria função memcpy
memcpy(str3, "abcdef", sizeof("abcdef"));
//Neste caso, temos 'g','h','i','\0' no conteúdo, porém temos mais espaço reservado
//para expandir e colocar mais coisas na string caso necessário...
char str4[20] = "ghi";
//Também podemos inicializar estruturas com strings literais...
struct {
char *txt1;
int i1;
} teste = {"Ola", 0};
Segurança das funções de strings
Devido a falta de consideração pela segurança no design inicial da linguagem C, existem muitas funções que são consideradas “não ideais” para tratar strings pois são suscetíveis a erros, para isso alguns projetos como git ou engenheiros de segurança da Microsoft mantêm um header com uma lista de funções “banidas”, que causa um erro de compilação caso alguém tente usar elas.
Utilizar essas funções não necessariamente significa que você tem um problema de segurança, mas basta um erro no seu uso para elas se TORNAREM um problema de segurança.
Annex K
Vale lembrar que no C11 a Microsoft empurrou a criação de versões “seguras” de muitas funções no chamado Annex K (Anexo K, o nome da parte do documento do padrão do C11 especificando sobre estas novas funções), essas funções tem o sufixo _s e nomes muito parecidos com as funções padrões do C.
Porém a implementações das funções adicionadas no Annex K são opcionais, e estarão apenas presentes se a macro __STDC_LIB_EXT1__ existir e o usuário definir __STDC_WANT_LIB_EXT1__ para 1 antes de incluir string.h ou outra biblioteca, no geral o Annex K é considerado um fiasco pois foi baseadas em implementações da Microsoft que foram posteriormente modificadas, de forma que nem mesmo a própria Microsoft siga o padrão e muitos compiladores simplesmente se recusaram a implementar as funções descritas pois elas são opcionais.
Algumas materias, em inglês, com explicações mais a fundo sobre o Annex K :
No geral muitos criticaram muitas funções do Annex K pois :
- Já existem outras soluções feitas por usuários/bibliotecas que são mais efetivas, simples e seguras
- É muito difícil fazer testes automatizados de código utilizando as funções
_s - Não é fácil de integrar as funções novas com código que usa as funções antigas
- As funções inerentemente diminuem a performance ao realizar checagens extensas e possivelmente redundantes
Funções de manipulação de strings
Vamos apresentar rapidamente uma lista com as funções de strings recomendadas para cada ação, visando usabilidade e segurança, colocando Sim nos casos onde a função padrão é suficiente, Não nos casos que demandam explicações ou o nome da uma outra função quando ela é mais recomendada :
| Ação | Padrão | Wide | Recomendado |
|---|---|---|---|
| Copiar string | strcpy | wcscpy | strlcpy |
| Buscar caractere | strchr | wcschr | Sim |
| Concatenar strings | strcat | wcscat | strlcat |
| Comparar strings | strcmp | wcscmp | Sim |
| Tamanho de string | strlen | wcslen | Sim |
| Achar substring | strstr | wcsstr | Sim |
No caso de copiar strings, a função strcpy geralmente é substituida pela strlcpy, o git por exemplo usa essa função dessa forma e mantêm uma implementação própria caso a função não esteja disponível (pois ela não é padrão no C):
size_t gitstrlcpy(char *dest, const char *src, size_t size)
{
size_t ret = strlen(src);
if (size) {
size_t len = (ret >= size) ? size - 1 : ret;
memcpy(dest, src, len);
dest[len] = '\0';
}
return ret;
}
A função strlcat também não é padrão, mas existe em alguns distribuições assim como a strlcpy, caso ela não exista, podemos ter nossa própria implementação :
size_t strlcat(char *dest, const char *src, size_t size)
{
if(size == 0)
return 0;
size_t destsize = strlen(dest);
size_t ret = 0;
if(destsize < size)
ret = strlcpy(dest + destsize, src, size - destsize);
return ret;
}
Para versão wide, podemos checar se as funções wcslcpy ou wcslcat existem, caso contrário podemos utilizar as implementações sugeridas, trocando os tipos char por wchar_t e a variável len no memcpy por len * sizeof(wchar_t).
Iteração com strings
É comum que iniciantes que vieram de outras linguagens de alto nível iterem sobre strings de forma ineficiente em C.
Uma implementação que normalmente podemos ver é :
for(int i = 0; i < strlen(str); i++) {
str[i]; //Caractere
}
Observe que a função strlen é chamada a cada iteração, isso é extremamente ineficiente, pois cada chamada de strlen itera a string inteira até achar o caractere \0 que é o finalizador.
Em linguagens alto nível é comum que string seja uma classe que já contêm o tamanho como uma de suas propriedades, tornando essa operação eficiente, o que não é o caso com as strings padrão do C.
Uma forma muito mais simples e muito mais eficiente de iterar sobre strings em C :
for(const char *c = str; *c; c++) {
*c; //Caractere
}
Nesse caso temos um ponteiro que acessa cada caractere, avançando uma posição a cada iteração e que para quando chega no caractere \0 (*c é Falso quando chega no valor \0).
Também podemos implementar de forma similar, utilizando indices :
for(int i = 0; str[i]; i++) {
str[i]; //Caractere
}
Localidade
Na biblioteca locale.h temos a função setlocale que permite a mudança da localidade do ambiente de execução da linguagem C, essa mudança pode ser completa ou parcial.
A função setlocale tem a seguinte sintaxe
char *setlocale(int categoria, const char *locale);
Onde a categoria indica flags que são utilizadas para selecionar a categoria que será modificada :
LC_ALL: Todas as categorias são modificadas (inclusive categorias que não são padrão)LC_COLLATE: Afeta comparação e transformações de strings adaptadas aos requisitos do idioma específico (afetastrcollestrxfrm)LC_CTYPE: Afeta o resultado das funções da bibliotecactype.hque classificam caracteres (isalpha,isdigit, etc)LC_MONETARY: Afeta a formatação de unidades monetárias (afeta apenaslocaleconv)LC_NUMERIC: Afeta a formatação númerica (afetaprintf,scanf,strtod,strtof, etc)LC_TIME: Afeta a formatação de tempo (afetastrftime)LC_MESSAGES: Presente apenas em sistemas POSIX, afeta o idioma das mensagens de erro fornecidas porstrerroreperror
locale é uma string que identifica as configurações de localidade com formato não definido pelo padrão do C, mas que segue o seguinte formato tanto no linux quanto no Windows:
idioma[_território][.encoding]
Onde (considere os campos com [] como opcionais) :
idiomaé um dos códigos da ISO 639 no Linux e segue uma lista específica no Windows.territórioé um dos códigos de países da ISO 3166 no Linux ou segue uma lista específica no Windows.encodingé um texto específico de plataforma identificando o encoding utilizado, no geral o aconselhável é utilizar sempreutf8que é o modo mais portável, no Windowsencodingpode ser o número do código de página ouACPpara o código de página atual do usuário e no Linux o nome do encoding .
Podemos checar a lista de opções de locale no Linux executando o comando locale -a no terminal.
Lembrando que o encoding utf8 só é suportado desde o Windows 10 e para que ele funcione devemos utilizar o ambiente de execução UCRT (Universal C Runtime) que é um ambiente de execução mais moderno para C no Windows ao invés do clássico mingw que usa a biblioteca de vínculo dinâmico msvcrt.dll.
Ainda assim, mesmo quando utilizamos o locale de utf8, no Windows a conversão que ocorre é encoding do C -> encoding do terminal -> UTF-16, de forma que mesmo definindo corretamente o locale como utf8, ainda estamos limitados aos caracteres suportados pelo encoding atual do terminal, que pode ser modificado utilizando a função SetConsoleOutputCP (muda o encoding da saída do terminal) e SetConsoleCP (muda o encoding da entrada do terminal).
Por padrão, o locale inicialmente configurado é equivalente a setlocale(LC_ALL, "C"), ao utilizar "C" estamos indicando o locale padrão que tem um comportamento consistente em todos os ambientes, podemos também utilizar uma string vazia "" para indicar que queremos utilizar o locale do sistema, que geralmente é controlado pelas configurações do sistema operacional e variáveis de ambiente. Para obter a configuração de locale atual, basta utilizar NULL na configuração do locale.
Além disso, há uma função chamada localeconv que retorna um ponteiro do tipo struct lconv, que contém diversas variáveis com detalhes sobre formatação de unidades monetárias e números associados a configuração da localidade atual.
Strings de múltiplos bytes
O formato de string considerado como atual pelo ambiente de execução da linguagem C depende da configuração definida com setlocale, alguns encodings podem utilizar mais de um byte por caractere, neste caso, há funções da biblioteca padrão que reconhecem esse detalhe e lidam especificamente com ele.
As strings que se encaixam nessa categoria são mencionadas como strings de múltiplos bytes, ou no inglês “multi-byte strings” (identificadas pelo prefixo mb nas funções da biblioteca padrão), é possível obter o maior número de bytes que um caractere pode precisar no formato de string atual através da macro MB_CUR_MAX.
Podemos utilizar as funções iniciando em mbrto para converter um caractere multi byte para diversos formatos como UTF-8 (C23), UTF-16 (C11), UTF-32 (C11) ou wchar_t.
A iteração sobre strings de múltiplos bytes normalmente envolve o tipo mbrstate_t que é capaz de guardar o estado atual da conversão, isso acaba sendo necessário pois alguns formatos usam códigos especiais para trocar o significado dos outros caracteres (como o encoding japonês Shift-JIS).
É recomendável que o usuário evite funções que não utilizam mbrstate_t mas tem uma contraparte que aceita, como por exemplo a função mblen que idealmente deve ser substituida por mbrlen, pois essas funções geralmente dependem de um estado global, o que acaba por causar conflitos ao utilizar em conjunto com múltiplos threads ou problemas ao utilizar as funções de forma incorreta.
Diferentes representações de String
Neste campo vamos falar sobre algo um pouco avançado, as diferentes implementações para representar strings em várias linguagens, incluindo C e até mesmo bibliotecas renomadas que buscam algo mais eficiente, destacando os pontos positivos e negativos de cada formato.
Alguns termos, que precisam de explicação, serão reutilizados ao longo das explicações :
- Localidade de cache : Indica que os dados estão próximos na memória, logo o acesso a string está efetivamente acessando apenas um local da memória para conseguir o tamanho e os dados da string, o que pode ajudar na performance.
- Evita realocações : Geralmente quando a string tem um campo indicando o tamanho realmente reservado para string, permitindo concatenações sem realocar a memória reservada.
- Dificuldade de gerar substrings : A facilidade de pegar um pedaço de uma string e usar ele como uma nova string, útil em diversas situações.
Bom, como já explicado neste guia, a linguagem C utiliza strings terminadas com \0, sendo necessário percorrer a string para obter o tamanho.
Vantagens :
- Localidade de cache
- Leve nos casos onde saber o tamanho antecipadamente não é necessário
- Utilizada em chamadas de sistemas
- É o formato que usa menos memória para representação de strings
Desvantagens:
- Usa
strlenpara obter tamanho, operaçãoO(n) - Dificil de obter substrings
- Pode ser necessário realocar para concatenar
Literais
Literais são valores de um determinado tipo que podem ser escritos diretamente no código fonte.
Diferente da crença de alguns, TODOS valores literais, sem exceção, tem um tipo.
Logo até mesmo escrever números diretamente no código fonte como 1, implicam um tipo de variável que é decidido de acordo com algumas regras.
Literais de caracteres
Os literais de caracteres já foram explicados no capítulo sobre caracteres.
Vamos apenas recapitular os tipos :
'A' // char
L'A' // wchar_t
u'A' // char16_t (C11)
U'A' // char32_t (C11)
u8'A' // char8_t (C23)
Literais de inteiros
Em literais de inteiros, os prefixos são utilizados para determinar a base númerica (decimal, hexadecimal, binário, octal) enquanto os sufixos são utilizados para determinar os tipos (unsigned int, int, long, long long, etc).
Prefixos:
| Prefixo | Base Númerica | Exemplo |
|---|---|---|
| Nenhum | Decimal | 1 |
0 | Octal | 01 |
0x ou 0X | Hexadecimal | 0x1 |
0b ou 0B | Binário (C23) | 0b1 |
Sufixos:
| Sufixo | Tipo / Modificador |
|---|---|
| Nenhum | int |
U ou u | unsigned |
L ou l | long |
LL ou ll | long long (C99) |
wb ou WB | _BitInt(N) (C23) |
Os sufixos de tipo podem ser utilizados juntos com o sufixo U que indica que o tipo não tem sinal.
Aconselha-se o uso do sufixo U antes dos outros sufixos (UL para unsigned long ao invés de LU), pois antes do C23 utilizar o sufixo U por último em conjunto com outro sufixo não estava no padrão da linguagem.
No caso do sufixo WB, teremos um _BitInt(N) onde N é o menor número de bits necessários para representar o valor, este sufixo também pode ser utilizado em conjunto com U.
Vale lembrar que não existem “literais de inteiros negativos”, todos literais inteiros SEMPRE são positivos, existem duas formas de conseguir um valor negativo:
//Colocar um menos na frente (convertendo-o para negativo)
-5;
//Realizar uma conversão implicita ou explicita para um tipo com sinal
(signed char)0xFF;
Todos literais de inteiros podem ser “promovidos” para tipos maiores, caso o valor escrito esteja “acima” dos limites, mas há algumas diferenças de comportamento :
- Todos literais de tipos sem sinal só podem ser promovidos para tipos sem sinal (
unsigned int->unsigned long->unsigned long long) - Antes do
C99literais decimais de tipos com sinal poderiam ser promovidos até o tipounsigned longcasolongnão fosse o suficiente para representar o valor. - Desde o
C99, literais decimais de tipos com sinal só podem ser promovidos para tipos com sinal (int->long->long long). - Literais com prefixo (binário, octal ou hexadecimal) sem o sufixo
Upodem ser promovidos para tipos sem sinal (int->unsigned int->long->unsigned long->long long->unsigned long long).
Para o exemplo abaixo, vamos considerar int como 16bits, long como 32bits e long long como 64bits :
2147483648; //(Pre-C99) unsigned long
//(C99) long long
//32768 é 0x8000 em decimal
32768; //long
0x8000; //unsigned int
0x1FFFF; //long
Desde o C23 também podemos utilizar o caractere ' como separador opcional entre digitos (que será ignorado pelo compilador) :
int reais = 29'99;
Devido a forma como os compiladores são implementados, utilizar um número hexadecimal terminando em E seguido do operador + ou - causa um erro de compilação:
0xE+2; //Errado
0xE + 2; //Correto
Literais de ponto flutuante
Nos literais de ponto flutuante, temos a seguinte sintaxe :
prefixo numero . fracao expoente sufixo
Assim como nos literais de ponto flutuante, o prefixo determina a base númerica (decimal ou hexadecimal) enquanto o sufixo controla o tipo (float, double ou long double), enquanto o expoente pode ser utilizado para facilitar a escrita de alguns números.
Prefixos :
| Prefixo | Base Númerica | Exemplo |
|---|---|---|
| Nenhum | Decimal | 1.0 |
0x ou 0X (C99) | Hexadecimal | 0x1p0 |
Expoentes :
| Expoente | Multiplica-se por | Exemplo |
|---|---|---|
| Nenhum | Inalterado | 1.0 |
e ou E | 10 elevado a X | 1e-1 |
p ou P (C99) | 2 elevado a X | 0x1p1 |
Sufixos :
| Sufixo | Tipo |
|---|---|
| Nenhum | double |
F ou f | float |
L ou l | long double |
df ou DF | _Decimal32 (C23) |
dd ou DD | _Decimal64 (C23) |
dl ou DL | _Decimal128 (C23) |
Algumas regras a respeito dos literais de ponto flutuante:
- O expoente
eouEsó pode ser utilizado em literais decimais, mas é opcional. - O expoente
pouPsó pode ser utilizado em literais hexadecimais, e é obrigatório (0x1féint, mas0x1p0féfloat). - O sufixos para tipos
_DecimalXnão podem ser utilizado com o prefixo de hexadecimal. - Literais decimais de ponto flutuante precisam ter o expoente
e/Eou um ponto (e3é inválido,1e1é válido,.1é válido).
Exemplo demonstrando vários literais diferentes :
.05L; //long double
1; //int
1.0; //double
0x1p1; //double, tem valor = 2 (1 * 2 elevado a 1)
1ef; //inválido
1e0f; //float
0x1e3; //int
0x2p-1; //double, tem valor = 1 (2 * 2 elevado a -1)
123.45dd; //_Decimal64 (C23)
Assim como em literais de inteiros :
- Podemos utilizar
'noC23como separador entre digitos em literais de ponto flutuante (eles serão ignorados pelo compilador). - Não existem literais de ponto flutuante negativos, eles são “gerados” usando o operador
-.
No geral operações aritméticas são realizadas levando em consideração o tipo da variável, o que pode levar o usuário ao erro :
double a = 5 / 2; //2 (int/int = divisão de inteiro)
double b = 5 / 2.0; //2.5 (int/double = divisão com double)
//Considerando int 32bits e complemento de 2
//O valor resultante será -2147483648 devido a um overflow
double c = 2147483648 + 1; //-2147483648 (int + int)
double d = 2147483648.0 + 1; //2147483649 (double + int)
Literais de string
As literais de string já foram explicadas no capítulo sobre strings, mas aqui vamos relembrar os tipos existentes :
"T1" //char*
u8"T2" //char* (C11) ou char8_t* (C23)
u"T3" //char16_t* (C11)
U"T4" //char32_t* (C11)
L"T5" //wchar_t*
Literais extras
Desde o C23 :
trueefalseforam introduzidos como palavras chave da linguagem e tem efetivamente o tipobool, ondetrueé implicitamente convertido para1efalseimplicitamente convertido para0quando repassado a um tipo inteiro.nullptrfoi introduzido como palavra chave da linguagem e tem efetivamente o tiponullptr_t, que pode ser implicitamente convertido para um ponteiro nulo de qualquer tipo de ponteiro.
Literais Compostos
Desde o C99, podemos escrever literais compostos, que são utilizados para escrever valores literais para qualquer tipo que podem ser usados como lvalue.
lvalue vem de “left value”, ou seja, “valor a esquerda”, indicando que podemos atribuir valores a expressão e seu endereço pode ser utilizado.
A sintaxe para definição de literais compostos é similar a inicialização de arrays e structs :
(modificadores tipo){lista de inicialização}
- Desde o
C23, podemos adicionar osmodificadores:constexpr,static,registerouthread_local. - Em
tipopodemos colocar qualquer tipo que não seja um array de tamanho variável, não é necessário inicializar o array. - Na
lista de inicializaçãopodemos colocar um ou mais valores separados com virgula que inicializam o tipo descrito, desde oC23podemos deixar essa lista vazia, tendo uma inicialização similar a de arrays e estruturas (campos não preenchidos viram 0).
Exemplo de uso para criar um array de strings e outro de inteiros :
#include <stdlib.h>
#include <stdio.h>
//É relativamente comum utilizar um ponteiro NULL
//para indicar o "fim" de um array de strings
void escreveStrings(const char **strings)
{
while(*strings) {
printf("%s\n", *strings);
strings++;
}
}
void escreveNumeros(int *numeros, unsigned int tam)
{
while(tam--)
printf("%d\n", *numeros++);
}
int main()
{
escreveStrings((const char*[]){"Ola","Como","Vai","Voce?", NULL});
escreveNumeros((int[]){1,2,3,4}, 4);
}
Também podemos utilizar inicializadores designados para inicializar um literal composto.
O exemplo abaixo demonstra vários literais compostos :
//Pegando endereço de um literal composto
char *test = &(char){'A'};
struct GString gstr;
//É possível utilizar literais compostos para atribuir uma estrutura
//Permitindo uma atribuição com sintaxe similar a inicialização!
gstr = (struct GString) {
.str = "Tutorial",
.len = sizeof("Tutorial"),
.allocated_len = sizeof("Tutorial")
};
// Inicializadores designados, outros elementos serão 0, array terá tamanho 8
(int[]) {
[1] = 5,
[3] = 10,
[5] = 15,
[7] = 20,
};
//Dependendo da implementação, pode ser 1, pois o padrão do C permite
//reutilizar a mesma string entre literais compostos e strings literais
(const char[]){"abc"} == "abc";
No geral, todos os literais compostos criados dentro de algum bloco tem duração automática (a menos que utilizemos o modificador static que força a duração estática) e fora de blocos no escopo global tem duração estática.
Preprocessador
Chamamos de preprocessamento uma etapa que ocorre antes da compilação, nessa etapa um arquivo é “preprocessado” e utilizado para gerar um arquivo final que será repassado ao compilador.
Chamamos de diretivas de preprocessador os comandos que atuam na etapa de preprocessamento e são executados antes da compilação.
As diretivas de preprocessador podem ser utilizadas para :
- Adicionar textos ou bytes de outros arquivos para o código fonte
- Abortar a compilação devido a algum erro
- Gerar avisos ao compilar, indicando que algo está errado ou deve ser tratado com cuidado
- Adicionar ou remover diretivas de preprocessador ou código condicionalmente
- Especificar detalhes extras que podem modificar o comportamento do compilador
A sintaxe para uma diretiva de preprocessador é :
#DIRETIVA ARGUMENTOS
#é obrigatório e indica que é uma diretiva de preprocessadorDIRETIVAé o nome da diretiva de preprocessador (define,include,ifdef, etc)ARGUMENTOSsão os argumentos da diretiva, que dependem da diretiva utilizada e podem ou não ser opcionais
Toda diretiva de preprocessador é normalmente finalizada quando colocamos uma nova linha, porém podemos utilizar o caractere \ para extender a diretivas em mais linhas :
//Diretiva com uma linha
#define ALFABETO "abcdefghijklmnopqrstuvwxyz"
//Extendida em mais linhas utilizando "\"
#define MENSAGEM \
"Ola como vai\n" \
"Você?\n"
Macros
Macros são diretivas de preprocessamento que realizam uma substituição textual.
Macros não tem escopo, portanto mesmo se ela for definida dentro de uma função, poderá ser utilizada fora dela.
A sintaxe para definirmos novas macros é :
//Macro sem conteúdo
#define BUILD_DEBUG
//Macro sem parâmetros
#define TEXTO_ANTIGO "Texto novo"
//Macro com parâmetros
#define MAXIMO(X,Y) (((X) > (Y)) ? (X) : (Y))
Dessa forma quando escrevermos :
BUILD_DEBUG; //Será substituido por nada
TEXTO_ANTIGO; //Será substituido por "Texto novo"
//Resultará em 5
//expressão ((5) > (3) ? (5) : (3))
int test = MAXIMO(5,3);
Lembrando que no C23, podemos substituir o uso de macros para definições de constantes utilizando variáveis como constexpr ou até enum, o problema de constexpr é que ele é bem recente, acaba sendo problemático quando desejamos fazer bibliotecas que funcionem com versões anteriores do C, no C++ essa noção já é mais comum pois constexpr foi adicionado desde o C++11.
Funções-Macros
Devido a falta de algumas funcionalidades alto nível na linguagem, é normal que programadores utilizem macros com parâmetros para implementar algumas funcionalidades utilizando macros.
A vantagem de utilizar macros é que podemos fazer coisas que normalmente não seriam possíveis utilizando apenas funções, a desvantagem, é que abrimos portas para que o programador possa implementar coisas realmente imprevisíveis, difíceis de testar, etc.
É preferível utilizar funções normais quando elas são suficientes, mas as funções macros tem seu espaço, o importante é saber utiliza-las de forma consciente, algo que programadores adquirem com experiência.
Para macros de múltiplas linhas é comum o uso de do while(0), que pode inicialmente parecer estranho por ser um “loop que não se repete” mas é a única forma de garantir que a macro funcione em um if de uma linha :
#include <stdio.h>
#include <stdbool.h>
#define print_forced1(X) {printf(X); fflush(stdout);}
#define print_forced2(X) \
do { \
printf(X); fflush(stdout); \
} while(0)
//Neste exemplo, ocorre um "erro" de compilação
//Pois "print_forced1" expande para uma chave com
//ponto e virgula no final, causando erros
bool forcePrint = true;
if(forcePrint)
print_forced1("Teste");
else
printf("Teste");
//Enquanto isso, utilizar "print_forced2" funciona
//Pois o loop "do while(0)" mantem as chaves dentro dele
// se tornando um único statement
if(forcePrint)
print_forced2("Teste");
else
printf("Teste");
Existem também dois erros que são muito “comuns” quando utilizamos macros:
- A falta de parenteses, que pode causar uma grande dor de cabeça devido as diferentes ordens de precedências dos operadores
- A possibilidade de repetirmos parâmetros quando há uma chamada de função.
Podemos exemplificar os dois casos ao implementar uma função-macro para obter o valor máximo :
#include <math.h>
#define MATH_MAX_1(X,Y) (X > Y ? X : Y)
#define MATH_MAX_2(X,Y) ((X) : (Y) ? (X) : (Y))
//Resulta em 3, pois teremos
//1 ^ (10 > 3) -> 0, pois XOR inverte o bit
// 0 ? 11 : 3 -> 3, pois temos 0 no ternário
const int test = MATH_MAX_1(1 ^ 10, 3);
//Resulta em 11, pois teremos
//1^10 = 11
// (11) > (3) ? (11) : (3)
const int test2 = MATH_MAX_2(1 ^ 10, 3);
//Neste caso, teremos TRÊS chamadas
//de função, pois expandirá para:
// sqrtf(2) > pow(1.19,2) ? sqrtf(2) : pow(1.19,2)
float test3 = MATH_MAX_2(sqrtf(2), pow(1.19,2));
Fica a dica :
- Sempre certifique-se de botar parenteses nos parâmetros pois isso garante um funcionamento adequado das macros para qualquer entrada
- Evite usar funções como parâmetros em macros, ou certifique-se de documentar quando o usuário pode utilizá-las ou deve evitá-las com a sua macro
- Se for fazer uma função macro, certifique-se que ela se comporta como uma chamada de função, utilizando
do while(0)caso necessário (evitando imprevisibilidades) - Tenha preferência a funções sobre funções macro
Macros com argumentos variádicos
Desde o C99 podemos utilizar argumentos variádicos em macros, de forma similar aos argumentos variádicos em funções.
Ao utilizar ... como o último parâmetro de uma macro, podemos colocar quantos argumentos quisermos naquele ponto, os argumentos podem ser acessados na macro ao digitar __VA_ARGS__.
Exemplo :
#include <stdio.h>
#define PRINT_ERRO(FORMAT, ...) fprintf(stderr, FORMAT, __VA_ARGS__)
//Esta macro
PRINT_ERRO("Erro %d no arquivo %s\n", 30, "main.c");
//Será substituida por
fprintf(stderr, "Erro %d no arquivo %s\n", 30, "main.c");
Observamos também que no exemplo acima, como foi colocada uma virgula na macro, se ... for vazio, teremos um erro de compilação :
//Erro de compilação!
PRINT_ERRO("Erro!\n");
//Pois isso expande para
fprintf(stderr, "Erro!\n",);
Para isso, desde o C23, podemos utilizar __VA_OPT__ para indicar algo que só será adicionado caso __VA_ARGS__ não seja vazio :
#include <stdio.h>
#define PRINT_ERRO(FORMAT, ...) fprintf(stderr, FORMAT __VA_OPT__(,) __VA_ARGS__)
PRINT_ERRO("Erro!\n");
Manipulação de argumentos de macro
Existem duas operações que podem ser realizadas utilizando argumentos de macros :
- Concatenação
- Conversão para string
Para concatenar um argumento de macro, utilizamos ## dentro da macro :
#define JUNTA_NOME(X,Y) X##Y
//Neste caso geramos um nome com "Vector_Grow"
void JUNTA_NOME(Vector, _Grow)()
{
//Código da função
}
As coisas se tornam um pouco mais complicadas caso quisermos concatenar o conteúdo de macros e não seus nomes, para isso é necessário usar uma macro para forçar a expansão das macros antes de realizar a operação:
#define JUNTA_NOMES_INTERNO1(X,Y) X##Y
#define JUNTA_NOMES(X,Y) JUNTA_NOMES_INTERNO1(X,Y)
int main()
{
//Causa um erro, pois "JUNTA_NOMES_INTERNO1"
//juntará ambos, gerando "__DATE____FILE__"
JUNTA_NOMES_INTERNO1(__DATE__,__FILE__);
//Neste caso, as macros são repassadas a outra macro
//De forma que "__DATE__" e "__FILE__" sejam expandidas
//E se tornem realmente strings com a data e nome do arquivo
JUNTA_NOMES(__DATE__,__FILE__);
}
Para converter simbolos para string, utilizamos # :
#define NOME_VARIAVEL(X) #X
int main()
{
int test = 5;
//Esta expressão se tornará
const char *nome = NOME_VARIAVEL(test);
//Isso :
const char *nome = "test";
}
Remover definições de macros
Podemos utilizar a diretiva #undef para remover uma macro já criada.
O uso é muito simples, basta utilizar #undef NOME_MACRO e ela será removida.
Isso é útil por exemplo quando queremos limitar uma macro a uma única função, pois macros não tem escopo.
Também é útil para resolver conflitos quando macros definidas por bibliotecas externas conflitarem com seu próprio código.
Macros pre-definidas
Algumas macros são predefinidas pelo padrão do C e estão sempre presentes :
__STDC__: Tem o valor1caso a implementação respeite o padrão do C.__STDC_VERSION__: Introduzido noC95, indica a versão do C utilizada, onde :199409L=C95199901L=C99201112L=C11201710L=C17202311L=C23__STDC_HOSTED__: Introduzido noC99, indica1se a versão roda num sistema operacional e0caso não haja sistema operacional (chamado freestanding).__FILE__: Se torna uma string literal com o nome do arquivo atual.__LINE__: Se torna o número da linha atual do código fonte.__DATE__: Se torna a data que o programa foi gerado, no formatoMmmm dd yyyy, o nome do mês se comporta como se gerado porasctime.__TIME__: Se torna o horário em que o programa foi gerado, no formatohh:mm:ss, como se gerado porasctime.__STDC_UTF_16__: Obrigatório desdeC23, indica1sechar16_tutilizar o encodingUTF-16.__STDC_UTF_32__: Obrigatório desdeC23, indica1sechar32_tutilizar o encodingUTF-32.
Outras macros, podem opcionalmente serem predefinidas pela implementação:
__STDC_ISO_10646__: Se torna um inteiro no formatoyyyymmLsewchar_tusar Unicode, a data indica a última revisão do Unicode suportada.__STDC_IEC_559__: Introduzido noC99, se torna1seIEC 60559for suportado (depreciado noC23)__STDC_IEC_559_COMPLEX__: Introduzido noC99, se torna1se números complexos forem suportados.__STDC_UTF_16___: Introduzido noC11, indica1sechar16_tutilizar o encodingUTF-16.__STDC_UTF_32___: Introduzido noC11, indica1sechar32_tutilizar o encodingUTF-32.__STDC_MB_MIGHT_NEQ_WC__: Introduzido noC99, indica1se comparações de caractere como'x' == L'x'podem resultar em falso.__STDC_ANALYZABLE__:Introduzido noC11, indica1quando o compilador é limitado a não modificar o comportamento do código em certos casos de comportamento indefinido.__STDC_LIB_EXT1__: Introduzido noC11, se torna201112Lse as funções “seguras” do Annex K estão disponíveis.__STDC_NO_ATOMICS__: Introduzido noC11, se torna1caso tipos atômicos não sejam suportados.__STDC_NO_COMPLEX__: Introduzido noC11, se torna1caso números complexos não sejam suportados.__STDC_NO_THREADS__: Introduzido noC11, se torna1se as funções padrões de threads não seja suportadas.__STDC_NO_VLA__: Introduzido noC11, se torna1se arrays de tamanho variável não forem suportados.__STDC_IEC_60559_BFP__: Introduzido noC23, se torna202311Lse tipos adicionais de ponto flutuante forem suportados (_FloatN,_FloatN_t).__STDC_IEC_60559_DFP__: Introduzido noC23, se torna202311Lse pontos flutuantes decimais forem suportados (_Decimal32,_Decimal64,_Decimal128).__STDC_IEC_60559_COMPLEX__: Introduzido noC23, se torna202311Lse números complexos forem suportados (_Complexe_Imaginary).__STDC_IEC_60559_TYPES__: Introduzido noC23, se torna202311Lse a implementação implementa qualquer um dos tipos doIEC_60559.
Diretiva #line
A diretiva #line pode ser utilizada para modificar os valores de __FILE__ e __LINE__, a sintaxe é :
#line num_linha: Modifica o número da linha utilizado em__LINE__.#line num_linha "nome arquivo": Modifica o nome do arquivo utilizado em__FILE__e o número da linha em__LINE__.
Exemplos interessantes no uso de Macros
Como mencionado anteriormente, podemos utilizar macros para introduzir funcionalidades alto nível na linguagem, o que pode ser tanto positivo quanto negativo, pois isso nos permite distanciar nosso código do que seria visto como normal em C.
Vamos listar algumas funcionalidades genéricas que podemos fazer com macros:
Tamanho do array
#define ARRAY_SIZE(X) (sizeof(X)/sizeof(*X))
Só funciona em arrays, os quais sizeof retorna o tamanho total (e não em ponteiros).
Limitação de valores
//Valor máximo entre 2 valores
#define MATH_MAX(A,B) ((A) > (B) ? (A) : (B))
//Valor mínimo entre 2 valores
#define MATH_MIN(A,B) ((A) < (B) ? (A) : (B))
//Limita um valor entre um mínimo e máximo
#define MATH_CLAMP(VAL,MIN,MAX) ((VAL) > (MAX) ? (MAX) : \
(VAL) < (MIN) ? (MIN) \
: (VAL))
Lembrando que não é recomendado o uso de funções nos parâmetros dessas macros, pois isso implicaria em 2 chamadas de uma das funções.
Ponteiro de estrutura a partir de ponteiro de membro
Na biblioteca stddef.h, incluida junto com a stdlib.h, temos a macro offsetof que pode ser utilizada para obter o offset em bytes de um membro de uma struct.
Com base na offsetof é possível implementar uma função que obtem o endereço da struct a partir do enderço de um membro.
//ptr é um ponteiro para o membro
//type é o tipo da estrutura
//member é o nome do membro
#define container_of(ptr, type, member) ({ \
const typeof( ((type *)0)->member ) *__mptr = (ptr); \
(type *)((char *)__mptr - offsetof(type,member));})
struct Teste{
int v1;
int v2;
};
struct Teste test;
int *ptr = &test.v1;
struct Teste *testptr = container_of(ptr, struct Teste, v1);
A macro funciona com base em 3 parâmetros :
ptr: Ponteiro para membrotype: Tipo da estruturamember: Nome do membro
Loops foreach
#define for_each_zero(TYPE, ITEM, ARRAY) \
for(TYPE *ITEM = ARRAY; *ITEM; ITEM++)
#define for_each_ptr(TYPE, ITEM, ARRAY, SIZE) \
for(TYPE *ITEM = ARRAY; ITEM < (ARRAY + SIZE); ITEM++)
#define for_each_ll(TYPE, ITEM, LINKEDLIST) \
for(TYPE *ITEM = LINKEDLIST; *ITEM; ITEM = ITEM->proximo)
#define for_each(TYPE, ITEM, ARRAY) for_each_ptr(TYPE, ITEM, ARRAY, ARRAY_SIZE(ARRAY))
//Itera sob arrays onde o último elemento com zero sinaliza o fim
for_each_zero(const char, c, "Abacaxi") {
putc(*c);
}
//Itera sob arrays fixos
const char *carrinho[] = {"Fonte 500W", "Gabinete Gamer",
"RAM 16GB 2666MHz", "RX 580"};
for_each(const char*, item, carrinho) {
puts(*item);
}
//Itera sob arrays dinâmicos
int *numeros = malloc(sizeof(int) * 10);
for_each_ptr(int, numero, numeros) {
int quadrado = (*numero) * (*numero);
printf("%d\n" , quadrado);
}
//Preparação para uso
struct ListaEncadeada{
int valor;
struct ListaEncadeada *proximo;
} lista[10];
for(int i = 0; i < 10; i++) {
lista[i].valor = i;
lista[i].proximo = lista + i + 1;
}
lista[9].proximo = NULL;
//Itera sob cada elemento de uma lista encadeada
for_each_ll(struct ListaEncadeada, item, lista) {
printf("%d\n", item->valor);
}
Nesse caso, a macro for_each e suas variantes fazem com que o item seja um ponteiro para cada elemento do array, possivelmente permitindo a modificação de cada elemento.
O C23 facilita a implementação dessas funcionalidades alto nível ao fornecer a palavra chave typeof, eliminando a necessidade de repassar o tipo, que pode ser deduzido do array ou lista encadeada.
Também incluimos uma variante com listas encadeadas, demonstrando como diferentes tipos de dados que devem ser iterados de formas diferentes, podem ser simplificados para uma iteração similar através de macros.
Parâmetros nomeados
Devido a introdução dos literais compostos, é posível criar structs que podem ter seu endereço utilizado sem a necessidade de criar variáveis.
Além disso, ao utilizar inicializadores designados, um mesmo campo pode ser inicializado duas vezes e apenas a última inicialização é levada em consideração.
Ao definir uma struct com todos parâmetros opcionais/nomeados, usá-la como parâmetro no final de uma função e utilizarmos uma macro variádica para chamá-la, podemos efetivamente ter parâmetros opcionais e nomeados, conforme demonstra o exemplo:
//Uso da macro
imprimePdf(pdf); //Padrão
imprimePdf(pdf, .paginas = 2, .papel = PAPEL_A5); //Imprime 2 páginas em A5
imprimePdf(pdf, .impressora = hp_scx_4200); //Usa outra impressora
imprimePdf(pdf, .retrato = false, .colorida = true); //Define modo paisagem colorido
//Implementação
struct ImprimePdfParam {
void *impressora; //Padrão NULL -> Impressora padrão
int paginas; //Padrão -1 -> Todas
int papel; //Padrão PAPEL_A4 -> A4
double escala; //Padrão 1.0 -> Escala 1:1
bool retrato; //Padrão true -> Modo retrato
bool colorida; //Padrão false -> página em preto e branco
};
#define imprimePdf(PDF, ...) \
_imprimePdf(PDF, (struct ImprimePdfParam){.paginas = -1, \
.papel = PAPEL_A4, .escala = 1.0, .retrato = true, __VA_ARGS__})
_imprimePdf(void *pdf, struct ImprimePdfParam opcoes) { /*Implementação*/}
Seletores de macro
No pedaço sobre manipulação de argumentos de macro, vimos como o uso de uma segunda macro é necessária para transformarmos o “nome de uma macro” em seu valor expandido.
Isso acontece pois é possível, repassar macros para outras macros. Existem formas de abusar dessa funcionalidade para implementar algumas coisas que geralmente não seriam possíveis.
Uma dessas formas é o uso de “seletores de macro” onde misturamos macros com um número variável de argumentos com a possibilidade de usar macros como argumentos, permitindo o seguinte comportamento :
//Escolhe quais macros vão ser usadas dependendo do sistema
#ifdef _WIN32
#define CAMINHO_EXPANDE_1(_1) _1
#define CAMINHO_EXPANDE_2(_1, _2) _1"\\"_2
#define CAMINHO_EXPANDE_3(_1, _2, _3) _1"\\"_2"\\"_3
#define CAMINHO_EXPANDE_4(_1, _2, _3, _4) _1"\\"_2"\\"_3"\\"_4
#define CAMINHO_EXPANDE_5(_1, _2, _3, _4, _5) _1"\\"_2"\\"_3"\\"_4"\\"_5
#else
#define CAMINHO_EXPANDE_1(_1) _1
#define CAMINHO_EXPANDE_2(_1, _2) _1"/"_2
#define CAMINHO_EXPANDE_3(_1, _2, _3) _1"/"_2"/"_3
#define CAMINHO_EXPANDE_4(_1, _2, _3, _4) _1"/"_2"/"_3"/"_4
#define CAMINHO_EXPANDE_5(_1, _2, _3, _4, _5) _1"/"_2"/"_3"/"_4"/"_5
#endif
//Essa macro mantêm apenas o 6º elemento e descarta todos os outros
#define SELETOR_5(_1, _2, _3, _4, _5, SELECIONADO, ...) SELECIONADO
/* Seleciona uma macro, e depois chama ela com "__VA_ARGS__" */
#define CAMINHO_ARQUIVO(...) SELETOR_5(__VA_ARGS__, CAMINHO_EXPANDE_5, CAMINHO_EXPANDE_4, \
CAMINHO_EXPANDE_3, CAMINHO_EXPANDE_2, \
CAMINHO_EXPANDE_1)(__VA_ARGS__)
//"build"
CAMINHO_ARQUIVO("build")
//"build/x64/executavel" no Linux e "build\\x64\\executavel" no Windows
CAMINHO_ARQUIVO("build", "x64", "executavel")
Vamos explicar passo a passo o que ocorre no caso de CAMINHO_ARQUIVO("build", "x64", "executavel") :
- Expande-se
CAMINHO_ARQUIVOparaSELETOR_5("build", "x64", "executavel", CAMINHO_EXPANDE_5, CAMINHO_EXPANDE_4, restante das macros)("build", "x64", "executavel") SELETOR_5escolherá o 6º argumento e manterá apenas ele, nesse caso temos- 1° “build”
- 2° “x64”
- 3° “executavel”
- 4°
CAMINHO_EXPANDE_5 - 5°
CAMINHO_EXPANDE_4 - 6°
CAMINHO_EXPANDE_3(os 3 argumentos deslocaram para que essa macro seja a 6º) - Dessa forma
SELETOR_5(...)("build", "x64", "executavel")expande paraCAMINHO_EXPANDE_3("build", "x64", "executavel") - A macro
CAMINHO_EXPANDE_3expande, dependendo do sistema operacional (assumindo Linux),"buld""/""x64""/""executavel"
Vale lembrar que essa técnica assume que todos argumentos são strings literais, e não funciona com variaveis, pois depende do mecanismo de concatenação de strings literais.
A vantagem dessa técnica é que ela permite manipulações complexas que normalmente não seriam possíveis e o problema é que é necessário escrever uma nova macro
para cada número de argumento suportado (x argumentos = x macros).
Recomenda-se evitar seu uso caso possível, mas segue como uma alternativa viável em alguns casos, como ao escrever caminhos de arquivo “portáveis” que funcionam em qualquer plataforma, sem necessidade de conversões em tempo de execução.
Compilação Condicional
Existem algumas diretivas de preprocessamento que permitem decidir condicionalmente o código que será levado a etapa de compilação, possibilitando que um determinado código seja excluido da compilação.
Para isso temos várias diretivas que funcionam de forma similar a if e else :
#if: Checa se uma expressão é verdadeira, se for, o código dentro deste bloco será válido para compilação.#ifdef: Um atalho para#if defined.#ifndef: Um atalho para#if ! defined.#elif: Similar aelse if, uma junção de#elsecom#if, onde a expressão é checada apenas se todas anteriores falharem.#elifdef: Adicionado noC23, atalho para#elseif defined.#elifndef: Adicionado noC23, atalho para#elseif ! defined.#else: Similar aoelse, o código dentro deste bloco só será válido se todos condicionais anteriores falharem.#endif: Finaliza o bloco iniciado por#if,#ifdefou#ifndef.
No geral as seguintes funcionalidades adicionais podem ser utilizadas em conjunto com #if e #elif :
defined(X): Checa se a macroXexiste, resultando em 1 caso ela exista__has_include(X): Adicionado noC23, checa se o arquivoXpode ser encontrado (busca nas pastas deinclude).__has_embed(X): Adicionado noC23, checa se o arquivo de recursoXpode ser encontrado, resultando em :__STDC_EMBED_NOT_FOUND__: Caso o arquivo não exista.__STDC_EMBED_EMPTY__: Caso o arquivo exista, mas esteja vazio.__STDC_EMBED_FOUND__: Caso o arquivo existe e não esteja vazio.
__has_c_attribute(X): Adicionado noC23, checa se o atributo especificado existe, resultado em um número que indica quando ele foi adicionado ao C, qualquer valor diferente de 0 indica que o atributo existe.
Exemplos de uso das diretivas :
//Definição indicando que é uma versão de debug
#ifndef NDEBUG
#define DEBUG_BUILD
#endif
#if defined(DEBUG_BUILD)
#ifdef _WIN32 //Checa se estamos no windows
#define DBG_BREAKPOINT() __debugbreak()
#else //No linux e macOs utilizamos SIGTRAP
#include <signal.h>
#define DBG_BREAKPOINT() raise(SIGTRAP)
#endif
#define DBG_ASSERT(X) if(!(X)) DBG_BREAKPOINT()
#else
#define DBG_BREAKPOINT()
#define DBG_ASSERT(X)
#endif
//Exemplo ficticio de uso
static char buffer[2048];
size_t tam = recebeDados(sock,buffer, sizeof(buffer));
//Gera um breakpoint caso receba mais do que 20 bytes
DBG_ASSERT(tam >= 20);
É muito comum o uso das diretivas #ifndef para implementação de include guards (explicados no capítulo sobre include):
#ifndef MINHA_BIBLIOTECA_H
#define MINHA_BIBLIOTECA_H
static int test;
#endif
#ifndef MINHA_BIBLIOTECA_H
#define MINHA_BIBLIOTECA_H
static int test;
#endif
//Mesmo incluindo o mesmo código duas vezes, o "include guard"
//Impede que ele seja avaliado duas vezes...
Apenas expressões constantes podem estar num #if ou #elif, isso significa que variáveis constexpr, macros e valores de enum são permitidos, bem como sizeof.
Definições úteis
Aqui vamos citar algumas definições úteis que estão presentes em vários compiladores, lembrando que nenhuma dessas definições está presente no padrão do C e qualquer compilador PODE escolher não implementar algumas delas.
Macros para detecção de sistema operacional :
_WIN32: Macro definida quando compilado para o sistema operacional Windows (tanto 32bits quanto 64bits)._WIN64: Macro definida quando compilado para Windows 64bits.__linux__: Macro definida em sistemas linux.__APPLE__: Detecta que é um sistema operacional da apple.__MACH__: Detecta que o sistema baseado em Mach, kernel da apple.BSD: Definido em sistemas comoDragonFly BSD,FreeBSD,OpenBSD,NetBSD.__unix__: Detecta sistemas derivados de UNIX, pode não estar presente nos dispositivos da apple apesar deles serem variantes._POSIX_VERSION: Ao incluir a bibliotecaunistd.hem sistemas UNIX, podemos checar a versão do POSIX.__CYGWIN__: POSIX no Windows utilizando Cygwin (neste caso,_WIN32não estará definido).
Macros para detecção de compiladores:
__clang__: Detecta o compilador Clang.__GNUC__: Detecta o compilador GCC.__GNUG__: Detecta o compilador G++ (GCC para C++)._MSC_VER: Detecta o compilador MSVC.__INTEL_COMPILER: Detecta o compilador da intel.__IBMC__: Detecta o compilador da IBM para C.__IBMCPP__: Detecta o compilador da IBM para C++.
Também é importante mencionar que o C++ define a macro __cplusplus com a versão do C++, similar a macro __STDC_VERSION__, podemos utilizar ela para verificar se nosso código está sendo compilado por um compilador de C++, algo que muitas bibliotecas fazem.
Inclusão de arquivos
Existem algumas diretivas de compilação utilizadas para incluir arquivos externos dentro do código fonte.
Estas diretivas são utilizadas para reutilizar e/ou minimizar a quantidade de código que devemos escrever, separando parte do conteúdo em arquivos externos.
As diretivas existentes são :
#include: Utilizado para incluir o conteúdo de arquivos como código fonte.#embed: Utilizado para incluir o conteúdo de arquivos como arrays de bytes acessíveis (C23).
include
A diretiva #include é utilizada para adicionar o conteúdo de um arquivo ao código fonte.
O comportamento efetivo de #include é equivalente a abrir o arquivo, copiar e colar seu conteúdo no ponto em que ele foi incluido.
A sintaxe para uso de #include é:
//Inclusão de arquivos externos (1)
#include <stdio.h>
//Inclusão de arquivos do usuário (2)
#include "api/web.h"
//Inclusão utilizando definições (3)
#define LIB_PADRAO <stdlib.h>
#include LIB_PADRAO
- A inclusão neste estilo é direcionada para arquivos sob o controle da implementação (compilador), que deve incluir as bibliotecas padrão do C e tipicamente os arquivos presentes pastas definidas como pastas adicionais de inclusão utilizando opções do compilador.
- A inclusão de arquivos neste estilo é direcionada para arquivos do usuário, tipicamente os arquivos relativos ao arquivo que utilizou
#include, a maioria das implementações busca a pasta atual e caso não encontre, realiza as buscas nas pastas de inclusão conforme1.. - Caso o texto de inclusão não contenha um texto nos padrões
1.e2.(com<>ou aspas), realiza a substituição de macro e a substituição resultante deverá se encaixar no padrão1.ou2..
Num texto de inclusão os seguintes caracteres não podem ser utilizados no nome do arquivo :
',\,//,/*- Caracteres utilizado para iniciar/finalizar a inclusão (
<e>no padrão1.ou"no padrão2.)
Além disso, desde o C23 a palavra chave __has_include, como já explicado no capítulo sobre compilação condicional, pode ser utilizada em #if ou #elif para checar se um arquivo existe e é um alvo válido para #include (mas não checa se o código contido no arquivo é válido).
Arquivos de Cabeçário
É muito comum que o alvo de #include seja sempre algum arquivo que com extensão .h, estes arquivos são arquivos de cabeçário ou em inglês “header” (por isso .h de header).
Diferente da crença de muitos iniciantes, não existe uma diferença efetiva na forma como arquivos .c e .h são interpretados, ambos são código de C válido, e não há nada que realmente impeça o uso de #include com um arquivo .c.
A diferença na verdade, é simplesmente uma convenção, geralmente se espera que arquivos com extensão .h sejam utilizados para incluir bibliotecas, enquanto arquivos .c sejam utilizados para implementar essas bibliotecas, formando uma “separação” que é bastante natural para o programador de C.
Portanto, se utilizarmos um arquivo .h para definições, é natural que ele inclua apenas :
- Macros
- Declarações de funções (sem definir)
- Declarações de tipos (
typedef,enum,struct,union) - Importação de variáveis globais (sem definir, utilizando
extern)
Também é natural que exista um arquivo de mesmo nome com a extensão .c que :
- Inclua o próprio
.h, reutilizando o código de definição de tipos e macros - Defina e implemente todas funções declaradas no
.h - Defina, caso haja alguma, as variáveis globais importadas no
.h
Exemplo deste padrão (arquivos são delimitados pelos comentários) :
//test.h
#ifndef TEST_H
#define TEST_H
struct VersaoSoft {
int maior;
int menor;
int revisao;
};
void printaVersao(struct VersaoSoft *versao);
#endif
//test.c
#include <stdio.h>
#include "test.h"
void printaVersao(struct VersaoSoft *versao)
{
printf("Versao %u.%u.%u\n", versao->maior, versao->menor, versao->revisao);
}
Podemos entender um pouco melhor a necessidade dessa separação ao entendermos os dois problemas que aconteceriam se decidissemos “incluir arquivos com implementações completas” em vários lugares :
- Toda função ou variável pública sem
staticé exportável, portanto se duas ou mais unidades de tradução diferentes incluirem uma implementação da mesma função, ocorrerá um conflito durante a vinculação, ocasionando em um erro de compilação. - Aumento no tempo de compilação, devido a necessidade de recompilar o código adicionado uma vez para cada unidade de tradução que o inclua.
Apesar de um pouco menos comum, também há casos onde utiliza-se um arquivo .h para fazer uma biblioteca “facilmente embarcável”, nestes casos costuma-se utilizar static em todas funções e variáveis, de forma que mesmo que dois arquivos diferentes incluam a mesma biblioteca, não ocorra nenhum conflito na etapa de vinculação.
Include Guard
Alguns padrões específicos normalmente são utilizados para impedir a inclusão recursiva (um arquivo incluir ele mesmo diretamente ou indiretamente) ou múltiplas inclusões do mesmo arquivo.
Esses padrões são comumente chamados de “include guards”, que no português seria algo como “proteção de inclusão”.
Vale notar que incluir múltiplas vezes o mesmo arquivo poderia causar um erro de compilação se o arquivo incluir, por exemplo, definições de tipos (pois não podemos redefinir um mesmo tipo), além de ser um desperdício de tempo para o compilador.
Geralmente utilizamos o seguinte padrão para realizar um include guard :
#ifndef NOME_DO_ARQUIVO_H
#define NOME_DO_ARQUIVO_H
//Conteúdo do arquivo
#endif
Logo no ínicio do arquivo, utilizamos um #ifndef indicando que o código abaixo só é válido se NOME_DO_ARQUIVO_H não estiver definido, porém, dentro do próprio arquivo, definimos a macro NOME_DO_ARQUIVO_H, de forma que numa segunda passada, o código seja ignorado.
Essa técnica é muito comum, e é a que você provavelmente encontrará em qualquer um dos headers das bibliotecas padrão do C do seu compilador, a maioria dos compiladores realizam otimizações específicas que permitem que o compilador possa pular abrir e checar um arquivo caso ele seja incluído novamente.
A maioria dos compiladores modernos permitem que você use #pragma once ou _Pragma("once") para sinalizar que um arquivo só pode ser incluído uma vez, sendo uma alternativa possível aos include guards.
Para garantir que o compilador possa realizar a otimização mencionada, é recomendado que o include guard seja escrito na sequência :
- Comentários e espaço/nova linha apenas (ou vazio)
#ifndef NOME_dA_MACRO- Seu código
#endif- Comentários e espaço/nova linha apenas (ou vazio)
Apesar de #ifndef X ser equivalente a #if ! defined(X), alguns compiladores só realizam a otimização citada caso utilizemos #ifndef.
Otimizando tempo de Compilação
A inclusão de arquivos de bibliotecas pode tomar um tempo considerável da compilação, para isso existem algumas soluções que podem ajudar a diminuir este tempo.
Para diagnosticar e melhorar o tempo de compilação, é recomendado que o usuário :
- Utilize uma ferramenta de build que permita compilar vários arquivos em paralelo.
- Evite utilizar cabeçários enormes, pode ser mais fácil só declarar o que vai usar.
- Pre-compilar cabeçários mais pesados, formando um formato que pode ser processado rapidamente.
- Evite recompilar bibliotecas grandes, compilando ou utilizando-as como bibliotecas compartilhadas (
.so/.dll/.dylib).
Para diagnosticar os maiores gargalos relacionados a inclusão de arquivos, existe um programa gratuito e open source chamado IncludeGuardian que também ajuda a diagnosticar.
Também é interessante citar o linker mold que é um projeto de um linker moderno muito mais rápido e eficiente, que atualmente só funciona no linux.
embed
A diretiva de compilação #embed é utilizada para embarcar os bytes de qualquer arquivo no código fonte.
Existem três padrões de escrita, da mesma forma que #include:
#embed <arquivo>: Inclusões de arquivos externos#embed "arquivo": Inclusões de arquivos locais#embed MACRO: Inclusões com macros
A diretiva #embed deve ser utilizada para inicializar um array do tipo char ou unsigned char, sendo equivalente a escrever cada um dos bytes do arquivo como literais do tipo inteiro.
Por conta disso, é necessário colocar uma virgula se desejarmos adicionar dados além dos incluidos pelo #embed.
Exemplos :
const unsigned char dadosImagem[] = {
#embed "foto.png"
};
//Como o #embed funciona "injetando" inteiros literais
//podemos colocar sufixos ou prefixos
const char mensagem[] = {
'M', 'e', 'n', 's','a','g','e','m',':','\n',
#embed "mensagem.txt"
,'\0'
};
//Ou até mesmo embarcar vários arquivos
//em um único array
const char documento[] = {
#embed "header.txt"
'\n',
#embed "body.txt"
,'\n',
#embed "footer.txt"
};
Além disso, existem 4 opções extras que podem ser utilizados no máximo 1 vez cada em conjunto com a diretiva #embed, todos seguindo a sintaxe opcao(parametro):
limit: O parâmetro deve ser um número inteiro não negativo, limita a quantidade de bytes máxima que podem ser incluídas do arquivo.prefix: Se o arquivo utilizado no#embedexistir e não for vazio, o parâmetro doprefixé colocado logo antes da expansão do#embedcomo prefixosufix: Se o arquivo utilizado no#embedexistir e não for vazio, o parâmetro dosufixé colocado logo após a expansão do#embedcomo sufixoif_empty: Se o arquivo utilizado no#embednão existir ou for vazio, o parâmetro doif_emptyé será colocado no array, sendo omitido caso contrário.
Exemplo :
const char mensagem[] = {
#embed "mensagem.txt" if_empty('V','a','z','i','o')
,'\0'
};
#define CONTENT_TYPE 'C','o','n','t','e','n','t','-','T','y','p','e',':'
#define MIME_TYPE_JPEG 'i','m','a','g','e','/','j','p','e','g'
#define VERSAO_HTTP 'H','T','T','P','/','1','.','1',' '
#define STATUS_OK '2','0','0',' ','O','K','\r','\n'
#define STATUS_NOT_FOUND '4','0','4',' ','N','O','T',' ','F','O','U','N','D','\r','\n'
//Embarca o arquivo com a resposta HTTP
const char respostaHttp[] = {
VERSAO_HTTP,
#embed "imagem.jpg" \
prefix(STATUS_OK, \
CONTENT_TYPE, MIME_TYPE_JPEG,'\r','\n' \
'\r','\n') \ //200 OK, Content-Type:image/jpeg
if_empty(STATUS_NOT_FOUND) //404 NOT FOUND
}
Além disso, similar ao __has_include, também podemos utilizar __has_embed em diretivas #if ou #elif para verificar se um recurso é embarcável com #embed, a diferença é que ao invés de 0 ou 1, o #embed resulta em um entre três valores :
__STDC_EMBED_NOT_FOUND__: Arquivo não encontrado__STDC_EMBED_EMPTY__: Arquivo vazio__STDC_EMBED_FOUND__: Arquivo encontrado e com conteúdo
Pragma
O comando #pragma é utilizado para realizar um controle de comportamentos definidos pela implementação, é uma maneira padronizada com que o programador possa “comunicar-se” com detalhes específicos do compilador.
Pode ser escrito de duas formas :
//Primeira forma
#pragma identificador parametros
//Segunda forma (C99)
_Pragma("identificador parametros")
#pragma: se comporta de uma maneira definida pela implementação, a menos que seja um dos pragmas padrão especificados depois._Pragma: Disponível desde oC99, pode ser utilizado ao expandir uma macro, algo que é impossível com o#pragma, seu conteúdo precisa estar no formato de string, e o conteúdo da string é lido como se fosse a entrada de um#pragma.
Pragmas padrão
Desde o C99 foram adicionadas três pragmas padrão da linguagem, onde arg pode ser ON (ativo), OFF (desativo) , DEFAULT (padrão):
#pragma STDC FENV_ACCESS arg: Indica que o usuário vai modificar o estado das flags de ponto flutuante do processador, proibindo algumas otimizações, geralmente o padrão é desabilitado.#pragma STDC FP_CONTRACT arg: Permite otimizações de ponto flutuante que omitem erros de arredondamento e exceções de ponto flutuante que seriam observadas se a expressão fosse usada diretamente (por exemplo permite que(x*y)+zseja implementado por uma instrução otimizada específica do processador ao invés de realizar a multiplicação e soma separadamente), geralmente o padrão é habilitado.#pragma STDC CX_LIMITED_RANGE arg: Indica que multiplicação, divisão e o valor absoluto de números complexos podem usar formulas matemáticas simplificadas apesar da possibilidade de overflow intermediário, em outras palavras, o programador garante que a faixa de valores passadas a essas funções será limitada, desabilitado por padrão.
Alguns compiladores podem não suportar esses pragmas, mas devem ao menos ter as mesmas opções como opções de linha de comando do compilador.
Pragmas conhecidos
Todos os outros pragmas são definidos pela implementação, porém existem dois pragmas que são muito comuns : #pragma once e #pragma pack.
Pragma once
Uma forma mais simplificada de escrita que tem efeito similar a um include guard conforme descrito no capítulo sobre inclusão de arquivos.
Basicamente ao utilizar #pragma once, o arquivo será ignorado se for incluido novamente, de forma que possamos ter um efeito similar a um include guard, porém sem a necessidade de criar uma macro única para o arquivo.
Pragma pack
Utilizado para controlar o alinhamento de uma struct ou union, pode ser utilizado de 5 formas, onde arg é uma potência de 2 indicando o alinhamento:
#pragma pack(arg): Define o alinhamento como o valor dearg.#pragma pack(): Define o alinhamento como o valor padrão (especificado por um argumento da linha de comando).#pragma pack(push): Guarda o valor do alinhamento atual numa “stack” interna.#pragma pack(push, arg): Guarda o valor do alinhamento atual na “stack” interna, e define o alinhamento atual paraarg.#pragma pack(pop): Remove o último valor de alinhamento da “stack” interna e define o alinhamento para aquele valor.
Controle de compilação
Algumas macros podem ser utilizadas para gerar avisos ou abortar a compilação.
Elas são :
#error mensagem: Gera um erro de compilação, fazendo com que o compilador mostre amensagemespecificada.#warning mensagem: Adicionado noC23, gera um aviso do compilador, mostrandomensagemmas não interrompe a compilação.
mensagem pode ser um conjunto de várias palavras não necessariamente entre aspas (apesar do mais comum ser utilizar aspas).
Antes de ser padronizado, #warning era suportado por vários compiladores como uma extensão.
Exemplo do uso de #error :
#include <limits.h>
#if (CHAR_BIT * sizeof(void*)) < 32
#error "Este programa não funciona em arquiteturas menores que 32bits"
#endif
Atributos
Desde o C23, foram adicionados os “atributos” a linguagem, que são uma forma de sinalizar detalhes adicionais ao compilador, uma funcionalidade que até então só existia no C++ (adicionada no C++11).
Os atributos servem, similar ao #pragma, como uma forma padronizada e unificada de indicar detalhes ao compilador, que normalmente eram efetuados utilizando extensões de compilador (como __attribute__ do GCC e IBM, ou __declspec do MSVC).
Declaração de atributos :
[[atributo-padrao]] //1° forma
[[prefixo::atributo]] //2° forma
[[atributo-padrao(argumentos)]] //3° forma
[[prefixo::atributo(argumentos)]] //4° forma
Todos atributos específicos de compilador tem um prefixo e :: antes do nome efetivo do atributo, já os atributos padrão da linguagem são escritos sem prefixo.
Alguns atributos podem ter um ou mais argumentos, que ficam entre parênteses, caso haja mais de um, eles são separados por virgula.
Exemplo do uso de atributos:
float f1 = 5.4;
//Atributo padrão para inibir
//avisos do compilador sobre variável não utilizada
[[maybe_unused]]
float f2 = 9.2;
//Usando atributo para especificar
//exceção a regra de strict aliasing ao GCC (C23)
[[gnu::may_alias]]
int *i1 = (int*)&f1;
//Utilizando extensão de compilador (antes do C23)
__attribute((__may_alias__)) int *i2 = (int*)&f1;
Atributos padrão
Os seguintes atributos são considerados padrão da linguagem:
[[deprecated]]: Indica que a função ou variável associada é depreciada e não é recomendada, gerando um aviso do compilador.[[deprecated("motivo")]]: Versão do atributo acima, com um parâmetro indicando a mensagem a ser exibida ao gerar o aviso.[[fallthrough]]: Indica que continuar a execução para o próximocasepor conta da ausência da palavra chavebreaknuma estrutura de controle de fluxoswitché intencional.[[nodiscard]]: Faz com que o compilador gere um aviso se o valor de retorno for ignorado.[[nodiscard("motivo")]]: Versão do atributo acima, com um parâmetro indicando a mensagem a ser exibida ao gerar o aviso.[[maybe_unused]]: Impede o compilador de gerar avisos se a variável/função associada não for utilizada.[[noreturn]]: Indica que a função não retorna.[[reproducible]]: Indica que a função ésem efeitoeindependente, isso permite que o compilador trate múltiplas chamadas em sequência como uma única chamada.[[unsequenced]]: Indica que a função ésem efeito,idempotente,sem estadoeindependente, permite que o compilador trate múltiplas chamadas em sequência como uma única chamada e também que elas sejam paralelizadas e reordenadas de forma arbitrária.
Para entender melhor os atributos unsequenced e reproducible, as funções podem ou não ser classificadas como :
Sem efeito: Uma função ésem efeitose ela modifica apenas variáveis locais, ou valores através de um único ponteiro repassado como parâmetro a função.Idempotente: Uma função éidempotentequando outra chamada dela pode ser executada logo em sequência sem alterar o resultado ou o estado observável de execução.Sem Estado: Uma função é consideradasem estado, se qualquer definição de variável de duraçãoestáticaou dethreadnela ou em alguma função que ela chame sejaconste não tenha o especificadorvolatile.Independente: Uma função éindependentequando ela não modifica nenhum parâmetro via ponteiro, não modifica o estado de variáveis globais nem o estado global do programa ou sistema operacional.
Para compreender de maneira prática (quais funções poderiam ter os atributos unsequenced ou reproducible):
printfnão poderia ter nenhumstrlenememcmppodem ser[[unsequenced]]memcpypode ser[[reproducible]]memmovenão pode ser nenhum dos dois, por que ele não éidempotentepara regiões de memória que se sobrepõemfabspode ser[[unsequenced]]sqrtnão pode ser nenhum dos dois, pois ele modifica o ambiente de ponto flutuante e pode modificarerrno
Os exemplos acima foram retirados dessa resposta do StackOverflow.
Checar atributo
Podemos checar se um atributo existe utilizando __has_c_attribute dentro de um #if ou #elif.
O valor resultante da expressão __has_c_attribute difere entre atributos padrão e atributos específicos de compiladores :
- Atributos padrão tem tipo
longe valor indicando o ano e mês em que o atributo foi adicionado aos documentos de especificação da linguagem, ex: um atributo adicionado em Abril de 2019 terá o valor201904L. - Atributos específicos de compilador são considerados como existentes caso tenham valor diferente de zero.
- Atributos inexistentes terão o seu valor zerado.
Sistema operacional
O termo sistema operacional indica um ou mais softwares que gerenciam os recursos de software e hardware do computador, como processador, memória e periféricos.
O componente principal de um sistema operacional é o kernel, o kernel é um programa que gerencia o hardware e geralmente tem um nível de acesso superior aos programas comuns, de forma que apenas o kernel tenha acesso ao hardware e todo acesso externo por outros softwares ocorra através de solicitações ao kernel.
Solicitações para que o kernel realize tarefas, são denominadas de “chamadas de sistema” ou no inglês “syscall” (uma abreviação de “system call”), elas geralmente são necessárias para realizar tarefas que precisam de permissões elevadas, as quais, geralmente, apenas o kernel detêm.
É comum que as seguintes tarefas sejam realizadas utilizando chamadas de sistema :
- Alocação de memória dinâmica
- Acesso ao sistema de arquivos (criar, ler, escrever, renomear arquivos, links simbólicos e pastas)
- Acesso a GPU e periféricos (mouse, teclado, USB, som, etc)
- Gerenciamento de processos e threads (criar, finalizar, monitorar, configurar, suspender)
- Comunicação via protocolos de rede
- Comunicação entre processos
- Configuração e obtenção do tempo do sistema
- Notificações de erros de sistema
- Configuração e definição de permissões de arquivos e pastas
Dispositivos de entrada e saída (abreviados como I/O em inglês), são geralmente conectados ao barramento de endereços e podem ser controlados ao ler e escrever em endereços específicos.
Isso significa que as mesmas instruções utilizadas para ler e escrever em variáveis na memória, são também utilizadas para comunicar com dispositivos externos como placa de som, HDs, teclado, mouse, etc. Quem faz esse acesso é, no geral, o kernel ou uma aplicação bare metal.
Sistemas operacionais são uma junção do kernel com softwares adicionais que fornecem um ambiente mais amigável para o usuário, fornecendo coisas como :
- Terminal
- Ambiente de área de trabalho com interface gráfica
- Bibliotecas simplificadas que abstraem as chamadas de sistema
- Ferramentas e softwares prontos que realizam algumas tarefas
O interessante é que, não importa o quão alto nível uma aplicação que executa em um sistema operacional seja, é comum que ela precise executar chamadas de sistemas ou utilizar programas e funções fornecidos pelo sistema operacional para realização de diversas tarefas.
Algumas ferramentas podem ser utilizadas para monitorar chamadas de sistemas e/ou funções de bibliotecas do sistema operacional :
API Monitorno Windowsstraceno Linuxdtrace, desenvolvidas inicalmente para Solaris, mas disponível paraFreeBSD,WindowseLinuxCrescendopara MacOsjtracepara uma ferramenta similar aostracepara AndroidIntrospy-Androidpara Androidhookerpara Android
Sistemas embarcados
Um sistema “embarcado” é um conjunto de hardware e software projetado para execução de uma tarefa específica em um sistema maior, para que possam ser integrados em produtos e equipamentos.
Estamos nos referindo a sistemas embarcados quando falamos dos processadores encontrados em televisões, microondas, mouse, carros, eletrodomésticos, impressoras, etc.
É comum que esses sistemas embarcados utilizem microcontroladores, que são sistemas que contêm já no chip diversos periféricos, entradas e saídas integradas, ideal para realizar o controle de motores, leitura de sensores, etc.
Sistemas embarcados ainda são uma área onde a linguagem C tem uma grande dominância no mercado, devido a sua facilidade de integração com o hardware, acesso direto ao endereçamento da máquina, performance e simplicidade.
Um exemplo de microcontrolador é o ESP32 que contêm embutido no seu chip módulo de Wifi, Bluetooth, controladores para protocolos de comunicação com periféricos como SPI e I2C, além de geradores de sinais PWM e conversores analógico-digitais.
Imagem de um ESP32:

É comum que sistemas embarcados utilizem sistemas operacionais RTOS ou nenhum (bare metal).
RTOS
Em sistemas embarcados é comum o uso de sistemas operacionais denominados sistemas RTOS, a sigla significa “Real Time Operating System”, ou seja, sistemas operacionais de tempo real.
Esses sistemas tem um foco maior em garantir execução de tarefas que precisem de baixíssima latência e precisão de tempo na faixa dos microsegundos.
O sistema permite gerenciamento de múltiplas tarefas paralelas que podem ter níveis de prioridade diferente, simplificando muito a implementação de determinadas aplicações.
É comum que sistemas RTOS não tenham um sistema de arquivos, nem o conceito de processos, apenas “threads”, que também são chamados muitas vezes de “tasks” (“tarefas” em inglês), indicando que diferentes tarefas são executadas compartilhando um mesmo espaço de endereçamento.
Em contrapartida, sistemas operacionais convencionais são projetados para que múltiplos processos sejam executados, todos isolados e com endereçamento próprio, junto de um sistema de arquivos, porém com maior latência e menos garantias quanto a precisão de tempo para que cada processo seja “agendado” para executar.
Também é comum que sistemas RTOS permitam criação de threads privilégiados que podem acessar o hardware sem necessidade de executar chamadas de sistema, pois a transição entre a execução do kernel e a aplicação do usuário geralmente é custosa.
O sistema RTOS mais utilizado no mercado é o sistema gratuito FreeRTOS.
Bare Metal
Sistemas “bare metal” não apresentam nenhum sistema operacional, isso significa que não há nenhum kernel para realizar um gerenciamento de recursos, de forma que a aplicação possa utilizar o hardware diretamente sem nenhuma limitação.
O estilo de programação comum em um sistema bare metal é um loop base onde toda atividade acontece, com eventos externos checados periódicamente e/ou utilizando interrupções de hardware.
Desenvolver o sistema em bare metal é recomendado em um dos casos :
- O processador tem recursos extremamente limitados (cada byte importa)
- Não há necessidade de paralelizar múltiplas tarefas (caso houvesse RTOS poderia ser uma boa escolha)
- A precisão de tempo necessária é muito crítica, onde cada nanosegundo conta e uma falha pode ocasionar em um grande prejuízo
Layout de Memória
Para compreender totalmente assuntos mais complexos como alocação de memória, é importante ter uma visão de como é organizada a memória dentro de um programa.
Memória Virtual
Em programas executando dentro de sistemas operacionais, é comum que o uso de memória seja virtualizado, ou seja, não haja um acesso direto a memória física do sistema (no geral, a memória RAM).
A virtualização na memória permite que o sistema limite quais parcelas da memória cada processo realmente tem acesso, evitando que a instabilidade de um programa, comprometa a estabilidade do sistema inteiro.
Nesses casos, existe uma estrutura de dados denominada “tabela de páginas”, que realiza a tradução de um endereço virtual para um endereço físico.
Os valores da tabela de páginas normalmente são guardados em cache pelo processador, esse cache é denominado TLB (Translation Lookaside Buffer). Muitas arquiteturas modernas tem suporte direto a lidar com a tradução de páginas pelo próprio hardware, minimizando absurdamente o custo de performance ao virtualizar o acesso a memória.
O termo “mapear em memória”, indica a introdução de uma nova página de memória no endereçamento virtual do processo, que o dê acesso aos dados de um arquivo, parcela da memória física ou até mesmo a um dispositivo em hardware.
A virtualização também permite que o sistema decida mapear parte do disco ou memória flash caso não haja memória RAM disponível ao alocar memória, evitando que a alocação falhe mesmo quando não há mais RAM.
Lembrando que devido ao comportamento da memória virtual, é possível que arrays que são “sequenciais na memória virtual”, não sejam exatamente sequênciais na memória física.
A imagem abaixo demonstra como ocorre o acesso a memória RAM visto a tabela de páginas e endereçamento virtual :
Código de máquina
Para entender a organização da memória, é importante compreender que código executável, o qual o processador executa, também é composto por bytes assim como dados de um programa, esse código executável em formato binário é chamado de código de máquina.
Quando compilamos um programa em C para um binário pre-compilado, geramos um arquivo executável num formato suportado pelo sistema operacional ou pelo menos os dados necessários para execução de um programa num sistema bare metal.
Nos arquivos de executáveis presentes em sistemas operacionais, temos um cabeçário com várias informações sobre o executável além dos dados para preencher as seções de memória, uma dessas seções é a que contém o código de máquina que será executado, já em sistemas bare metal, definimos como será mapeada cada região e devemos realizar parte da inicialização manualmente.
O entendimento de que código de máquina são apenas bytes também ajuda a entender algumas técnicas utilizadas por hackers como injeção ou uma adulteração de código, onde um código de máquina pode ser sobrescrito ou modificado por um programa malicioso.
O código de máquina efetivamente é composto por vários bytes contendo instruções que o processador deve executar para realizar cada tarefa, algumas dessas instruções contém uma junção de comando + dados codificados nela (como por exemplo nas instruções de pulo ou atribuição).
Uma única linha de código de C pode se tornar várias instruções da máquina que geralmente se resumem a instruções que realizam as tarefas:
- Ler/escrever dados na memória
- Operar com a “stack” (será explicado mais a frente)
- Pular para endereços
- Chamar funções
- Checar condições
- Realizar cálculos aritméticos
- Chamar uma interrupção de software (chamada de sistema, breakpoint, etc)
Cada arquitetura de processador tem um conjunto de instruções diferentes, de forma que os comandos disponíveis, quantos bytes e quais valores são necessários para codificar instruções em comum sejam diferentes para cada arquitetura.
A linguagem assembly lida com essas diferenças pois tem comandos que correspondem diretamente as instruções do processador, sendo necessário um código diferente para cada arquitetura.
Seções de memória
Uma seção de memória, é uma separação lógica usada para separar código de máquina e dados, todas seções são nomeadas e seus nomes geralmente começam com ., cada seção tem geralmente um propósito diferente e serve como uma forma de organização dentro de um executável, alguns nomes geralmente utilizados são:
.text: Utilizada para indicar código de máquina executável.bss: Utilizado para variáveis deduração estáticanão inicializadas.data: Utilizada para guardar variáveis deduração estáticajá inicializadas
Lembrando que a existência ou não de uma seção, depende do formato executável utilizado pelo sistema, ou pela configuração das ferramentas utilizadas para compilar o código para sistemas bare metal.
Os formatos mais utilizados são :
- Portable Executable ou apenas
PEusado no Windows, nomeado como.exee baseado no formatoCOFF. - Executable and Linkable Format ou apenas
ELF, utilizado em sistemas Linux e UNIX - Common Object File Format ou apenas
COFF, utilizado também em sistemas UNIX, mas foi em sua maioria substituido pelo formatoELF. - Mach-O, formato da Apple utilizado pelo MacOs e iOs.
Esses formatos são a forma como arquivos executáveis devem estar para que possam ser carregados pelo sistema operacional.
Uma forma interessante de aprender sobre esses formatos, é utilizar o editor hexadecimal programável ImHex, ele contém scripts automáticos que detectam o formato do arquivo modificado e marcam cada campo do arquivo com nome e cor.
A imagem abaixo demonstra sua utilização no formato executável PE do Windows:
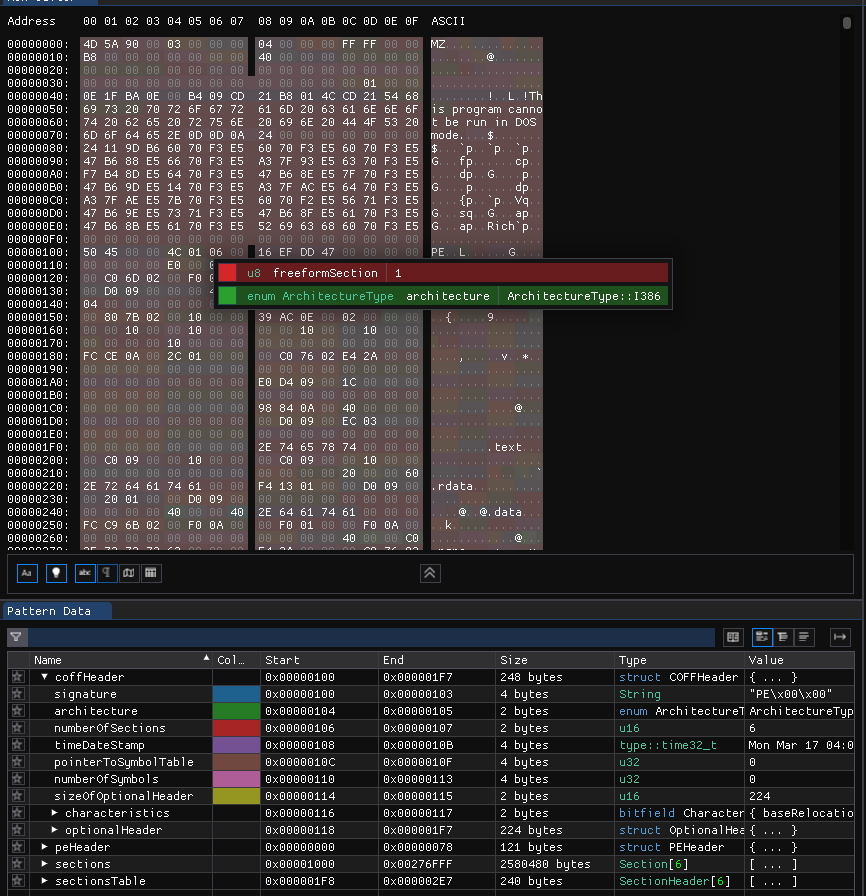
Segmento de memória
Enquanto as seções de memória indicam uma separação lógica dos dados e código de máquina, um segmento de memória indica, geralmente, uma separação mais voltada ao hardware.
Elas são um conjunto de características relacionadas ao hardware que seções de memória fazem parte.
As características que diferenciam segmentos de memória, no geral, são :
- Proteção de memória: permissões de leitura, escrita e execução
- Alinhamento: Podem existir diferenças quanto ao alinhamento de memória no segmento
- Barramento de memória: em algumas arquitetura podem existir barramentos diferentes de memória, pode ser necessário especificar qual deles será utilizado
Cada segmento de memória pode conter uma ou mais seções de memória, logo, podemos pensar nos segmentos como categorias e nas seções como subcategorias.
Seções de memória conhecidas
Para entender melhor sobre as diferentes seções de memória, separamos algumas das seções de memória utilizadas separadas por propósito em cada formato de executável.
O formato COFF é considerado um formato limitado e incompleto, de forma que muitos autores tenham ido além do formato realizando extensões, por isso ele não será mencionado na tabela, visto que até o formato PE é uma extensão do formato COFF.
O formato Mach-O utiliza o prefixo __ no lugar de ., para simplificar a comparação, vamos considerar os nomes como iniciando com . na tabela.
A coluna PE/ELF/MACH-O indica qual é o nome da seção em cada formato. Nos casos onde não há / no valor, significa que o nome da sessão é comum a todos os formatos.
| Propósito | Permissões | Inicialização | PE/ELF/Mach-o |
|---|---|---|---|
| Código executável | Leitura+Execução | Nenhuma | .text |
| Globais não inicializadas | Leitura+Escrita | *1 | .bss |
| Globais inicializadas | Leitura+Escrita | *2 | .data |
| Strings constantes | Leitura | Nenhuma | .rdata/.rodata/.cstring |
| Globais constantes | Leitura | Nenhuma | .rdata/.rodata/.const |
Seções que não incluem permissão de escrita, podem ser mapeadas em memória diretamente e compartilhadas entre múltiplas instâncias do mesmo processo, diminuindo o uso de memória.
No caso de sistemas bare metal, a maioria tem acesso direto a memória flash e não precisam realizar uma cópia de dados constantes para a RAM, mas essa cópia pode ser útil em alguns casos pois o acesso a RAM é geralmente muito mais rápido.
As inicializações de variáveis globais geralmente são realizadas por uma das três opções:
- Pelo sistema operacional ao carregar um executável
- Pela biblioteca padrão do C antes da inicialização da função
main - Por um código de inicialização próprio em sistemas bare metal
-
Uma região com variáveis não inicializadas é preparada ao reservar memória para a região e preenché-la com zeros, a vantagem é que essas variáveis não ocupam espaço no arquivo do executável ou memória flash/magnética do dispositivo pois não precisamos guardar seu valor inicial (apenas um inteiro indicando o tamanho total da região).
-
Uma região com variáveis inicializadas é preparada reservando memória para a região e copiando o conteúdo do arquivo executável ou memória flash/magnética para essa região.
Stack
Cada thread tem uma região de memória reservada como “Stack”, que no português seria uma “Pilha”, utilizada para variáveis locais, de duração automática.
Pilhas normalmente funcionam como uma lista no formato LIFO (Last In, First Out) que no português seria “Último a entrar, primeiro a sair”, onde variáveis são empilhadas no topo e posteriormente removidas.
A motivação da stack é ter uma memória temporária, de acesso rápido, já pre-alocada, na qual o processador pode acessar rapidamente e possívelmente manter em cache para realizar tarefas que não precisem de persistência nos dados.
Várias arquiteturas tem um registrador dedicado chamado de “Stack Pointer” (ou SP) que aponta para a posição atual da stack, junto de várias instruções que adicionam, leem ou removem elementos dela.
Além do Stack Pointer, é comum que exista um registrador como “Frame Pointer”, que aponta para o início das variáveis locais de uma função e simplifica o acesso a variáveis locais, além disso, o endereço de retorno para “voltar ao mesmo ponto de execução” após a execução de uma função, geralmente é guardado também na stack.
Chamamos de “Stack Frame” o conjunto das variáveis locais, endereço de retorno e parâmetros de funções presentes na stack.
A imagem abaixo demonstra a organização da memória na stack ao chamar funções :
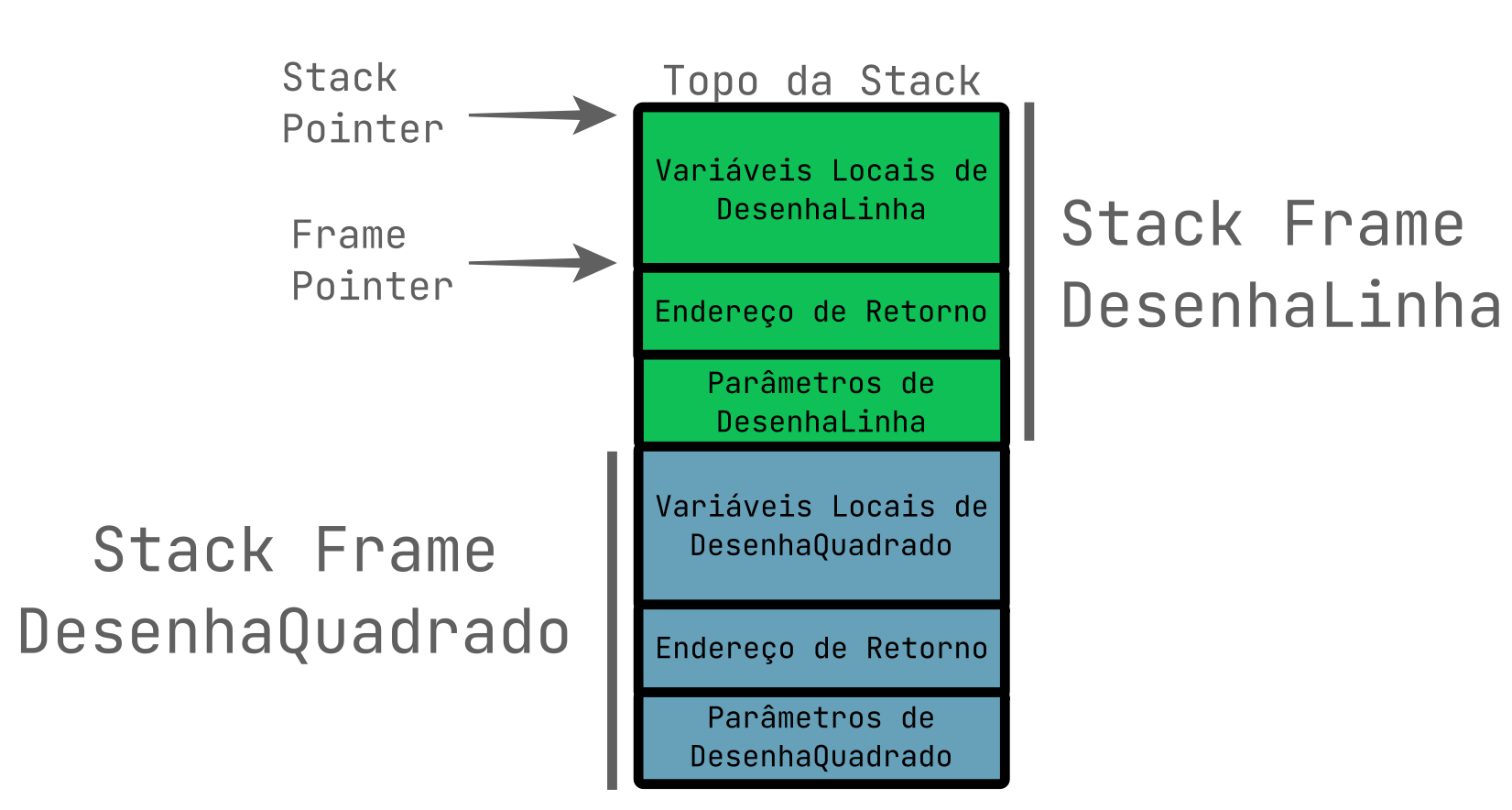
Nas arquiteturas modernas, a conveção mais utilizada é que a stack cresce para baixo, ou seja, decrementamos o endereço do Stack Pointer para adicionar novos elementos, porém isso não é padronizado e existem também arquiteturas onde a stack cresce para cima.
É muito comum que funções “avançem” o stack pointer ao adicionar váriaveis novas e simplesmente “recuem” o stack pointer durante a finalização para liberar todas as variáveis locais da função em uma única operação, tornando a operação da stack extremamente eficiente.
Isso também explica porque variáveis locais tendem a ter valores “aleatórios” caso não sejam inicializadas, a tendência é que elas tenham o último valor que foi colocado naquele endereço da stack.
No sistema operacional Windows, é normal que o tamanho máximo da Stack seja de 1MB, enquanto no linux e MacOs seja de 8MB.
Exceder o limite de tamanho da stack implica num erro que chamamos de “stack overflow”, que normalmente leva o programa a ser finalizado pelo sistema operacional, é comum que esse erro aconteça ao lidar com funções recursivas.
Heap
A heap é como chamamos a região de memória onde guardamos variáveis alocadas dinâmicamente, assunto que será tratado com mais detalhes no próximo capítulo.
Toda memória da heap deve ser acessada indiretamente via ponteiro, pois não há como saber com antecedência qual será o endereço recebido ao alocar memória, ela também deve ser “liberada” manualmente, de forma que a memória possa ser reutilizada por outros processos ou em novas alocações.
No linux, por exemplo, é comum que as regiões .bss, .data e a heap, façam parte do segmento data, que compoem um segmento com permissões de leitura e escrita.
A função padrão do C para alocação, malloc é implementada pela GLIBC (biblioteca padrão do C pelo projeto GNU) no linux usando duas funções do sistema dependendo do tamanho da alocação :
- Para alocações menores que 128KB, utiliza-se a função de sistema
brk, que modifica onde é o fim do segmentodata, o que acaba por alocar ou desalocar memória, utilizar essa função manualmente pode causar conflito commalloc, portanto recomenda-se evitar seu uso por código do usuário. - Para alocações maiores que 128kb, a GLIBC utiliza a função
mmap, que mapeia uma nova região de memória separada do segmentodata, mas que funciona de forma independente, e pode ser desalocada de forma individual.
A vantagem de brk sobre mmap é que ela é mais rápida, porém vem com diversas desvantagens:
- As alocações “expandem” o segmento
data, se houver outra coisa mapeada no caminho que impeça o segmento de crescer,mmapse tornará a única forma de alocar memória - Ela não é amigável para código multithread, pois toda alocação de memória deve ser gerenciada de forma unificada
- A necessidade de unificar o gerenciamento de memória dificulta a presença de outros alocadores e pode conflitar com outras bibliotecas
Bibliotecas de Vínculo Dinâmico
Existem algumas bibliotecas especiais chamadas de bibliotecas de vínculo dinâmico, são efetivamente arquivos executáveis “especiais”, que podem ser carregados para dentro de outros executáveis.
O formato de arquivo utilizado em cada uma dessas bibliotecas, ainda é o mesmo formato utilizado por executáveis na mesma plataforma, porém com valores diferentes nos cabeçários do arquivo.
As extensões utilizadas em cada sistema é :
.dll(Dynamic Link Library) para bibliotecas de vínculo dinâmico no formatoPEno windows..so(Shared Object) para bibliotecas de vínculo dinâmico no formatoELFno linux e outros sistemas UNIX..dylib(Dynamic Library) para bibliotecas de vínculo dinâmico no formatoMach-Ono macOs e iOs.
As bibliotecas de vínculo dinâmico geralmente podem ser carregadas de uma das seguintes formas :
- Adicionando a função na tabela de importação no cabeçário do executável (torna a biblioteca uma depedência para que o executável funcione)
- Carregando a biblioteca durante tempo de execução utilizando alguma função do sistema operacional
Em alguns casos, existem bibliotecas estáticas, que podem ser vinculadas junto com o executável, que já adicionam os dados necessários na tabela de importação do executável, simplificando o processo de importar as bibliotecas.
Adicionar funções na tabela de importação pode não ser uma boa idéia se não houver uma garantia maior de que a biblioteca existe, pois uma falha em carregar a biblioteca resultará em uma falha em executar o programa.
Nesses casos, carregar a biblitoeca durante tempo de execução pode ser uma opção melhor, para isso, são utilizadas as funções :
| Ação | Windows | Linux/Android | macOs/iOs |
|---|---|---|---|
| Carregar uma biblioteca | LoadLibraryW | dlopen | dlopen |
| Procurar um símbolo | GetProcAddress | dlsym | dlsym |
| Descarregar biblitoeca | FreeLibrary | dlclose | dlclose |
Uma das grandes “vantagens” de bibliotecas de vínculo dinâmico, é que múltiplos processos podem “reutilizar” a mesma biblioteca, minimizando o uso de memória e evitando a presença de múltiplas cópias “do mesmo código”.
É muito comum que a biblioteca padrão do C seja distribuida como uma biblioteca de vínculo dinâmico, o que permite que ela seja atualizada e vulnerabilidades nela sejam corrigidas, sem exigir uma recompilação de todos os programas do sistema inteiro.
Bibliotecas dinâmicas na memória
As bibliotecas dinâmicas fazem parte do layout da memória da maioria dos processos em um sistema operacional moderno, como cada uma delas é um executável embarcado, cada biblioteca tem suas próprias seções de memória.
Na figura abaixo, retirada do programa x64Dbg (debugger e patcher de assembly para engenharia reversa), podemos ver as seções de memória de algumas DLLs carregadas em um processo :
Tabela de importação
Para os casos onde as bibliotecas de vínculo dinâmico são carregadas durante a inicialização do programa, elas precisam ser referenciadas na tabela de importação do executável.
A tabela de importação contém uma lista com os nomes das bibliotecas e os nomes das funções que devem ser importadas, bem como uma lista de endereços que serão preenchidos pelo sistema operacional com os endereços das funções carregadas.
Não há garantia quanto ao endereço em que uma biblioteca dinâmica será carregada muito menos que ela continue com o mesmo tamanho em versões posteriores.
Portanto, as funções de bibliotecas dinâmicas precisam ser chamadas de forma indireta, utilizando os ponteiros de função preenchidos na tabela de importação, tudo isso é feito de forma transparente para o programador em C.
A imagem abaixo demonstra algumas funções importadas de bibliotecas dinâmicas em um executável visualizadas no x64Dbg:
Os endereços a esquerda são os endereços base de cada módulo, enquanto os endereços a direita são os endereços de cada ponteiro de função que referencia uma função importada.
Visão Geral
Podemos dizer que no geral, um programa geralmente tem uma stack, heap e as regiões .bss, .data, .text e alguma das regiões para constantes globais.
Uma visão geral de como funciona o layout de memória num processo no linux pode ser visto na figura abaixo, com as setas indicando para qual direção a heap e stack crescem, lembrando que a imagem não leva em consideração páginas adicionais alocadas via mmap:
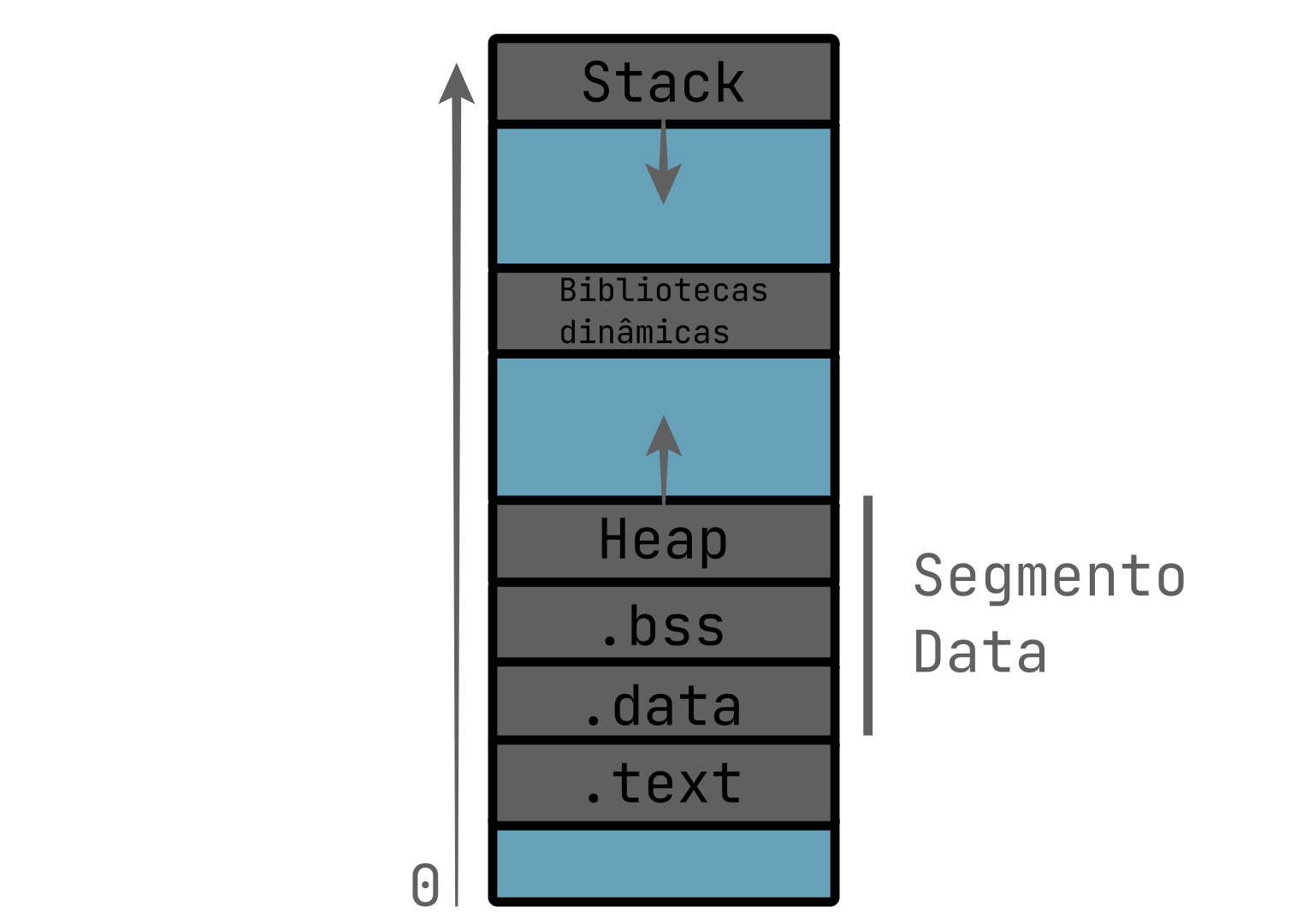
Alocação Dinâmica de Memória
Como exemplificado no capítulo sobre layout de memória, um programa pode alocar memória dinâmicamente, e geralmente chamamos toda região de memória alocada dessa forma de “heap”.
A linguagem C fornece, através da sua biblioteca padrão e expõe pelo header stdlib.h funções para realizar o gerencimento manual dessa memória, fornecendo funções que alocam, realocam e liberam memória dinamicamente.
Quando alocamos memória, estamos efetivamente reservando uma quantidade específica de bytes para algum uso específico.
Funções para alocação
Para realizar a alocação de memória, existem 3 funções da biblioteca padrão: malloc, calloc e aligned_alloc.
malloc
malloc é a principal função para alocação de memória, e tem a seguinte sintaxe :
void *malloc(size_t tamanho);
Onde tamanho é a quantidade de bytes que devem ser alocados e o retorno é um void* indicando o endereço da memória alocado, ou NULL caso a alocação falhe.
A memória alocada com malloc não tem nenhuma garantia quanto ao seu conteúdo inicial, é comum que seu conteúdo seja similar ao de uma variável não inicializada da stack.
O alinhamento da memória alocada é o maior alinhamento que qualquer tipo possa ter, equivalente ao alinhamento do tipo max_align_t do C11.
Essa memória posteriormente pode ser liberada utilizando free ou alguma das outras funções de liberar memória da stdlib.h que serão mencionadas mais a frente.
Utilizar 0 como tamanho pode, dependendo da implementação, retornar NULL ou um ponteiro válido que não pode ser acessado mas ainda deve ser liberado.
Acessar memória além do que foi alocado gera um comportamento indefinido, que pode sobrescrever/ler outras variáveis ou causar uma finalização forçada do programa pelo sistema operacional.
Exemplo de uso da função malloc:
int main()
{
//Aloca memória para 10 inteiros
int *quadradosPerfeitos = malloc(sizeof(int) * 10);
for(int i = 0; i < 10; i++)
quadradosPerfeitos[i] = (i+1) * (i+1);
//Libera a memória utilizada
free(quadradosPerfeitos);
}
É comum que ao alocar memória, o sistema operacional simplesmente “marque” que uma região do endereço virtual de um processo é válido, sem efetivamente reservar memória física para ele.
Quando o usuário acessa (tenta ler/escrever no endereço alocado) ocorre um erro interno no sistema denominado de “falha de página”, isso faz com que uma função do kernel seja chamada para lidar com o erro, essa função efetivamente prepara essa página de memória, e retorna o fluxo de execução ao programa do usuário.
Esse mecanismo faz com que a memória só seja efetivamente consumida, após ser utilizada pela primeira vez.
calloc
Assim como a função malloc existe a função calloc que pode ser utilizada para alocar memória onde todos os bytes são zero.
A sintaxe para uso de calloc é :
void *calloc(size_t num, size_t tamanho);
Apesar de ter 2 parâmetros, o tamanho final da alocação é efetivamente a multiplicação num * tamanho e o comportamento é exatamente o mesmo de malloc, exceto pela memória alocada ser inicializada com 0.
Lembrando que ponteiros nulos não necessariamente são compostos por bytes zerados, apesar desse ser o comportamento padrão em boa parte se não de todos sistemas modernos.
A motivação pelo uso de dois parâmetros é histórica e não tem mais um propósito efetivo nos dias de hoje.
Alguns guias e autores erroneamente falam que utilizar calloc é efetivamente igual a chamar malloc + memset para zerar a memória, mas essa constatação está errada.
Devido ao mecanismo de muitos sistemas operacionais de esperar o primeiro acesso para realmente alocar, uma alocação realizada com calloc pode tirar proveito disso e ser muito mais rápida sem consumir memória até seu primeiro uso.
aligned_alloc
A função aligned_alloc foi introduzida no C11, seu propósito é realizar uma alocação similar a malloc porém controlando o alinhamento de memória.
void *aligned_alloc(size_t alinhamento, size_t tamanho);
A função tem comportamento extremamente similar a malloc, porém utilizando o alinhamento definido pela função.
Podemos dizer que malloc é efetivamente equivalente a uma chamada de aligned_alloc da seguinte forma:
void *ptr = aligned_alloc(_Alignof(max_align_t), tamanho);
Realocação de memória
Quando há necessidade de expandir ou diminuir o uso de memória de uma alocação feita anteriormente, utilizamos a função realloc, que tem a seguinte sintaxe:
void *realloc(void *ptr, size_t tamanho);
ptr é o ponteiro para a memória previamente alocada com malloc, calloc ou aligned_alloc ou NULL.
tamanho é o novo tamanho da memória realocada, não recomenda-se passar 0 como tamanho pois o comportamento para tal é definido pela implementação e desde o C23 se tornou indefinido (permitindo que implementações tratem esse caso como bug e façam qualquer coisa).
A função retorna o novo bloco realocado, ou NULL caso haja uma falha em realocar, nesse caso o bloco ptr ainda é válido e não é liberado por realloc.
A ideia por trás do realloc é que existem dois comportamentos possíveis ao realizar uma realocação :
- A região já alocada por
ptré expandida ou contraida, se possível. os conteúdos da região antiga que estará contida na região nova são mantidos. - Uma nova região é alocada, o conteúdo da região antiga é copiado para ela e o bloco antigo é liberado.
Lembrando que caso o segundo comportamento seja escolhido devido a uma falha em expandir/contrair a região atual, será necessário ter, mesmo que temporariamente, memória o suficiente para a existências das duas regiões de memória (a antiga e a nova) para que seja possível copiar os conteúdos da região antiga para a nova.
Também é comum que algumas implementações utilizem o seguinte código ao realizar uma realocação :
ptr = realloc(ptr, tamanho);
Isso não é exatamente ideal, pois no caso da alocação falhar, teremos efetivamente perdido o valor do endereço da região original, chamamos essa “perda de referência” de vazamento de memória.
Uma forma ideal de utilizar realloc lidando com erros corretamente seria :
void *novoPtr = realloc(ptr, novoTamanho);
if(novoPtr != NULL) {
ptr = novoPtr;
tamanho = novoTamanho;
} else {
fputs(stderr, "Erro ao realocar memória no arquivo %s e próximo a linha %d\n",
__FILE__, __LINE__);
}
Funções para liberar memória
Para liberar o uso de memória e permitir que novas alocações ou outros programas no sistema utilizem a memória, existem 3 funções diferentes: free, free_sized e free_aligned_sized.
free
free é a principal função para liberar o uso de memória pelas funções de alocação e realocação, até o C23 era a única função para tal.
A sintaxe para uso da função é extremamente simples :
void free(void *ptr);
ptr é o ponteiro para o ínicio do bloco alocado com qualquer uma das funções de alocação/realocação da biblioteca padrão do C.
Se ptr for um ponteiro nulo, a função free não faz nada.
Ao utilizar free, a memória alocada pelas funções é marcada como inultilizável, permitindo que ela seja devolvida ao sistema operacional ou reutilizada em futuras chamadas para as funções de alocação.
O comportamento de free é indefinido se a memória de ptr não foi alocada com alguma das funções de alocação da biblioteca padrão do C ou já foi inultilizada por uma chamada anterior a free.
Os erros causados por chamar free duas vezes são considerados erros comuns de programação em C.
Muitos tendem a anular o ponteiro após uma chamada a free, impossibilitando que esse erro aconteça por descuido:
free(ptr);
ptr = NULL;
Também é comum que programadores reforçem a necessidade de chamar free com toda memória alocada pelas funções da biblioteca do C, isso será discutido com detalhes mais frente.
free_sized
No C23, a função free_sized foi adicionada como uma forma adicional de liberar a memória e funciona com todas funções de alocação/realocações exceto aligned_alloc.
A função apresenta um parâmetro extra especificando o tamanho da alocação original :
void free_sized(void *ptr, size_t tamanho);
Onde tamanho seria o tamanho utilizado para previamente realizar a alocação.
Existem duas possíveis vantagens/motivações ao utilizar free_sized que podem ser flexibilizadas dependendo da implementação efetiva:
- Prover uma segurança maior, onde uma diferença entre o tamanho esperado/real permita que a implementação encerre o programa, ajudando a identificar o problema (a função não tem retorno, portanto essa é a única alternativa)
- Melhorar a performance, permitindo que a memória seja liberada sem necessidade de buscar pelo seu tamanho, estima-se que a performance das implementações pode subir em até 30% eliminando essa etapa
É importante lembrar que a decisão final do que efetivamente será feito com essa nova função depende das implementações da biblioteca do C, algumas podem decidir focar mais no aspecto de segurança, outras no de performance.
Inclusive nenhuma implementação é obrigada a se beneficiar das vantagens dessa nova função, sendo ainda válido implementar free_sized como :
void free_sized(void *ptr, size_t /*tamanho*/)
{
free(ptr);
}
free_aligned_sized
Similar a função free_sized, também introduzida no C23, porém preparada para lidar com alloc_aligned.
A sintaxe para função é muito similar a free_sized, sendo necessário também informar o alinhamento utilizado em alloc_aligned :
void free_aligned_sized(void* ptr, size_t alinhamento, size_t tamanho);
Todas as vantagens e explicações a cerca de free_sized também se aplicam a função free_aligned_sized.
Fragmentação de memória
Um problema que pode ocorrer ao realizar muitas alocações é a fragmentação da memória, dizemos que a memória está fragmentada quando os blocos de memória livre estão muito separados.
Em alguns casos mesmo que o sistema tenha memória disponível para realizar uma alocação, ela ainda pode falhar devido a fragmentação de memória.
A fragmentação de memória percebida nos processos geralmente não é uma fragmentação da memória física, mas sim uma fragmentação da memória virtual.
É possível por exemplo, que um programa 32bits falhe em alocar memória devido a fragmentação de seu endereçamento virtual, mesmo que ele esteja executando em um sistema operacional 64bits com memória RAM sobrando.
Algumas linguagens que apresentam gerenciamento automático de memória geralmente tem suas variáveis alocadas na heap reorganizadas na memória para evitar a fragmentação, isso fica mais evidente ainda quando linguagens como C# tem palavras chave como fixed que impedem o runtime da linguagem de mudar o endereço de uma variável.
Quanto a necessidade de liberar memória
É necessário ter muito cuidado quando alocamos memória, é sempre bom pensar muito sobre o periodo em que aquela memória precisa se manter alocada e quais as condições para que ela deixe de ser utilizada e seja liberada.
Recomenda-se sempre liberar a memória alocada nos casos onde ela não será utilizada durante toda execução do programa, principalmente quando o programa tem uma vida útil longa.
Dessa forma, é comum que muitos autores, guias e programadores em C relembrem constantemente a necessidade de sempre chamar a função free e liberar toda memória em uso antes da finalização do programa.
Porém existem casos onde liberar a memória não é exatamente necessário, apenas considerada como uma boa prática.
Nos sistemas operacionais modernos, quando alocamos memória estamos efetivamente criando novas páginas na tabela de páginas do sistema, quando um processo finaliza, é responsabilidade do kernel recuperar toda memória alocada pelo processo e isso ocorre de maneira automática.
A recuperação da memória virtual pelo kernel ocorre de página em página de memória, que geralmente tem tamanho de 4KB, essa liberação é muito mais simples e eficiente do que o trabalho necessário para liberar memória pela função free.
Porém em sistemas RTOS, bare metal ou sistemas operacionais antigos e primitivos pode não existir efetivamente uma memória virtual ou um sistema que libere a memória do processo automáticamente na finalização.
Situações e pontos a favor de liberar sempre a memória:
- Para iniciantes, obter a prática de sempre liberar memória é extremamente benéfica
- Em praticamente todos os casos onde a memória não vai mais ser utilizada, liberar a memória é a coisa certa a se fazer, pois estamos permitindo que outras alocações e outros programas utilizem essa memória.
- Lida melhor com sistemas antigos ou com recursos limitados, que podem não desalocar a memória após a finalização do programa
- Não liberar memória pode gerar “falsos positivos” em ferramentas como
valgrindque detectam vazamentos de memória, visto que não liberar é um “vazamento intencional”
Considerações extras (considerando um sistema operacional moderno):
- Liberar a memória com
freeé mais lento e necessita de mais trabalho do que a finalização automática realizada pelo sistema - Não há uma necessidade real de liberar memória logo antes de finalizar um programa
- Podemos chamar a função
exitou similares e finalizar previamente um programa sem medo de “vazar memória do sistema”
Erros comuns e causas ao gerenciar memória
Gerenciamento de memória é um assunto relativamente simples, mas que continua sendo uma das maiores causas de vulnerabilidades e defeitos em programas.
Por isso, é bom evidenciarmos os problemas que podem acontecer, as possíveis causas e como podemos evitar esses problemas.
Vazamento de memória
Um vazamento de memória ocorre quando perdemos o valor do ponteiro de uma região de memória previamente alocada, de forma que não seja mais possível liberar a memória.
Possíveis causas :
- Alocar uma
structque guarda ponteiros para outras alocações e esquecer de desalocar a memória deles antes de desalocar astruct - Sobrescrever um ponteiro de uma alocação antiga com um ponteiro de uma alocação nova, sem que a região antiga tenha sido liberada.
- Uso incorreto de
realloc(esquecendo de manter o ponteiro em outra variável, como listado anteriormente) - Utilizar funções de bibliotecas externas de maneira incorreta, sem respeitar as recomendações da documentação
- Funções ou bibliotecas externas que tem um vazamento internamente
Um dos sintomas que podem indicar um vazamento de memória, é que o uso de memória sempre cresça quando realizamos uma sequência de etapas que deveria alocar e desalocar um ou mais recursos. (ex: abrir uma janela, realizar uma mesma ação e fechar ela, depois repetir o processo).
Podemos evitar vazamentos de memória de várias formas :
- Utilizando ferramentas de detecção especializadas como
valgrind(o valgrind especificamente só funciona no linux, alguns projetos usam wine para testar aplicações de windows no linux com valgrind) - Criar um header que substitui as chamadas de
malloc,freee afins por macros que formam uma lista comendereço alocado,nome do arquivoenúmero da linha, removendo-a da lista na chamada defreee reportando todos os vazamentos na finalização utilizando a funçãoatexit, como faz o projetoLeakyno Github.
Liberação Dupla
Após liberar a memória, chamar outra função de liberar memória causa comportamento indefinido, como já foi descrito na explicação sobre free.
Possíveis causas :
- O ponteiro é compartilhado e usado em mais de uma variável, portanto uma parcela do código não está ciente que a memória foi liberada
- O código não lida ou não marca corretamente que a variável foi desalocada e acaba tentando desalocar ela novamente
- Uso incorreto de bibliotecas externas, apesar de um pouco mais incomum
Podemos resolver ou detectar problemas de liberação dupla :
- Simplesmente utilizando um debugger, pois esses problemas geralmente finalizam o programa de forma inesperada e podem ser diagnosticados, analisando o valores das variáveis e a pilha de chamadas.
- Utilizando uma implementação similar ao
Leakymencionado anteriormente, porém checando se os blocos alocados já foram liberados e reportando esse erro, o que permitiria um diagnóstico - Utilizando
valgrind - Anulando as variáveis que carregam o ponteiro após liberar a memória pela primeira vez (que de preferência, seja apenas uma)
- No caso de múltiplas variáveis referenciando o mesmo ponteiro, podemos utilizar um contador de referência e liberar a memória quando a contagem chegar a
0
Uso após free
Após liberarmos uma região alocada, utilizá-la novamente é efetivamente um erro e causa comportamento indefinido.
As causas do uso após free são extremamente similares as causas da Liberação Dupla pois ambos remetem a um desconhecimento quanto a primeira liberação da região alocada.
A diferença maior é que o erro não acontece em uma chamada de função que poderia ser subtituida por macros e sim num acesso genérico direto ou indireto de uma região de memória, dificultando o diagnóstico.
Podemos resolver ou detectar problemas de uso após free:
- Combinando a prática de zerar os ponteiros após
freejunto de checagens constantes de ponteiro nulo em pontos chave do código - Utilizando debuggers para detectar a causa do erro e resolver
- Utilizando contadores de referência e checando se a contagem é zero
- Utilizando
valgrind
Sobre uso de alocadores no windows
É comum que no windows, alguns projetos se recusem a usar malloc/free, pois preferem utilizar as funções HeapAlloc e HeapFree, entre eles a linguagem Rust, pelos seguintes motivos :
- A implementação do
mallocda biblioteca padrão do C utilizaHeapAlloc, então ela é apenas uma camada adicional em cima dessas mesmas funções - O runtime padrão do C usa sua própria heap (
__crtheap) no lugar da heap do processo obtida comGetProcessHeap, aumentando a fragmentação de memória pela mistura dos dois tipos de alocação visto que a heap do processo é usada por funções do sistema. - Utilizar essas funções permite que um ponteiro em uma DLL seja liberado em outra, usar
malloc/freenesse caso leva a comportamento indefinido
Como outras linguagens gerenciam memória
Outro ponto que ajuda a compreeender melhor, é entender como outras implementações de linguagens efetivamente gerenciam a memória ou mesmo quais ferramentas elas oferecem para ajudar nisso.
Python,Javascript,Java,C#: Utilizam o que chamamos de Garbage Collector (no português, coletor de lixo), que periodicamente pausa a execução e realiza uma análise verificando as variáveis da heap em uso, liberando o que não é mais utilizado, efetivamente removendo a necessidade do programador de se preocupar com isso.C++: Muitas classes utilizam o conceito de RAII (Resource Acquisition Is Initialization, no português “aquisição de recurso é inicialização”), onde a criação de uma variável aloca memória e a destruição dela desaloca a própria memória, isso também pode ser feito de maneira individual com os ponteiros inteligentesstd::unique_ptrestd::shared_ptr(shared_ptrusa um contador de referência eunique_ptrlibera a memória ao sair do escopo).Rust: No Rust o comportamento padrão é que alocações de memória da heap tem sempre uma variável que é “dona” da memória e somente quando ela deixa o escopo, a memória é liberada, o Rust tem suas próprias regras que mantêm esse comportamento sempre consistente e gera erros quando usado de forma incorreta, além de ter seus próprios tipos de ponteiros inteligentes comoBoxeRc(equivalentes aunique_ptreshared_ptrdo C++ respectivamente).Swift: A linguagem Swift utiliza contadores de referência para todas as variáveis alocadas na heap, isso garante que ela libere a memória apenas quando não houver mais nenhuma variável referenciando o valor.
Quanto as implicações da estratégias utilizadas pelas linguagens:
- Utilizar garbage collector é mais custoso em relação a performance, porém elimina totalmente as preocupações quanto ao gerenciamento de memória.
- Utilizar contagem de referência para todas variáveis alocadas dinâmicamente é geralmente mais eficiente do que utilizar um garbage collector.
- Os métodos do Rust e do C++ são os mais eficientes, onde temos abstrações de “custo zero” para desalocar memória, o único problema é que elas introduzem complexidade adicional na escrita do código.
Uso de memória dinâmica em sistemas embarcados
Em sistemas embarcados, é normalmente desaconselhado o uso de memória dinâmica por vários motivos :
- Mal uso de alocação dinâmica é uma grande causa de vários erros, erros que muitas vezes não deveriam ocorrer nunca em sistemas embarcados que desempenham tarefas críticas
- O tempo para execução de
malloc,freee similares não é deterministico, que podem ter um impacto significativo na performance e afetar o tempo de tarefas críticas - É comum que apenas um programa seja executado num sistema embarcado, não exista outros programas competindo pela memória disponível
- Usar apenas memória estática (com variáveis globais ou
staticem funções), simplifica a detecção e análise de problemas relacionados ao uso de memória
Algumas dessas regras e outras relacionadas ao desenvolvimento de código crítico para embarcados em C pode ser visto nos documentos da NASA e MISRA C.
Memória dinâmica vs Memória estática
Apesar dos problemas mencionados no uso de memória dinâmica em sistemas embarcados, existem ainda diversas vantagens no uso de memória dinâmica e alguns outros pontos negativos não mencionados.
Vantagens ao usar memória dinâmica :
- Utilizar memória dinâmica permite que a memória seja utilizada sob demanda, apenas quando é realmente necessária, sendo ideal no caso onde múltiplos programas precisam compartilhar o uso da memória física, como ocorre na maioria dos sistemas operacionais
- É muito mais fácil separar e implementar código de bibliotecas para que a memória seja utilizada e preparada apenas quando solicitada, inclusive repassando a responsabilidade de gerenciar a memória ao chamador da função
- Permite também o uso da heap como memória temporária, quando a memória da stack não é grande o suficiente
- Não há necessidade de definir limites fixos para tudo, listas e arrays podem crescer desde que haja memória para tal
Desvantagens ao usar memória dinâmica:
- Tempo de execução aumentado para alocar e liberar memória
- Mal uso de alocação de memória é fonte de diversos bugs e vulnerabilidades
- Memória obrigatóriamente precisa ser acessada de forma indireta via ponteiro, introduzindo um pequeno custo de performance no acesso
Alocadores Arena
O alocador arena é um alocador extremamente simples, que usa a mesma estratégia da memória stack para alocações.
A vantagem do alocador arena é que ele é muito mais eficiente e a alocação de memória/desalocação é extremamente rápida e trivial (visto que basta avançar/recuar um ponteiro).
Porém, o alocador arena é obrigado a desalocar começando pelos últimos elementos alocados, seguindo a ordem de LIFO exatamente igual a uma pilha.
Utilizar um alocador arena também pode ser benéfico para diminuir a complexidade ao gerenciar memória manualmente, ao invés de gerenciar múltiplas alocações individuais, é mais simples realizar múltiplas desalocações de uma vez em um único ponto.
É possível implementar um alocador arena utilizando malloc e free, mas é muito mais eficiente utilizar mmap no linux/macOs, VirtualAlloc no windows ou até mesmo uma função própria de alocação de algum outro sistema.
Existe também um truque que pode ser feito ao combinarmos a capacidade de funções como mmap e VirtualAlloc de reservar endereçamento de memória sem alocar junta da disponibilidade de endereçamento de memória presente em aplicações 64bits (onde um ponteiro permitiria até 16 exabytes de endereçamento) para reservar espaços enormes e permitir realocações que expandam/contraiam o bloco de memória virtual de forma garantida.
Exemplo de implementação do alocador arena em 64bits no linux
#include <stdlib.h>
#include <stdbool.h>
#include <sys/mman.h>
#define PAGE_SIZE 4096 //4kb
#define RESERVED_SIZE (1 << 35) //32GB
struct Arena {
size_t commited;
size_t size;
void *base;
};
static inline size_t round_to_page(size_t value)
{
size_t round_value = (~value + 1) & (PAGE_SIZE - 1);
return value + round_value;
}
static bool arena_commit(struct Arena *arena, size_t size)
{
size = round_to_page(size);
if(arena->commited + size > RESERVED_SIZE)
return false;
void *addr = (char*)arena->base + arena->size;
int result = mprotect(addr, size, PROT_READ | PROT_WRITE);
if(result != -1)
arena->commited += size;
return (result != -1);
}
struct Arena arena_create(size_t commit_size)
{
struct Arena arena;
arena.size = 0;
arena.commited = 0;
commit_size = round_to_page(commit_size);
arena.base = mmap(NULL, RESERVED_SIZE, PROT_NONE, MAP_PRIVATE | MAP_ANONYMOUS, 0);
if(arena.base == MAP_FAILED)
arena.base = NULL;
else if(commit_size > 0)
arena_commit(&arena, commit_size);
return arena;
}
void *arena_push(struct Arena *arena, size_t size)
{
size_t rem_size = arena->commited - arena->size;
if(rem_size < size && !arena_commit(arena, size - rem_size))
return NULL; //Falha ao extender a região
void *addr = (char*)arena->base + arena->size;
arena->size += size;
return addr;
}
void arena_pop(struct Arena *arena, size_t size)
{
if(size <= arena->size)
arena->size -= size;
else
arena->size = 0;
}
void arena_clear(struct Arena *arena)
{
arena->size = 0;
}
void arena_free(struct Arena *arena)
{
if(arena->base != NULL) {
munmap(arena->base);
arena->base = NULL;
}
}
Veja que, ao alocar memória sem especificar a proteção de memória, estamos efetivamente apenas reservando espaço no endereçamento virtual do processo.
A função mprotect permite modificar a proteção de memória e introduzir permissões de leitura/escrita, o que permite que a página seja acessada e posteriormente adicionada pelo sistema operacional.
Arquivos
Para este capítulo, assume-se que o leitor tenha conhecimento básico sobre o terminal, além da saída e entrada padrão.
Um arquivo é uma coleção de dados ou informações vinculados a um nome.
É normal que arquivos estejam separados em pastas (também chamados de diretórios), pastas são usadas para agrupar e armazenar arquivos e/ou outras pasta, sendo também referenciadas por nome.
A junção de arquivos e pastas forma um sistema hierárquico agrupado por pastas, denominado de sistema de arquivos, que deve ser implementado devido a natureza linear dos dispositivos de armazenamento.
Como os sistemas devem ser implementados, geralmente via software, a implementação e forma como os dados são representados dentro de um dispositivo de armazenamento definem o formato do sistema de arquivos, alguns formatos conhecidos são NTFS, APFS, ext4, exFat, FAT32, etc.
Cada formato de sistema de arquivos fornece diferentes capacidades, otimizações, funcionalidades e metadados.
Metadados são informações sobre um arquivo ou dado, alguns sistemas de arquivo tem suporte a metadados de arquivos como datas de modificação, data de criação e data de último acesso, entre outros.
Diferenças entre sistemas operacionais
Uma das grandes diferenças entre os sistemas que seguem a especificação POSIX (Linux, macOs, FreeBSD e afins) e o Windows é o tipo de caractere utiilizado.
O Windows utiliza internamente UTF-16 para strings e todos compiladores no Windows históricamente utilizam wchar_t como UTF-16, podemos dizer que as funções do Windows internamente aceitam o tipo wchar_t e não char, portanto toda função que interage com o sistema de arquivos utilizando char deve internamente realizar conversões para wchar_t.
O problema dessa diferença do Windows é que se a localidade não for corretamente configurada com a função setlocale, podemos ter problemas ao lidar com arquivos que contêm caracteres especiais como acentuações, emojis, etc. Isso piora ainda mais quando percebemos que o suporte ao encoding UTF-8 utilizando setlocale só surgiu no Windows 10 com o ambiente de execução UCRT.
Já sistemas POSIX normalmente utilizam UTF-8 e char, facilitando bastante a integração com a linguagem C.
Um detalhe adicional é que, os kernels de sistemas POSIX e Windows, no geral, não realizam uma validação das strings para verificar se são UTF-8 ou UTF-16 válido, todas strings são meramente tratadas como dados genéricos e, no geral, apenas os caracteres separadores de pastas (/ no POSIX, \ no Windows) tem um tratamento especial, portanto existe a possibilidade dos nomes de arquivos e pastas conterem UTF-8 ou UTF-16 malformado, esse detalhe nos leva a classificar os formatos utilizados como WTF-8 e WTF-16.
Para testar se a conversão funciona propriamente no Windows, crie um arquivo chamado 😀.txt e teste o código abaixo:
#include <stdio.h>
#include <locale.h>
int main()
{
setlocale(LC_ALL, "portuguese.utf8");
rename("😀.txt", "👀.txt");
}
Caso o arquivo não seja renomeado para 👀.txt, significa que o ambiente de execução do C utilizado não suporta utf-8, a alternativa a isso é utilizar diretamente as funções do sistema no Windows, que aceitam strings em UTF-16 diretamente.
Arquivos em C
A biblioteca stdio.h fornece algumas funções que podemos utilizar para interagir com o sistema de arquivos de forma portável em C.
Um arquivo em C normalmente é descrito pelo tipo FILE*, que é um ponteiro para um tipo de dado que pode ser diferente em cada sistema operacional ou ambiente, sendo aconselhável que o usuário evite acessar diretamente seus campos e prefira utilizar funções para operar com o FILE*.
O tipo FILE* descreve um “fluxo de bytes”, ou no inglês “byte stream”, ele é chamado de fluxo pois indica um fluxo para escrita e/ou leitura de bytes, onde cada operação de leitura ou escrita avança a posição no fluxo que também pode ser chamado de “posição do arquivo”.
A ideia de utilizar um fluxo de arquivos para ler um arquivo “aos poucos”, também permite que seja possível ler de arquivos com gigabytes de tamanho sem consumir muita memória, lendo pequenos pedaços por vez e processando os dados conforme são lidos.
Um FILE* é composto de :
- Largura de caracteres: não definido, normal ou wide
- Estado de conversão, para conversão entre caracteres de múltiplos bytes e o tipo
wchar_t - Estado de bufferização: sem bufferização, bufferização por linha ou bufferização completa
- O buffer, que pode ter seu tamanho modificado ou trocado por um externo, utilizando a função
setvbuf - Permissões: leitura, escrita ou ambos
- Indicador de modo binário/texto
- Indicador de fim de arquivo
- Indicador de erro
- Indicador de posição do arquivo
- Desde o
C11, travas que evitam condições de corrida quando múltiplos threads lêem, escrevem ou modificam/lêem a posição do arquivo
A tabela a seguir demonstra as funções disponíveis e sua respectiva funcionalidade:
| Função | Descrição |
|---|---|
| fopen | Abre ou cria um arquivo |
| fread | Lê do arquivo |
| fwrite | Escreve no arquivo |
| freopen | Abre ou cria um arquivo sobrescrevendo um FILE* existente |
| fclose | Fecha um arquivo |
| fflush | Força escrita de dados pendentes |
| setbuf | Muda o buffer interno usado no arquivo |
| setvbuf | Modifica buffer interno e/ou tipo de buferização e/ou tamanho do buffer |
| ftell | Retorna a posição atual do arquivo |
| fseek | Modifica a posição do arquivo |
| rewind | Volta o arquivo para a posição 0 e remove status de erro |
| fgetpos | Retorna posição do arquivo + estado de decodificação |
| fsetpos | Restaura uma posição de arquivo obtida com fgetpos |
| fwide | Define a largura de caracteres do arquivo |
| clearerr | Limpa os últimos erros do arquivo |
| feof | Checa se o arquivo acabou |
| ferror | Checa se ocorreu um erro no arquivo |
| remove | Apaga um arquivo |
| rename | Renomeia um arquivo |
| tmpfile | Abre um arquivo temporário no modo wb+ |
| tmpnam | Gera um nome único que pode ser utilizado para criar um arquivo |
A função remove tem um comportamento inconsistente entre o sistema operacional Windows e sistemas POSIX, no Windows a função pode excluir apenas arquivos, sendo necessário utilizar RemoveDirectoryW para apagar pastas no Windows.
A função rename pode ser utilizada para renomear ou mover arquivos, em sistemas POSIX o comportamento padrão é que a função pode sobrescrever arquivos existentes enquanto no Windows a função falha quando isso ocorre, é possível obter um comportamento mais consistente utilizando renameat2 no Linux e MoveFileExW no Windows onde a opção de sobrescrever ou não arquivos é controlada por flags.
Modo e permissões
Ao abrir um arquivo utilizando a função fopen, podemos definir os modos e permissões utlizando o segundo parâmetro que é uma string.
| String | Descrição | Se existente | Se não existe |
|---|---|---|---|
| r | Abre arquivo para leitura | Lê do inicio | Falha ao abrir |
| w | Cria arquivo para escrita | Destroi conteúdo | Cria novo |
| a | Abre arquivo para adição | Escreve no fim | Cria novo |
| r+ | Abre arquivo para leitura/escrita | Lê do inicio | Erro |
| w+ | Cria arquivo para leitura/escrita | Destroi conteúdo | Cria novo |
| a+ | Abre arquivo para leitura/escrita | Escreve no fim | Cria novo |
Um arquivo aberto para “adição” tem todas as suas escritas efetuadas na última posição de arquivo, isto é, não é possível modificar o conteúdo antigo do arquivo, mas podemos adicionar mais dados a ele.
Os seguintes modificadores podem ser utilizados em conjunto com as strings da tabela acima:
b: Não tem efeito nos sistemas POSIX, mas no Windows define o arquivo como modo bináriox: Adicionado noC11, só pode ser usado junto dewouw+(wxouwx+), faz com que a função falhe se o arquivo já existe.
Quanto a diferença de modo texto e modo binário, em sistemas POSIX como MacOs e Linux, não há diferença, mas no Windows, como o padrão utilizado como terminador de linha é \r\n enquanto que o padrão definido pela linguagem C é apenas \n, o sistema realiza conversões automáticas de \r\n para \n durante a leitura, e de \n para \r\n durante a escrita.
Essa conversão automática pode causar efeitos catastróficos ao lidar com arquivos binários (corrompendo arquivos, lendo dados de forma incorreta), portanto o modo que a desabilita é chamado de “modo binário” e um FILE* sem b no Windows é normalmente descrito como operando em “modo texto”.
Largura de caracteres
A largura de caracteres é inicialmente não definida, permitindo uso das funções wide e normais, quando definimos a largura de caracteres, estamos limitando o arquivo a operar com somente um dos dois conjuntos de funções.
A configuração “wide” também força todas as leituras a converterem a entrada de caracteres de múltiplos bytes para wchar_t e a saída de wchar_t para o formato de múltiplos bytes.
A tabela a seguir demonstra as funções de leitura e escrita vinculadas a largura de caracteres :
| Normal | Wide | Descrição |
|---|---|---|
| fgetc | fgetwc | Lê um caractere |
| fgets | fgetws | Lê uma string |
| fputc | fputwc | Escreve um caractere |
| fputs | fputws | Escreve uma string |
| getchar | getwchar | Lê um caractere da stdin |
| gets | Nenhuma | Lê uma string da stdin |
| putchar | putwchar | Escreve um caractere na stdout |
| puts | Nenhuma | Escreve uma string na stdout + '\n' |
| ungetc | ungetwc | Coloca um caractere de volta no fluxo de arquivo |
Lembrando que a função gets é tão problemática que é literalmente impossível utilizá-la de forma segura, portanto no C11 ela foi removida da linguagem, aconselha-se utilizar fgets no seu lugar.
Toda função que atua com stdin ou stdout pode também ser substituida por sua versão que atua com um FILE* genérico, pois stdin,stdout e stderr são macros que resultam em um FILE*.
Bufferização
As operações realizadas no FILE* também são bufferizadas, isto é, ao ler ou escrever no arquivo, os dados são inicialmente guardadas em um buffer, um array alocado dinâmicamente ao abrir o arquivo, e posteriormente são repassadas a função nativa do sistema operacional que realmente realiza a operação.
Essa bufferização ocorre pois escrever ou ler um número pequeno de bytes múltiplas vezes é ineficiente, leituras e escritas com tamanhos maiores como 64KB ou 128KB por vez são geralmente mais eficientes em hardware moderno.
Dessa forma, cada vez que escrevemos em um arquivo bufferizado, os dados escritos são na verdade copiados ao buffer de escrita e quando este buffer chega no tamanho ideal para uma escrita eficiente, ele é efetivamente escrito utilizando a função nativa do sistema para tal.
Da mesma forma, cada vez que realizamos uma leitura de qualquer valor num arquivo bufferizado, os dados são copiados do buffer de leitura para o ponteiro do usuário, caso não haja mais dados remanescentes, uma leitura com o tamanho ideal para eficiência é realizada e os bytes lidos podem ser utilizados nas leituras seguintes.
Lembrando que é comum que o tamanho do buffer definido pela biblioteca padrão não seja ajustado para maximizar a performance, nestes casos, isso pode ser resolvido com uma chamada para a função setvbuf onde é possível definir manualmente o tamanho do buffer, o tipo de buferização e/ou opcionalmente fornecer um buffer do usuário que será usado no lugar do buffer interno.
Existem 3 tipos de buferrização que podem ser definidos com setvbuf:
- Sem bufferização: Não há bufferização, toda chamada de
fread/fwritee afins resulta diretamente em uma chamada do sistema. - Bufferização de linha: Ao escrever, quando o caractere
\né encontrado, a saída é escrita imediatamente, é comum que a saída padrãostdouttenha esse tipo de bufferização. - Bufferização completa: Os dados só são escritos quando o buffer interno está cheio,
fflushé chamado oufcloseé chamado.
Também é comum que muitos sistemas operacionais realizem a bufferização de escritas antes de repassá-las ao dispositivo de armazenamento, pois escrever na memória RAM é geralmente muito mais rápido. Uma escrita que já foi enviada ao sistema operacional geralmente já permite que outros programas possam ler o valor atualizado, mas não significa que os dados realmente foram gravados no dispositivo de armazenamento.
A bufferização de escritas pelo sistema operacional é o principal motivo pelo qual “desligar o PC da tomada” não é aconselhável, justamente pelo fato de que arquivos podem ser corrompidos durante o processo.
Esse comportamento abre portas para um possível problema: perder arquivos que visivelmente eram acessíveis, mas que na verdade nunca foram salvos no disco efetivamente.
A imagem abaixo demonstra de forma visual a bufferização e o papel do sistema operacional:
A função fflush pode ser utilizada para forçar uma escrita de todos dados pendentes no buffer, lembrando que ela força a escrita para o sistema operacional, para forçar o sistema operacional a realizar a escrita para o dispositivo de armazenamento, processo normalmente chamado de sincronização, é necessário utilizar funções como FlushFileBuffers do Windows ou fsync do POSIX (Linux,macOs,etc).
Para realizar a sincronização de todos arquivos em um disco, utilizamos a função syncfs nos sistemas UNIX e a própria FlushFileBuffers passando um arquivo de dispositivo de um disco/SSD aberto como parâmetro (sendo necessário permissão de administrador para abrir um disco como arquivo no Windows).
Também é comum que iniciantes erroneamente usem fflush para limpar a entrada ao realizar leituras pelo terminal, apesar de funcionar em alguns sistemas, isso está fora da especificação oficial do C, que cita que o fflush funciona apenas para arquivos abertos para escrita.
Segurança em Threads
Desde o C11, para que o FILE* possa ser utilizado de forma segura em múltiplos threads, as funções que operam com o FILE* incluem “travas” que bloqueiam que outros threads operem com o FILE* até que a operação finalize.
O uso de travas para segurança em múltiplos threads diminui a performance, mas mantêm um comportamento consistente e seguro quando mais de um thread utiliza o mesmo arquivo.
Seguindo o padrão do C, não existe nenhuma função “padronizada” que possa evitar as travas para melhorar a performance, porém, várias implementações da biblioteca padrão que fornecem funções que realizam essas tarefas como extensão, o que acontece nos sistemas POSIX e no Windows.
Na biblioteca padrão do C do Windows, foram introduzidas funções com o prefixo _ e sufixo _nolock, logo para função fread existe a _fread_nolock, lembrando que essas funções só estão disponíveis no UCRT no Windows.
Para sistemas POSIX, temos as funções com sufixo _unlocked, logo para função fread, existe a fread_unlocked, inclusive existem as funções flockfile, ftrylockfile e funlockfile que permitem que a trava seja acionada/desacionada manualmente pelo usuário, permitindo que múltiplas funções _unlocked sejam chamadas de forma segura para mais de um thread sem o custo de acionar e desacionar a trava a cada chamada.
Na documentação da Microsoft há uma menção indicando que utilizar _configthreadlocale para que a localidade do thread seja desvinculada do localidade global evita travas que são utilizadas para acessar informações de locale (como ocorre com funções da familia printf e scanf), agilizando o desempenho, ao desvincular a localidade, podemos usar a própria setlocale para configuração.
Já em sistemas POSIX, é normal que exista a função uselocale que permite definir uma localidade separada da global definida com setlocale, a localidade deve ser definida utilizando a função newlocale ou duplocale, mas não há nenhuma menção de que a biblioteca padrão use ou possa usar travas para ler os dados da localidade atual.
Podemos utilizar a biblioteca feita pelo autor deste guia para uso portável das funções sem trava utilizando o sufixo _unlocked: stdio_unlocked.h.
Leitura de dados formatados
A familia de funções scanf apresenta várias variantes como fscanf, sscanf, vscanf, vfscanf, vsscanf, wscanf, fwscanf, swscanf, vwscanf, vfwscanf, e vswscanf.
Os prefixos antes da palavra scanf nas funções indicam:
f: Indica que a função lê de umFILE*, quando o prefixo não está presente, significa que ela utiliza astdin(Entrada padrão)s: Indica que a função lê de uma string na memória ao invés de umFILE*w: Indica que a função lê uma entrada no formatowchar_tao invés decharv: Indica que a função aceita umva_list
Todas as funções aceitam um parâmetro de formato e um número variáveis de argumentos ou va_list com os endereços dos parâmetros que serão preenchidos pela função, a ideia das funções de scan é extrair dados de uma string ou arquivo de texto num formato qualquer.
Os dados só são extraidos se o padrão colocado no formato bate com o padrão no texto lido/fornecido, de forma que as funções de scan funcionem como um Regex mais primitivo. Se algum caractere/formato não bater, a função falha imediatamente e mantêm o que não foi consumido como pendente no buffer de leitura (caso esteja lendo de um arquivo).
Na string de formato, ao adicionar um único caractere que é determinado como “espaço em branco” pela função isspace, todos os caracteres que são “espaço em branco” são pulados até que seja encontrado um caractere que não é um “espaço em branco”, a lista de caracteres que se encaixam nessa categoria são :
- Espaço (
- Form feed (
\f, 0x0C) - Line feed (
\n, 0x0A) - Carriage return (
\r, 0x0D) - Tab horizontal (
\t, 0x09) - Tab vertical (
\v, 0x0B)
Todo especificador de formato é composto, na seguinte ordem, por:
- Caractere
%inicial (Opcional)o caractere*que suprime a atribuição, de forma que o especificador seja utilizado apenas para “pular” o padrão especificado(Opcional)um número inteiro maior que 0, chamado de especificador de tamanho, que especifica o número de caracteres máximo que serão lidos, lembrando que%se%[podem facilmente levar a um overflow de buffer sem este argumento.(Opcional)modificador de tamanho para o tipo, que indica o tipo de destino usado na conversão.- O especificador do formato de conversão
Os modificadores de tamanho de tipo aceitos são :
- Para strings e caracteres:
nenhum=char*l=wchar_t*
- Para inteiros:
hh=unsigned char*ousigned char*h=unsigned short*oushort*nenhum=unsigned int*ouint*l=unsigned long*oulong*ll=unsigned long long*oulong long*j=uintmax_t*ouintmax_t*z=size_t*t=ptrdiff_t*wN= OndeNé o número de bits, aceitauintN_t*,intN_t*ou_BitInt(N)(C23)
- Para ponto flutuante:
nenhum=float*l=doubleL=long doubleH=_Decimal32(C23)D=_Decimal64(C23)DD=_Decimal128(C23)
Os especificadores de formato de conversão existentes são :
%: Consome um%c: Consome e atribuiNcaracteres, ondeNé o número do especificador de tamanho ou 1 caso ele não seja informado, lembrando que esse especificador não atribui um\0, pode consumir e atribuir “espaço em branco”s: Consome e atribui uma string, parando quando um caractere de “espaço em branco” é encontrado ou a quantidade de caracteres consumidos excederia o número do especificador de tamanho (caso ele seja informado), adiciona um\0no final, de forma que o buffer fornecido precise ter ao menosN+1ondeNé o especificador de tamanho.[set]: Consome e atribui o conjunto de caracteres presentes emset, se o primeiro caractere presente nosetfor^então consome e atribui todos caracteres NÃO PRESENTES noset. Assim como no especificadorsadiciona um\0no final, algumas implementações também permitem que uma faixa seja informada, utilizandoA-Zpor exemplo para todos caracteres do valor ASCII deAatéZ.d: Consome e atribui um inteiro decimal, de forma similar astrtolcom10no parâmetrobase.i: Consome e atribui um inteiro qualquer, onde o formato é deduzido pela entrada ao ler, de forma similar astrtolcom0no parâmetrobase.u: Consome e atribui um inteiro sem sinal decimal, similar astrtoulcom10no parâmetrobase.o: Consome e atribui um inteiro octal sem sinal, similar astrtoulcom8no parâmetrobase.xouX: Consome e atribui um inteiro hexadecimal sem sinal, similar astrtoulcom 16 no parâmetrobase.n: Atribui o número de caracteres lidos até agora, nenhuma entrada é consumida.a,e,foug: Consome e atribui um ponto flutuante com sinal, a entrada também pode ser infinito ou NAN, o formato é o mesmo aceito pela funçãostrtof.p: Consome e atribui uma sequência definida pela implementação, que identifica um ponteiro, o argumento atribuido deve ser do tipovoid**.
Todos os especificadores de formato, exceto [set], c e n, consomem todos os caracteres de “espaço em branco” antes de ler a entrada e realizar o consumo e atribuição do respectivo especificador de formato.
Todas funções da familia scanf, retornam o número de conversões bem sucedidas, sendo possível detectar se a função falhou ou não ao compararmos o número de conversões esperadas com o número recebido, além disso a função pode retornar EOF caso ocorra um erro ao ler do arquivo antes de uma conversão ocorrer com sucesso.
O código abaixo demonstra alguns exemplos utilizando sscanf para extrair dados de strings:
//1. Obter nome, idade e formação
char nome[65];
int idade;
char formacao[65];
sscanf("Meu nome é Agatha, tenho 25 anos e sou formada em Psicologia",
"Meu nome é %64s, tenho %d anos e sou formada em %64s",
nome, &idade, formacao);
//2. Obter o nome de um arquivo executável
char executavel[256];
sscanf("MeuPrograma.exe", "%255[^.].exe", executavel);
As funções da familia scanf são úteis nos casos onde temos garantias quanto a forma como os dados são organizados para que sejam extraidos de forma simples, nesses casos a função permite a extração de dados de padrões mais complexos com relativamente pouco código.
Porém casos como leitura de dados de usuário onde a ordenação ou formato dos dados não necessariamente segue um padrão ou está sempre correta, as funções de scan podem não ser ideais, nesses casos as funções que lêem de strings como sscanf ainda podem ser úteis, porém, utilizar diretamente funções como strtol, strtod e similares pode, muitas vezes, ser mais eficiente e permitir um tratamento de erros melhor.
Muitos iniciantes também tem problemas ao utilizar scanf diretamente para ler entrada do usuário, pois a função pode não consumir todos os bytes pendentes ao ler da entrada padrão, possívelmente afetando leituras futuras, utilizar getchar em loop para processar os dados ou fgets seguido de strtol/strtod ou até mesmo sscanf é, no geral, uma alternativa melhor.
Escrita de dados formatados
As funções da familia printf funcionam de forma similar a familia scanf, porém para escrita de dados formatados.
A maioria dos prefixos são reutilizados, porém com algumas diferenças:
- A ausência do prefixo
findica uma escrita nastdout(Saída padrão). - O prefixo
sindica que os dados serão escritos no buffer fornecido, ao invés de lidos dele. - Adição do prefixo
n, que indica que a função aceita um parâmetro especificando o tamanho do buffer (sempre em conjunto com o prefixos).
Na familia printf, todo especificador de formato é composto, na seguinte ordem, por:
- Caractere
%inicial - Zero ou mais flags que modificam o comportamento da conversão:
-: O resultado da conversão é justificado para esquerda (o padrão é justificado para direita)+: O sinal do valor é sempre adicionado (por padrão apenas quando o número é negativo colocamos um sinal de-)+)#: Uma forma alternativa de conversão é realizada, os detalhes exato dessa diferença serão especficados em seguida, caso o especificador de formato usado não tenha suporte para um formato alternativo o comportamento é indefinido.0: Para conversões de número inteiro e ponto flutuante, zeros são adicionados na frente no lugar de espaços(Opcional)Inteiro ou*que especifica o tamanho mínimo. O resultado tem um número de espaços adicionados igual ao número especificado (ou zeros, caso0tenha sido usado), ao utilizar*assume-se que há um argumento extra do tipointantes do argumento a ser convertido, com o número do tamanho mínimo.(Opcional).seguido de um número ou*que especifica a precisão da conversão, para inteiros isso significa a quantidade mínima de digitos, para ponto flutuante a quantidade de casas decimais e para strings o número máximo de caracteres escritos.(Opcional)Modificador de tamanho do tipo similar aos descritos nas funções da familiascanf.- O especificador do formato de conversão.
Os modificadores de tamanho de tipo aceitos são os mesmos utilizados pelas funções da familia scanf.
Os especificadores de formato de conversão existentes são :
%: Escreve%c: Escreve um caractere, o valor é promovido para o tipointmas convertido paraunsigned chardurante a escritas: Escreve uma string, ao utilizar o especificador%lsa string é convertida dewchar_tparacharantes de ser escritadoui: Escreve um inteiro decimal com sinal.u: Escreve um inteiro decimal sem sinal.o: Escreve um inteiro octal, no modo alternativo de escrita, adiciona0como prefixo (mesmo prefixo para escrever literais octais).xouX: Escreve um inteiro hexadecimal, com letras minúsculas casoxseja usado e maiúsculas casoXseja usado, no modo alternativo de escrita, adiciona0xcomo prefixo (mesmo prefixo para escrever literais hexadecimais).f: Escreve um ponto flutuante em notação decimal, a precisão padrão é 6 digitos, argumentos emfloatsão promovidos paradouble, logo%ftambém escreve umdouble, no modo alternativo de escrita, o ponto decimal é escrito mesmo se não houver nenhum digito após ele.eouE: Escreve um ponto flutuante em notação decimal com expoente (ex:5.24e5), utilizareouEcontrola se o caractere do expoente é minúsculo ou maiúsculo, segue o mesmo modo alternativo de escrita do formatof.aouA: Escreve um ponto flutuante em notação hexadecimal com expoente (ex:0x5.445p1), utilizaraouAcontrola se o caractere do expoente é minúsculo ou maiúsculo, segue o mesmo modo alternativo de escrita do formatof.gouG: Escreve um ponto flutuante escolhendo o formato conforme o expoente, se considerando a precisãoPe o expoenteX, temos queP > X >= -4então o formatofé utilizado, caso contrário o formatoeé utilizado.n: Escreve no ponteiro informado o número de caracteres escritos até então.p: Escreve uma string que define um ponteiro qualquer (void*) de um modo/formato definido pela implementação.
Exemplo de uso da função printf:
int n1 = 50;
double n2 = 1.586;
double n3 = 5245.0;
printf("%d\n", n1); //Escreve "50\n"
printf("%.2f\n", n2); //Escreve "1.59\n"
printf("%.3e\n", n3); //Escreve "5.245e+03\n"
Normalmente, as funções retornam o número de caracteres escritos ou um número negativo caso algum erro ocorra durante a escrita ou conversão de valores.
Nas funções que aceitam o prefixo n como snprintf, o valor retornado é o tamanho que a saída teria se toda ela pudesse ser escrita e não a quantidade que realmente foi escrita, dessa forma, também podemos utilizar NULL no buffer e 0 no tamanho para descobrir quantos caracteres são necessários para guardar o resultado.
O comportamento da snprintf mencionado acima também já foi fonte de bugs no kernel do Linux, onde decidiram mudar a função snprintf para uma nomeada scnprintf onde a quantidade de bytes retornados é a que realmente foi escrita e não a quantidade “que seria escrita se o buffer tivesse espaço suficiente”, essa função não é padrão do C, apesar de estar presente em sistemas POSIX, mas é muito fácil de implementá-la.
A função scnprintf também é útil para concatenar vários valores formatados numa string, o exemplo abaixo implementa a scnprintf usando a snprintf para concatenar valores e montar uma requisição HTTP:
#include <stdlib.h>
#include <stdio.h>
#include <stdarg.h>
#define STR_AND_SIZE(X) X,sizeof(X)-1
size_t memcat(void *dst, const void *src, size_t size)
{
memcpy(dst, src, size);
return size;
}
int scnprintf(char *restrict buffer, size_t bufsz, const char *restrict format, ...)
{
va_list list;
size_t needsz;
va_start(list, format);
needsz = vsnprintf(buffer, bufsz, format, list);
va_end(list);
return (needsz <= bufsz) ? needsz : bufsz;
}
void enviaValores(SOCKET sock, struct Dados *dados)
{
char buffer[8192]; //Buffer é grande o suficiente para não termos problemas
char *bufpos = buffer; //Vai escrevendo e avançando pelo buffer
bufpos += memcat(bufpos, STR_AND_SIZE(
"POST /Registrar HTTP/1.1\r\n"
"Content-Type: application/x-www-form-urlencoded\r\n"
"\r\n"));
bufpos += scnprintf(bufpos, sizeof(buffer) - (size_t)(bufpos - buffer),
"Nome=%512s&cidade=%512s&idade=%d",
dados->nome, dados->cidade, dados->idade);
send(sock, buffer, (int)(size_t)(bufpos - buffer), 0);
}
Pastas
Não existe nenhuma forma “portável” em C de criar, apagar ou iterar sobre pastas, no C++ isso foi introduzido a linguagem no C++17 com a biblioteca filesystem.
É importante evidenciar que não há necessidade de checar se uma pasta já existe antes de criá-la ou excluí-la, fazer essa pre-checagem na verdade é menos eficiente pois envolve uma chamada de sistema adicional e podemos obter a mesma informação ao ler o código de erro resultante das respectivas funções nativas (evidenciando o motivo pelo qual a pasta não foi criada/excluida).
Lembrando que em todos sistemas operacionais, toda pasta tem uma subpasta chamada ., que indica a pasta atual e uma subpasta chamada .. que indica a pasta anterior.
Nos sistemas POSIX, podemos utilizar a função mkdir para criar pastas e rmdir para excluir pastas, lembrando que rmdir só funciona em pastas vazias, sendo necessário excluir TODOS os arquivos e subpastas dentro de uma pasta, antes de realmente excluí-la.
Para listar o conteúdo de pastas, podemos utilizar a função opendir, que retorna um DIR* funcionando de forma similar ao `FILE*, um ponteiro para um fluxo de dados opaco com bufferização que pode ser operado utilizando outras funções, retornando um ponteiro nulo caso a função tenha falhado.
Utilizando o DIR*, podemos utilizar a função readdir para realizar a leitura do próximo item da pasta, que retorna um ponteiro para struct dirent, que detalha os dados do item encontrado (que pode ser um arquivo ou subpatas) ou um ponteiro nulo, indicando que todos os itens da pasta já foram lidos.
Após terminar de listar os arquivos, podemos chamar a função closedir, lembrando que é importante certificar-se que opendir tenha retornado um DIR* válido e não um ponteiro nulo.
No exemplo abaixo, temos a demonstração de uma função que lista o conteúdo de uma pasta:
#include <stdio.h>
#include <sys/types.h>
#include <dirent.h>
void listarPasta(const char *caminho)
{
DIR *dir = opendir(caminho);
if(dir == NULL)
return;
struct dirent *dados;
while((dados = readdir(dir))) {
puts(dados.d_name);
}
closedir(dir);
}
Link Simbólico
Uma funcionalidade presente na maioria dos sistemas de arquivo modernos é a possibilidade de criar “links simbólicos” ou no inglês “symbolic link”, um link simbólico é um arquivo que atua como “ponteiro” para o nome de outro arquivo ou pasta a nível do sistema de arquivos, e diferente dos “atalhos do Windows” que são outra coisa, são identificados na maioria dos casos como se fossem o arquivo original.
Como o link simbólico é apenas um ponteiro, excluir o link simbólico não apaga o arquivo original, mas modificar um arquivo através do seu link simbólico modifica o arquivo ou pasta original.
Links simbólicos podem ser relativos (referenciar uma pasta ou nome relativo ao caminho do link simbólico) ou absolutos e são uma possível forma de referenciar arquivos e pastas que podem estar em outro dispositivo de armazenamento como se estivessem na mesma pasta.
Um uso prático de links simbólicos seria diminuir o uso de espaço em disco de aplicações que usam Electron, uma framework para construir aplicações desktop usando um navegador embutido, que costumam incluir uma biblioteca dinâmica com tamanho próximo a 100MB com um navegador completo, compartilhar a mesma biblioteca com múltiplos programas pode diminuir o uso de espaço.
Lembrando que links simbólicos podem causar uma grande confusão ao iterar recursivamente sobre pastas, visto que é possível ter uma pasta que volte pra ela mesma, possibilitando uma recursão infinita, implementar um algoritmo robusto de iteração recursiva sobre pastas inclui ter um tratamento específico para isso ou detectar links simbólicos para pastas e evitá-los.
Para criar um link simbólico, podemos utilizar a função symlink em sistemas POSIX e CreateSymbolicLinkW no Windows, lembrando que no Windows é necessário ter permissão de administrador ou o usuário deve ser marcado como desenvolvedor para utilizar a função, a motivação da Microsoft é que links simbólicos podem ser utilizados para explorar vulnerabilidades em aplicações que não lidam corretamente com links simbólicos.
Para ler o caminho para qual um link simbólico aponta, podemos utilizar a função readlink em sistemas POSIX
e no Windows, precisamos primeiro abrir o arquivo com CreateFileW utilizando a flag FILE_FLAG_OPEN_REPARSE_POINT e posteriormente utilizar DeviceIoControl
com a flag FSCTL_GET_REPARSE_POINT.
Para checar se um arquivo é um link simbólico ou não, podemos utilizar a função lstat em sistemas POSIX e GetFileAttributesW checando se o arquivo tem a flag FILE_ATTRIBUTE_REPARSE_POINT ou simplesmente utilizando os dados retornados por readdir e FindNextFile ao listar o arquivo em uma pasta.
Link Físico
Um link físico, também chamado de “hard link”, é uma referencia a um arquivo dentro do sistema de arquivos, não é possível diferenciar entre o arquivo original e um link físico.
Quando criamos um arquivo, podemos dizer que o primeiro link físico a ele é criado, a partir daí, podemos criar mais links físicos, todos eles vão referenciar o mesmo arquivo mas com caminhos diferentes, e o arquivo só será realmente excluido quando todos os links físicos ao arquivo forem removidos, inclusive por esse motivo a função que “apaga” arquivos, é chamada de unlink no POSIX, justamente por que ela não está efetivamente excluindo o arquivo de vez mas removendo um dos links.
Inclusive no Linux e em vários outros sistemas POSIX, algo ainda mais inusitado acontece, mesmo quando todos os links físicos foram removidos do sistema de arquivos, se o arquivo ainda estiver aberto por algum programa, ele permanecerá existindo, invisível no sistema de arquivos, até que o programa finalize ou feche o arquivo.
A principal diferença entre um link simbólico e um link físico é que não existe um “conceito” de arquivo original no link físico, todos os links físicos tem a mesma importância, diferente do link simbólico onde apagar o arquivo original o inultiliza. Também não é possível fazer links físicos para pastas.
Para criar um novo link físico, utilizamos a função link em sistemas POSIX e CreateHardLinkW no Windows.
Tudo é um arquivo
Sobre os sistemas operacionais modernos, principalmente os baseados em UNIX, é comum ouvirmos a frase “Tudo é um arquivo”. Essa frase remete ao comportamento dos sistemas UNIX de expor coisas que normalmente não seriam arquivos, sob a mesma interface de arquivo, com um nome no sistema de arquivos.
O termo mais correto seria dizer que tudo é um “descritor de arquivo”, um número ou ponteiro que identifique unicamente uma porta de acesso a um recurso concedido pelo sistema operacional. A maioria deles apresentam uma interface similar a de um arquivo, permitindo leitura e/ou escrita.
Além das coisas expostas no sistema de arquivos, também existem funções que criam recursos que são descritores de arquivos como ocorre com a função socket.
A percepção de descritores de arquivos como portas de comunicação com o sistema fica evidente quando percebemos como a escrita e leitura de um arquivo pode necessitar de ações diferentes dependendo do sistema de arquivos e o protocolo de comunicação com o hardware (NVME, SATA, etc).
Como todo acesso a arquivos pode ser diferente, o comando de ler ou escrever num arquivo é na verdade uma comunicação com o driver para realizar um pedido de envio ou recebimento de dados.
Da mesma forma, muitos periféricos se encaixam nesse mesmo padrão, queremos abrir uma porta de comunicação com um driver, enviar dados, receber dados e realizar outras tarefas similares, expor seu comportamento como se eles fossem arquivos, simplifica a forma como lidamos com eles.
As funções normalmente suportadas para a maioria dos descritores de arquivo (NÃO TODOS), em sistemas UNIX:
read: Realiza a leitura de dados.write: Realiza o envio dos dados.lseek: Altera a posição de leitura/envio de dados.mmap: Mapeia em memória no processo uma parcela dos dados.poll: Espera até que o descritor esteja disponível para leitura/escrita ou um erro ocorra.ioctl: Serve como um coringa, para todas as operações que não se encaixam totalmente na interface padrão de arquivos, fornece uma flag de comando e parâmetros variádicos, na maioria dos casos é uma combinação deflag + ponteiro, onde o ponteiro acaba sendo umastructespecífica para o arquivo e comando que fornece dados adicionais que serão escritos e/ou lidos.
Essas 6 operações geralmente são suficientes para a maioria dos casos e elas são a base para a maioria da comunicação com o hardware utilizando APIs do kernel. Podemos listar por exemplo como essas operações são realizadas com diferentes descritores de arquivo no Linux:
- Processo:
pollsinaliza como “pronto para leitura” quando o processo é finalizado - Serial:
readlê dados,writeenvia dados,ioctlpode ser usado para mudar baud rate, paridade e stop bits - Tela:
readlê pixels da tela,writeescreve pixels,mmappode ser usado para mapear os dados da tela em memória permitindo uma leitura e escrita mais eficiente,ioctlpode ser usado para descobrir resolução, informações sobre a tela, modificar configuração. (/dev/fb*) - Gamepad:
readlê um evento de botões/analógicos,ioctlpode ser utilizado para vibrar o controle,pollpode ser utilizado para esperar por entrada do usuário - Gerador aleatório:
readgera novos bytes aleatórios criptograficamente seguros
Os arquivos que representam periféricos e dispositivos são encontrados na pasta /dev em sistemas UNIX. Também existe um outro caminho denominado /proc que pode ser utilizado para ler algumas informações internas do kernel expostas ao usuário e modificar algumas configurações.
O Windows, difere dos sistemas UNIX ao preferir utilizar APIs estruturadas no lugar da interface de arquivos, mas ele ainda aproveita parcialmente algumas das interfaces de arquivos em suas APIs. A preferência do Windows é substituir a nomenclatura de “arquivos” para “objetos do kernel” e preferir APIs específicas para operar com cada tipo de objeto, utilizando ainda as APIs de arquivo para dispositivos.
Caso tenha interesse, o programa Object Explorer permite explorar e visualizar todos os objetos do kernel do Windows e quais deles cada processo abriu.
Similar ao /dev do Linux, o Windows também apresenta algo similar com o caminho \Device, mas que só pode ser acessado se utilizarmos a API NtCreateFile pois as APIs de alto nível do Windows como a CreateFileW geralmente só podem acessar arquivos/dispositivos que estão ou tem um link simbólico no caminho \GLOBAL?? e por conta disso, não conseguimos acessar o \Device no explorador de arquivos ou terminal.
Há também uma grande diferença no comportamento das APIs relacionadas a “espera”, enquanto funções como poll do POSIX podem esperar por um arquivo “pronto para escrita” ou “pronto para leitura”, as funções do Windows como WaitForSingleObject, WaitForMultipleObject e outras, esperam até que um objeto esteja num estado “sinalizado”.
No windows, as funções de mapear arquivos em memória CreateFileMappingW e MapViewOfFile não funcionam com arquivos de dispositivos, porém temos equivalentes a outras funções com ReadFile (read), WriteFile (write), SetFilePointer (lseek), WaitForMultipleObjects (poll) e DeviceIoControl (ioctl).
Metadados padrão
Na maioria dos sistemas operacionais, os metadados normalmente encontrados são:
- Tamanho do arquivo
- Tempo de último acesso
- Tempo de última escrita
- Tempo de criação
Podemos obter essas informações utilizando funções como stat, fstat e lstat do POSIX ou GetFileAttributesExW e GetFileTimes/GetFileSize no Windows.
I/O não bloqueante
O termo I/O é uma abreviação de “Input/Output”, que no português seria “Entrada/Saída”, indicando operações que envolvem entrada e saída de dados, que no contexto de computação, indica uma comunicação com dispositivos periféricos.
Outro termo importante é o jargão “dormir” no contexto de processos/threads, dizemos que um processo ou thread “dorme” quando ele é colocado em espera e deixa de executar, para que outros processos possam ser executados, em alguns casos, o processo ou thread pode estar ocupado esperando que o kernel termine de executar alguma ação, extendendo o periódo da “soneca”, nesse caso, dizemos que o thread/processo é “acordado” quando o kernel finaliza a tarefa e volta a executar o processo ou thread em espera.
Dizemos que uma função é “bloqueante” quando ela pode fazer com que nosso processo ou thread durma e só acorde quando a operação estiver finalizada.
Um arquivo ou dispositivo de I/O aberto no modo não bloqueante geralmente tem o seguinte comportamento:
- Quando o usuário realiza uma escrita
- Se os buffers internos do kernel tem espaço, seus dados são copiados para ele, para que esses dados posteriormente sejam enviados para o arquivo/dispositivo de I/O
- Se os buffers do kernel estão cheios, a função falha, indicando que você deve tentar novamente mais tarde, isso acontece pois ele precisa primeiro repassar os dados pendentes para escrita para liberar espaço suficiente no seu buffer interno, para que possa aceitar os seus dados
- Quando o usuário realiza uma leitura
- Se o kernel já leu os dados que você precisa, seja por um pedido anterior que falhou ou por uma pre-leitura realizada de forma antecipada, ele copia os dados do buffer dele para o seu
- Se o kernel não tem os dados que você quer ler já no buffer dele e precisa realizar uma operação lenta como leitura do disco/rede, a função falha, indicando que você deve tentar novamente mais tarde, essa chamada, mesmo falhando, também indica para o kernel que ele deve ler e preparar antecipadamente mais dados.
Na prática, o modo não bloqueante é muito similar ao uso síncrono, a diferença é que toda situação que faria com que o processo ou thread dormisse, acaba causando uma falha na função, que simplesmente indica “tente novamente mais tarde”, para saber o momento exato que podemos tentar novamente, podemos utilizar funções como poll em sistemas UNIX ou as variações mais eficientes como epoll no Linux ou kqueue no macOs e freeBSD.
Nos sistemas UNIX, é normalmente necessário utilizar a flag O_NONBLOCK nas funções open e socket (em alguns sistemas é necessário utilizar a função fcntl para definir um soquete como não bloqueante) para definir um arquivo ou dispositivo de I/O como não bloqueante.
No Windows é normal a preferência por I/O assíncrono no lugar de I/O não bloqueante, com apenas os soquetes, utilizados para comunicação via rede, suportando I/O não bloqueante, para utilizar I/O não bloqueante no Windows, podemos utilizar a função ioctlsocket com a flag FIONBIO para ativar o modo não bloqueante e posteriormente a função WSAPoll que funciona de forma similar a função poll do POSIX.
Vantagens de utilizar I/O não bloqueante:
- A implementação de I/O não bloqueante é mais simples
- A aplicação tem controle total sobre seus próprios buffers, facilitando a reutilização de buffers e reduzindo uso de memória
Desvantagens de utilizar I/O não bloqueante:
- Requer mais chamadas de sistema comparado ao uso de I/O assíncrono
- Envolve cópias entre os buffers do kernel e usuário
- É necessário gerenciar buffers de escrita pendentes e leituras parciais, que são impeditivos para reutilização de buffers
I/O assíncrono
Diferente do I/O síncrono, onde executamos um comando e recebemos sua resposta imediatamente, no I/O assíncrono, iniciamos um comando que só será terminado mais tarde, necessitando de algum mecanismo que reporte os resultados da operação.
No caso do I/O assíncrono, uma sequência simples de etapas é realizada:
- Iniciamos um comando de leitura ou escrita de dados, informando o buffer e a quantidade de bytes a serem lidos/escritos.
- O kernel “sequestra” nosso buffer (devemos manter o buffer válido e não modificá-lo até o fim da operação) e executa a operação em paralelo.
- Após a conclusão da operação, o kernel nos avisa de alguma maneira sobre o resultado.
A vantagem do I/O assíncrono, é que como o kernel tem a permissão de “sequestrar” nosso buffer, ele pode realizar leituras ou escritas diretamente usando nosso buffer, evitando a cópia dos dados para um buffer próprio do kernel.
Outra vantagem do I/O assíncrono é que escritas e leituras grandes podem ser realizadas com menos chamadas de sistema e trocas de contexto, uma escrita que precisaria ser feita em 10 etapas no modo não bloqueante, poderia ser realizada com uma única operação usando I/O assíncrono.
Um fato que gera confusão sobre I/O assíncrono, nos casos onde não sabemos quando podem haver dados disponíveis (como leituras da rede, USB, serial, bluetooth, teclado), é necessário preparar um buffer antecipadamente e iniciar uma leitura assincrona, que só será concluída quando dados entrarem, ocorrer um erro ou timeout (passar muito tempo sem receber nada).
Esse fato inclusive é uma das grandes desvantagens do I/O assíncrono, se, por exemplo, houver múltiplos dispositivos conectados em um servidor, mas que raramente enviam algo, no modelo de I/O assíncrono seriamos obrigados a reservar um buffer e iniciar uma leitura assincrona para cada um dos dispositivos, enquanto no modo não bloqueante poderiamos esperar por uma resposta de qualquer dispositivo, ler em um buffer temporário e processar diretamente a entrada, reduzindo o uso de memória.
O mecanismo exato utilizado para reportar os resultados pode ser diferente para cada sistema operacional, geralmente realizada por um callback chamado pelo kernel ou pela espera por um evento de conclusão.
Uma nova implementação eficiente de I/O assíncrono é o io_uring do Linux, que inclui uma fila de requisições e outra de respostas que são compartilhadas entre o kernel e o programa do usuário, onde o usuário pode preencher uma lista com várias requisições, solicitar todas elas de uma vez e esperar pela resposta com uma única chamada, diminuindo a quantidade de chamadas de sistema necessárias. O único outro sistema a implementar um mecanismo similar, foi o Windows 11 com o IoRing, que ainda está em suas implementações iniciais e é mais limitado em relação ao equivalente de Linux.
Permissões de arquivos
Nos sistemas UNIX, a permissão de arquivos básica funciona de forma bastante simples, cada arquivo tem um dono e pertence a um grupo, contendo as permissões para o dono do arquivo, grupo e outros (que não pertencem ao grupo e nem são donos do arquivo) em separado.
As permissões de arquivos normalmente são representadas por números no sistema númerico octal seguindo o formato DGO (Dono, Grupo, Outros), lembrando que números em octal são representados com um 0 na frente na linguagem C.
Os bits que representam cada permissão são :
1: Permissão de execução2: Permissão de escrita4: Permissão de leitura
Alguns exemplos:
0777apresenta todas as permissões para todos0766todas permissões ao dono, grupo e outros não podem executar0555não permite escritas no arquivo por ninguém
Ainda existem 3 bits extras que podem ser definidos:
01000 (S_ISVTX): Se uma pasta contêm este bit, impede que arquivos na pasta sejam apagados se o usuário não for dono do arquivo nem da pasta02000 (S_ISGID): Define que o arquivo, quando executado, define o grupo atual do processo como o grupo deste arquivo04000 (S_ISUID): Define que o arquivo, quando executado, define o usuário atual do processo como o usuário dono deste arquivo
O comando sudo nos sistemas UNIX permite que usuários executem processos com permissões de super usuário (root), funciona utilizando o bit S_ISUID em um arquivo cujo dono é o próprio root mas que pode ser executado por qualquer usuário, realizando uma validação de senha antes de efetivamente executar o comando solicitado.
As permissões de arquivo podem ser especificadas ao criar o arquivo com a função open e modificadas diretamente com a função chmod (que também é o nome da ferramenta de terminal que executa a mesma tarefa).
Esse sistema de permissões simplificado permite que usuários e programas tenham um controle mais acessível das permissões.
Caso seja necessário permissões mais complexas, podemos utilizar o que chamamos de ACL (Access Control lists), que no português seria “Listas de controle de acesso”, utilizando os comandos setfacl e getfacl.
Os ACLs são listas que definem várias regras individuais, que podem permitir e/ou negar o acesso de vários grupos e usuários específicos, permitindo um controle muito mais preciso.
O Windows, por exemplo, só apresenta ACLs e não tem um sistema de permissões mais simples, de forma que a maioria dos programas e usuários preferem que os arquivos “herdem” o ACL “padrão”, justamente para evitar lidar com a complexidade que permeia os ACLs.
Mapear arquivos em memória
Em vários sistemas operacionais, podemos mapear arquivos na memória virtual do processo, utilizando chamadas de sistema.
Quando mapeamos arquivos em memória, passamos algumas informações:
- Tamanho da região mapeada
- Offset da região mapeada (bytes até o início)
- Permissões (leitura, escrita, execução)
Com essas informações, o sistema introduz novas páginas de memória no nosso processo e se responsabiliza por preenchê-las com os dados do arquivo. O sistema operacional assume a responsabilidade de gerenciar a memória, iniciar leituras/escritas em disco, etc.
Dessa forma, podemos acessar os dados do arquivo, como se ele fosse um simples array de bytes na memória. Todas escritas nessa região são eventualmente repassadas ao arquivo original e todas as leituras são realizadas conforme os dados atuais do arquivo.
Quando realizamos uma leitura em uma página de memória virtual que ainda não foi lida do arquivo, ocorre uma falha de página e o sistema operacional suspende o processo até que a leitura seja finalizada.
Vantagens de mapear em memória:
- Podemos evitar cópias dos buffers internos do kernel para nossos buffers, pois o buffer consegue mapear seus buffers internos diretamente
- Múltiplos processos podem compartilhar a mesma memória ao mapear o mesmo arquivo (diminuindo o tempo de carga e uso de memória do sistema)
- Podemos evitar chamadas de sistema adicionais ao ler/escrever no arquivo
- Arquivos que são acessados, em pedaços, conforme ação do usuário, podem deixar o kernel se responsabilizar em carregar apenas o que realmente é usado
Desvantagens de mapear em memória:
- O processo de falha de página complica análises de performance, uma simples leitura de uma variável pode encadear uma falha de página que pode bloquear o processo
- Caso um sistema de arquivos na nuvem seja utilizado, simples leituras em variáveis mapeadas em memória podem causar erros como
SIGBUSem sistemas POSIX caso a conexão esteja instável, lidar com esse tipo de erro é muito mais complexo de tratar do que erros em chamadas de sistema - A sincronização com o sistema de arquivos pode ocorrer em segundo plano a qualquer momento, dificultando a detecção de problemas com a mesma
- O gerenciamento automático do kernel pode ser inadequado para padrões de acesso fora do comum, em alguns sistemas podemos dar dicas quanto a alguns padrões com funções como
madvise, mas que também não servem para padrões mais complexos.
Este vídeo, ajuda a esclarecer os problemas encontrados ao tentar usar arquivos mapeados em memória em aplicações de banco de dados, justamente explicando os motivos pelo qual mapear arquivos em memória é uma péssima escolha para implementar um banco de dados.
Para mapear arquivos em memória, utilizamos a função mmap em sistemas POSIX como Linux e MacOs, enquanto no Windows é necessário utilizar a função CreateFileMappingW e depois MapViewOfFile.
Apêndice
Neste apêndice estão os assuntos extras relacionados a programação que são considerados importantes para um entendimento mais completo dos assuntos descritos neste guia.
Números Binários
Toda informação num computador é composta por bits, a palavra bit é na verdade uma sigla para o termo em inglês BInary DigiT, que em português seria “digito binário”.
Binário vem do número dois, “bi”, indicando uma existência de apenas dois algarismos diferentes 0 e 1.
É importante lembrar que é comum utilizarmos os prefixos conforme listado no capítulo sobre literais para diferenciar os sistemas númericos :
0bpara binário0para octal- Nenhum para decimal
0xpara hexadecimal
O sistema binário compartilha algumas características em comum com os sistemas númerico octal, decimal e hexadecimal:
- Existe um número limitado de símbolos usados para representar um algarismo
- Ao incrementar o valor de um algarismo, quando não houver símbolos para representá-lo como um algarismo de valor maior, podemos voltar aquele algarismo para
0e incrementar o algarismo a esquerda (ou adicionar um algarismo1caso não haja algarismo a esquerda) - O símbolo
0é usado para indicar um algarismo de valor nulo
Quanto a declaração 1. é fácil de percebê-la ao analisarmos os algarismos presentes nos diferentes sistemas:
- Binário :
0e1 - Octal:
0,1,2,3,4,5,6,7 - Decimal:
0,1,2,3,4,5,6,7,8,9 - Hexadecimal:
0,1,2,3,4,5,6,7,8,9,A,B,C,D,E,F
Já quanto a declaração 2., podemos ver por exemplo ao analisar a tabela abaixo:
| Decimal | Binário | Octal | Hexadecimal |
|---|---|---|---|
| 0 | 0 | 0 | 0 |
| 1 | 1 | 1 | 1 |
| 2 | 10 | 2 | 2 |
| 3 | 11 | 3 | 3 |
| 4 | 100 | 4 | 4 |
| 5 | 101 | 5 | 5 |
| 6 | 110 | 6 | 6 |
| 7 | 111 | 7 | 7 |
| 8 | 1000 | 10 | 8 |
| 9 | 1001 | 11 | 9 |
| 10 | 1010 | 12 | A |
| 11 | 1011 | 13 | B |
| 12 | 1100 | 14 | C |
| 13 | 1101 | 15 | D |
| 14 | 1110 | 16 | E |
| 15 | 1111 | 17 | F |
| 16 | 10000 | 20 | 10 |
É fácil ver como os números “voltam” para 0 e incrementam o algarismo a esquerda quando não há mais símbolos para representar o próximo, e o nosso sistema decimal com o qual estamos tão acostumados faz exatamente a mesma coisa.
Quanto a 3., em todos os sistemas númericos, o número 0 indica um valor nulo e adicionar 0 a qualquer número não modifica seu valor, isso é um ponto importante que todos sistemas númericos citados compartilham.
Uma forma interessante de pensar para lermos o valor de qualquer número, é que cada algarismo tem um valor igual a
\[Valor*Tamanho^{Posição}\]
Valoré o valor individual do algarismoTamanhoé a quantidade de símbolos que o sistema númerico tem (2para binário,8para octal,10para decimal, etc)Posiçãoé posição do algarismo da direita para esquerda, iniciando em0.
A mesma regra se aplicar a números decimais, por exemplo, no número 342, podemos decompor ele como 3*10^2 + 4*10^1 + 2*10^0 que seria 300 + 40 + 2, resultando em 342.
Logo podemos decompor o número binário 0b101na expressão 1*2^2 + 0*2^1 + 1*2^0, que pode ser decomposto em 4 + 0 + 1 resultando em 5.
Chamamos essa forma de notação posicional.
Conversão binário para decimal
Como números binários só tem 2 algarismos, podemos simplificar um pouco o pensamento na hora de realizar o cálculo para converter números binários para decimal.
A técnica utilizada continua sendo a de pegar cada algarismo e avaliar seu valor usando a notação posicional, porém como só temos dois valores possíveis (0 ou 1), podemos facilitar a conversão escrevendo previamente o resultado das potências de dois.
Considere a conversão do número binário 0b101101 para decimal :
4096 2048 1024 512 256 128 64 32 16 8 4 2 1 //Potências de dois em decimal
1 0 1 1 0 1 //Número binário
Todos os algarismos em 1 representam números decimais que serão adicionados no cálculo, logo 0b101101 é 32 + 8 + 4 + 1 que resulta em 45.
Podemos aplicar a mesma lógica para números maiores como 0b11010101 :
4096 2048 1024 512 256 128 64 32 16 8 4 2 1 //Potências de dois em decimal
1 1 0 1 0 1 0 1 //Número binário
Com isso teremos 128 + 64 + 16 + 4 + 1 que resulta em 213.
Conversão decimal para binário
Existem duas formas de converter:
- Utilizando a técnica da
notação posicional(fácil para números menores) - Utilizando divisão (ideal para convertermos números grandes ou para quem prefere um método que serve bem para qualquer caso)
Conversão com notação posicional
Para realizar a conversão, podemos escrever as potências de 2 e ir diminuindo a maior potência de dois que seja maior ou igual ao número, anotando um 1 em cada potência usada e 0 nas que não foram utilizadas.
Repetimos o passo até que o número resultante das subtrações seja 0.
Por exemplo, para converter 55 podemos fazer :
64 32 16 8 4 2 1
0 1 1 0 1 1 1
//De forma simplificada
55 - 32 = 23 - 16 = 7 - 4 = 3 - 2 = 1 - 1 = 0
//Passo a passo
55 >= 64 ? 0
55 >= 32 ? 1 (55-32 = 23)
23 >= 16 ? 1 (23-16 = 7)
7 >= 8 ? 0
7 >= 4 ? 1 (7-4 = 3)
3 >= 2 ? 1 (4-2 = 1)
1 >= 1 ? 1 (1-1 = 0)
Agora vamos converter 5000 utilizando o mesmo método :
4096 2048 1024 512 256 128 64 32 16 8 4 2 1
1 0 0 1 1 1 0 0 0 1 0 0 0
5000 - 4096 = 904 - 512 = 392 - 256 = 136 - 128 = 8 - 8 = 0
Conversão com divisão
Outra forma de implementar consiste em realizar divisões por 2 e utilizar os restos da divisão como digitos, o único porém é que os digitos estarão em ordem inversa.
Por exemplo, para convertermos o número 56 para binário (usaremos % como operador de módulo):
//Operações iniciais (resto e divisão)
56 % 2 = 0 (56/2 = 28)
28 % 2 = 0 (28/2 = 14)
14 % 2 = 0 (14/2 = 7)
7 % 2 = 1 (7/2 = 3)
3 % 2 = 1 (3/2 = 1)
1 % 2 = 1 (1/2 = 0)
//Agora precisamos ler os resultados dos restos de baixo para cima
//resultando em 111000
56 //Decimal
0b111000 //Binário
Agora vamos converter um número maior, 9872 :
//Operações iniciais (resto e divisão)
9872 % 2 = 0 (9872/2 = 4936)
4936 % 2 = 0 (4936/2 = 2468)
2468 % 2 = 0 (2468/2 = 1234)
1234 % 2 = 0 (1234/2 = 617)
617 % 2 = 1 (617/2 = 308)
308 % 2 = 0 (308/2 = 154)
154 % 2 = 0 (154/2 = 77)
77 % 2 = 1 (77/2 = 38)
38 % 2 = 0 (38/2 = 19)
19 % 2 = 1 (19/2 = 9)
9 % 2 = 1 (9/2 = 4)
4 % 2 = 0 (4/2 = 2)
2 % 2 = 0 (2/2 = 1)
1 % 2 = 1 (1/2 = 0)
//De forma que
9872 //Decimal
0b10011010010000 //Binário
Números Hexadecimais
No capítulo sobre números binários, já há uma explicação genérica que explica um pouco melhor sobre sistemas númericos num geral e que já da uma noção de como o sistema hexadecimal funciona.
A palavra “hexa” simboliza o número 6, enquanto “deci” simboliza o número 10, de forma que hexadecimal simbolize um sistema númerico de 16 símbolos.
Os símbolos do sistema hexadecimal são : 0, 1, 2, 3, 4, 5, 6, 7, 8, 9, A, B, C, D,E, F.
Podemos também pensar que A = 10, B = 11, C = 12, D = 13, E = 14 e F = 15 para facilitar o entedimento, levando em consideração uma provável familiaridade maior com números decimais.
O sistema númerico hexadecimal é extremamente útil pois ele tem um número de algarismos que é uma potência de dois, que efetivamente pode representar 4 digitos binários para cada digito hexadecimal, num mundo onde um byte é geralmente 8 bits, podemos representar um byte usando dois digitos hexadecimais ao invés de 8 digitos binários.
A vantagem do hexadecimal, é que ele pode ser efetivamente utilizado como uma representação mais compacta de números binários, é por isso que dificilmente veremos programadores utilizarem números binários, pois dificilmente há qualquer vantagem de binário sobre números hexadecimais.
Devido ao uso dos caracteres de A até F é comum utilizarmos um código similar a este para conversão um número representando um digito hexadecimal para caractere :
char hex_to_char(int hex)
{
hex = hex & 0xF; //Limita o número para 0 a 15
return (hex >= 10) ? (hex - 10 + 'A') : (hex + '0');
}
Conversão de binário para hexadecimal
A conversão de binário para hexadecimal é uma das mais fáceis, pois pode ser realizada de forma independente e paralela.
Cada 4 digitos de um número binário equivalem exatamente a um digito hexadecimal, a conversão de cada conjunto de 4 digitos pode ser feita em separado.
Isso é exemplificado na imagem abaixo, que como podem ver, leva a uma conversão extremamente simples :
Onde o número 0b1100101011111110 vira 0xCAFE.
É comum essa conversão ser realizada mentalmente ao convertermos o número binário de 4 digitos para decimal e depois para hexadecimal.
0b1100é12em decimal, em hexadecimalC = 12, entãoC0b1010é10em decimal, em hexadecimalA = 10, entãoA0b1111é15em decimal, em hexadecimalF = 15, entãoF0b1110é14em decimal, em hexadecimalE = 14, entãoE
Conversão de hexadecimal para binário
A conversão de hexadecimal para binário é similar a conversão reversa, podemos converter cada digito hexadecimal em 4 digitos binários.
A conversão envolve converter cada digito individualmente e depois juntar todos, removendo os espaços.
Por exemplo para conversão de ABC para binário teremos :
Aé0b1010em binário (8+2=10(decimal) =A)Bé0b1011em binário (8+2+1=11(decimal) =B)Cé0b1100em binário (8+4=12(decimal) =C)
Logo o número resultante será a junção dos números 1010 1011 1100 (removendo os espaços), resultando em 0b101010111100.
Conversão de hexadecimal para decimal
Para convertermos um número em hexadecimal para decimal diretamente, podemos utilizar a notação posicional, seguindo as mesmas regras já explicadas no capítulo sobre números binários.
Por exemplo para convertermos 0xDC de hexadecimal para decimal :
//A = 10, B = 11, C = 12
//D = 13, E = 14, F = 15
13 * (16^1) //13*16 = 208
12 * (16^0) //12*1 = 12
//Logo, o resultado é
208+12 = 220
Teremos que 0xDC em hexadecimal é o número 220 em decimal.
Para conversão do número 0xFA8 em hexadecimal para decimal, teremos :
15 * (16^2) //15 * 256 = 3840
10 * (16^1) //10 * 16 = 160
8 * (16^0) //8 * 1 = 8
//Logo, o resultado é
3840+160+8 = 4008
Conversão de decimal para hexadecimal
Uma das formas é realizarmos a conversão para binário e depois convertermos de binário para hexadecimal.
Outra forma é utilizar o método da divisão, da mesma forma que utilizamos para binário.
No exemplo abaixo temos a conversão do número 3564 para hexadecimal :
3564 % 16 = 0xC (3564/16 = 222)
222 % 16 = 0xE (222/16 = 13)
13 % 16 = 0xD (13/16 = 0)
//Assim como no caso de números binários
//precisamos ler o resultado de baixo para cima
//Nesse caso ele resulta em :
0xDEC
Terminal
Um terminal de computador é um dispositivo eletrônico ou eletromecânico capaz de transcrever e receber dados de um computador. A transcrição dos dados geralmente é realizada através de um teclado.
Os primeiros “terminais” eram dispositivos com tela, capazes de transcrever caracteres digitados em um teclado e renderizar a entrada do usuário junto da resposta do computador em uma interface baseada em texto, que ainda deveriam ser conectada a um computador que fará o processamento real dos comandos.
Os terminais funcionam enviando os dados de texto digitados pelo usuário e recebendo de volta dados de texto da resposta do sistema ao qual ele está interligado, que são mostrados graficamente em seu visor.
As mensagens de terminais são históricamente finalizadas com o caractere especial \n, que indica uma sinalização de nova linha.
Um dos terminais mais conhecidos é o VT-100, demonstrado na imagem a seguir:

O VT-100 apresenta uma interface serial, que pode ser conectada a um computador para realizar a comunicação entre eles, sistemas operacionais como o linux apresentam drivers para uso do VT-100 que é suportado e pode ser utilizado mesmo nos dias de hoje.
No linux, é comum que terminais conectados em hardware sejam expostos como “arquivos” no caminho /dev/ttyX, onde X indica o número do terminal (o nome tty vem de “teletypewriter” literalmente “teletipo” em inglês).
Terminais simulados criados via software são geralmente denominados de pty no linux no caminho /dev/ptyX com X indicando o número do terminal, o p no nome simboliza a palavra “pseudo”.
O diagrama a seguir demonstra a organização do kernel do linux ao conectar um terminal externo a uma aplicação dentro do sistema operacional:
Emuladores de Terminais
Com a evolução dos computadores e o advento de sistemas operacionais mais modernos, deixou de existir a necessidade de hardwares dedicados de terminal, que foram substituidos por emuladores de terminais ou hosts de console.
Emuladores de terminais são programas que replicam o comportamento de um terminal dedicado em hardware dentro de um sistema operacional, ao fornecer um programa que lê entrada do usuário (geralmente do teclado), renderiza texto baseado na resposta do programa e na entrada do usuário e replica as mesmas funcionalidades que um terminal dedicado em hardware suportava.
Já “hosts de console” são programas que efetuam uma funcionalidade similar a um emulador de terminal, mas não o fazem com intuito de emular um hardware existente, como é o caso do processo conhost.exe, responsável por fornecer essa interface no Windows.
O uso de emuladores de terminal é comum em sistemas baseados em UNIX, como Linux e macOs, assim como históricamente, o Windows é conhecido por implementar um host de console, sem tentar imitar um hardware existente.
Lembrando que emuladores de terminais e hosts de console “são burros”, eles só executam a tarefa de obter dados do usuário e desenhar texto na tela, limpar a tela, etc. A execução dos comandos é geralmente delegada a um software denominado de shell.
Entradas e Saídas padrão
Antes de falar sobre shell, é importante entender o que é são as “entradas e saídas” padrão de um processo.
Desde o sistema UNIX na década de 1970, existem normalmente 3 arquivos denominados stdin (Entrada padrão), stdout (Saída padrão) e stderr (Saída de erro padrão).
Esses arquivos indicam de onde o programa deve ler dados, escrever e onde ele deve reportar erros que ocorreram durante sua execução.
É comum que ao abrir um programa em um sistema operacional, a stdin aponte para a saída de um terminal e a stdout aponte para a entrada de um terminal, para que stdin possa ler os comandos que o usuário digitou e stdout possa escrever no terminal.
Inclusive esses 3 arquivos podem ser “redirecionados”, chamamos de redirecionamento quando modificamos o arquivo que será utilizado como entrada, saída ou saída de erros.
Com isso podemos apontar para outros arquivos, permitindo que a entrada/saída sejam utilizadas para realizar comunicação entre processos, escrever em arquivos no disco/SSD, comunicação via rede, etc.
Essa redireção normalmente é realizada ao abrir o processo, utilizando as funções posix_spawn, clone ou fork aliadas a dup2 no Linux ou a função CreateProcessW no Windows.
Shell
O shell é um programa que atua como uma interface ao sistema operacional, fornecendo uma forma de executar comandos e scripts.
Os primeiros programas de shell eram simplesmente programas que permitiam chamar outros programas e redirecionar a saída e entrada deles.
Logo o acesso a várias funcionalidades do sistema pelo terminal são normalmente delegadas a outros programas que realizam cada tarefa individualmente.
Porém, logo percebeu-se que apenas chamar programas era um tanto limitante, para resolver essas limitações diferentes pessoas e empresas desenvolveram novos programas de shell que incluiam linguagens de script mais completas, que permitiam criação de variáveis, condicionais, loops, entre outras funcionalidades.
Dessa forma nasceram diferentes linguagens de script shell, que serão detalhadas em seguida.
A figura a seguir demonstra um diagrama da comunicação entre os programas envolvidos no processo de execução de um programa do usuário pelo terminal:
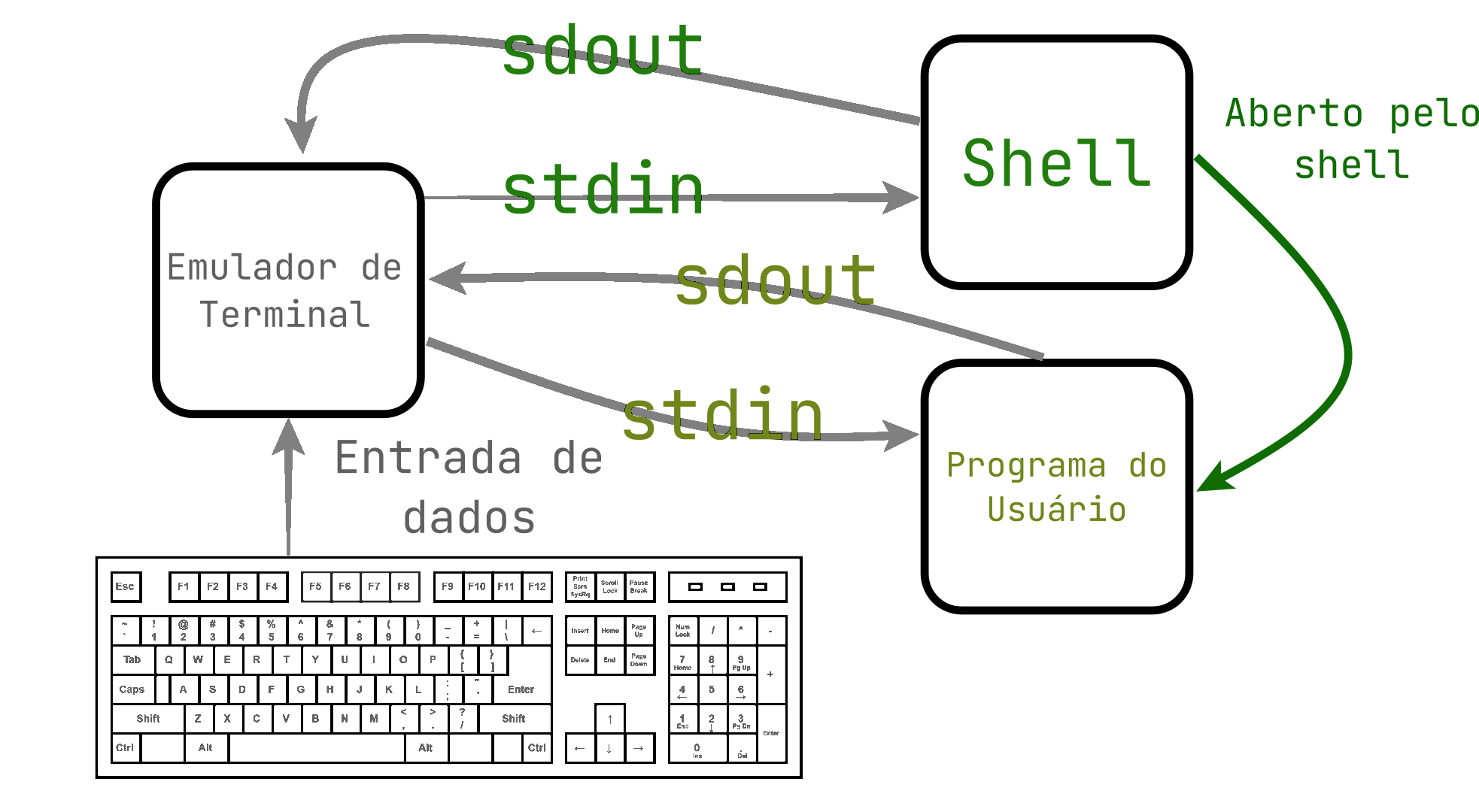
Linguagens de script para Shell
Como mencionado anteriormente, as linguagens de script para shell nasceram como algo simples, que só chamava outros programas, ao longo do tempo várias novas linguagens foram desenvolvidas, sendo muitas delas extensões baseadas em linguagens anteriores, como aconteceu com o bourne shell que foi considerado inspiração para o desenvolvimento de shells como bash, ksh, zsh.
Linguagens de script conhecidas :
batch: Utilizada como a linguagem de script convencional do windows baseado no interpretador de comandos legado do DOS, aceitando arquivos de script em.bat, tem suporte a variáveis,goto, condicionais, loops.Powershell: Linguagem de script avançada do Windows, com funcionalidades modernas e documentação extensa, orientada a objetos baseada na plataforma.NET.bash: Shell desenvolvido pelo projeto GNU e é o shell mais comum encontrado em distruições Linux, normalmente visto como o menor denominador comum, onde outros shells são utilizados quando novas funcionalidades são desejáveis.zsh: Shell padrão utilizado no macOs mas também muito utilizado em distribuições Linux.ksh: Um shell mais antigo bastante similar aobash, a maioria dos sistemas UNIX que não são Linux como Solaris e outros usam okshcomo padrão, enquanto no Linux é mais comum o uso dobash.sh: É uma especificação do POSIX, normalmente servindo como atalho para oshellutilizado pelo sistema operacional, onde oshellefetivamente usado será outro, mas deve seguir as especificações, fornecendo uma interface comum similar a outras linguagens deshell.
Sintaxe comum das linguagens de script Shell
Existem muitas funcionalidades em comum presentes em várias linguagens de shell utilizadas nos sistemas operacionais modernos, se limitar as funcionalidades mais básicas permite que um script seja facilmente adaptável em diferentes sistemas com pouco esforço.
Apesar de existirem várias diferenças, o powershell costuma ter uma compatibilidade maior com parte das funcionalidades mais modernas e da sintaxe do bash em relação ao batch.
Caminhos e navegação
No mundo UNIX, o separador de caminhos é normalmente /, enquanto no Windows, apesar de suportar esse separador, o separador de caminhos nativo é o \.
Os interpretadores de script shell e funções do sistema de arquivos normalmente utilizam . para indicar a pasta atual e .. para indicar a pasta anterior.
O comando cd pode ser utilizado para modificar a pasta atual, utilizar caminhos relativos permite realizar uma “navegação em pastas” utilizando o terminal.
#Funciona em qualquer sistema
cd .. #Volta uma pasta
cd imagens #Entra na pasta imagens
#Sistemas UNIX
cd /usr/bin #Entra na pasta /usr/bin
#Windows
cd C:\ #Entra no disco C:\ do windows
Variáveis
As variáveis de ambiente do sistema normalmente podem ser acessadas como variáveis diretamente no shell, no batch uma variável pode ser acessada utilizando %variavel%, enquanto no powershell, bash e outros utilizando $variavel.
Para criar novas variáveis, podemos utilizar $variavel = valor no powershell, bash e afins, enquanto para o batch é necessário preceder o comando com a palavra chave set (ex: set variavel = valor).
É normal que ao procurar por programas para executar com um comando, o shell procure em todas pastas listadas na variável de ambiente PATH, que indica caminhos adicionais que devem ser buscados.
Executar programas
Normalmente existem 3 formas de escrever um caminho para executar um programa :
programa: Procura nas pastas da variávelPATHe na pasta atual./programa: Procura na pasta atual utilizando um caminho relativo/usr/bin/programa: Caminho completo
(Lembrando que a / deve ser substituida por \ no Windows)
Para executar um programa, é normalmente utilizada a sintaxe:
./programa argumento1 "argumento 2"
Onde programa é o caminho do programa e os argumentos da linha de comando utilizados para executar o programa são separados por espaço.
Para incluir espaços dentro do argumento, é necessário colocar o argumento entre aspas.
No powershell, podemos utilizar $variavel = ./programa para que a variavel receba a saída do programa (o que foi escrito na stdout). Enquanto que no bash e outros
shells precisamos utilizar $variavel = $(./programa) para a mesma funcionalidade.
Redirecionar saídas e entradas
Para redirecionar saídas e entradas, podemos utilizar :
>: Redireciona a saída (stdout)<: Redireciona a entrada (stdin)2>: Redireciona a saída de erros (stderr)&>: Redireciona a saída normal e de erros (stdoutestderr)>>: Redireciona a saída no modoappend, onde dados são adicionados ao fim do arquivo (stdout)2>>: Redireciona a saída de erros no modoappend(stderr)&>>: Redireciona a saída normal e de erros no modoappend(stdoutestderr)|: Faz com que a saída do primeiro programa (stdout) se torne a entrada do próximo (stdin)
Por exemplo, para abrir um programa que lê sua entrada de entrada.txt e escreve em resposta.txt e reporta erros em erros.txt:
./programa < entrada.txt > resposta.txt 2> erros.txt
Para utilizar | (denominado de pipe), para que o programa1 tenha sua saída conectada a entrada do programa2:
./programa1 | ./programa2
Obtenção do código de saída
O shell sempre mantêm o código de saída do último programa executado em uma variável específica:
batch: Na variável%errorlevel%bash,zshe afins: Na variável$?powershell: Na variável$LASTEXITCODE
Comandos em comum
O comando echo pode ser utilizado para escrever um argumento saída padrão e é suportado por todas as linguagens de shell (echo a escreve a).
O comando mkdir pode ser utilizado para criar uma pasta e rmdir para apagar uma pasta vazia.
Apesar de ter comandos “similares” muitos, se não a maioria deles podem funcionar de forma um pouco diferente no powershell em relação a sua contraparte utilizado no bash.
Os seguintes comandos não existem no batch, mas estão presentes como apelidos para outros comandos no powershell e como executáveis em sistemas como Linux, macOs e outros sistemas que seguem o POSIX:
clear: Limpa a tela do terminalls: Lista todos arquivos em uma pastacat: Escreve o conteúdo do arquivo especificado nastdoutcp: Copia um arquivo ou pastamv: Renomeia/move um arquivo ou pastarm: Apaga um arquivo ou pastasleep: Pausa o terminal porXsegundos (Xé o argumento númerico especificado)curl: Utilizado para realizar e testar requisições em vários protocolos de comunicação (Suportando 28 protocolos diferentes, incluindo HTTP, FTP, SMB)diff: Indica as diferença entre dois arquivosman: Exibe um manual do comando especificado no próprio terminaltee: Lê dastdine escreve nastdoute numa lista de arquivos, o que foi lidokill: Finaliza o processo com o ID especificado
Leitura do terminal no C
Por mais trivial e simples que pareça ser uma simples leitura do terminal, existem diversas funções diferentes que podem ser utilizadas para leitura do terminal, todas com suas próprias vantagens/desvantagens.
scanf: Extremamente simples de utilizar e já realiza conversões de forma fácil, boa para casos onde a entrada sempre respeita um formato fixo e tamanho esperado, mas péssima para leitura de entrada do usuário, pela dificuldade ou impossibilidade de tratar erros e facilidade de causar problemas de segurança.fgets: Melhor função para leitura de linhas que é padrão do C, inclui o caractere de nova linha no texto obtido, limitando para que seja escrito no máximotamanho-1de forma que o último caractere escrito seja o\0, seu único defeito é que essa função não reporta o tamanho da string e nem quando um caractere de nova linha não foi encontrado, sendo necessário chamarstrlene checar manualmente.GNU readline: Na biblioteca padrão do Linux do grupo GNU, aglibc, existe uma função chamadareadlineque retorna a string lida alocada dinamicamente, que depois deve ser liberada comfree, a função também oferece capacidade de utilizar edição de linha e histórico de comandos.GNU getline: Também uma extensão do GNU naglibc, recebe um buffer pre-alocado do usuário commalloce o expande internamente utilizandorealloccaso necessário, não apresenta as funcionalidades extras de histórico e edição dareadline.ReadConsoleW: Função específica do Windows para leitura de terminal, lê strings em UTF-16 independente das configurações de locale do usuário, é a forma recomendada de ler do terminal no Windows, essa função também reporta o número de bytes lidos e inclui\r\n(o terminador de nova linha do Windows) no buffer.
Nos casos onde deseja-se ler valores que não são strings, como inteiros e ponto flutuantes, saiba que o terminal sempre entrega os valores em texto, o ideal é utilizar funções como strtol, strtof, strtod ou até mesmo sscanf, inclusive a maioria das linguagens de alto nível seguem o padrão de leitura + conversão que difere do padrão encontrado em scanf.
Ao realizar esse guia, investigamos o código fonte do CPython e .NET Core usado e desenvolvido em C# para fins comparativos.
O CPython utiliza a função ReadConsoleW no Windows, readline do GNU no Linux e fgets em outros lugares.
O .NET Core utiliza a função ReadConsoleW no Windows e lê diretamente utilizando funções nativas como open e read nos sistemas UNIX (como Linux, macOs e afins). A diferença é que a leitura é bufferizada e depois extraida caractere por caractere para preencher a string retornada ao usuário por funções alto nível como Console.ReadLine.
Para isso também foi realizada uma implementação própria para leitura de linhas de um arquivo qualquer (normalmente stdin) utilizando como base a função fgetc e outra com fgets:
Clique para Expandir/Retrair
enum readline_result{
READLINE_OK, //A linha foi lida com sucesso
READLINE_PENDING_CHARS, //Não há espaço para a string inteira
READLINE_EOF, //Final do arquivo foi atingido
READLINE_FILE_ERR, //Erro no arquivo
READLINE_INVALID_PARAM, //Parâmetro inválido
};
/**
* @brief Lê uma linha do arquivo especificado sem incluir o caractere de nova linha
* @param buffer Buffer onde os dados serão escritos
* @param size Ponteiro para tamanho do buffer na entrada, bytes lidos na saída
* @param file Arquivo do qual será lido (geralmente stdin)
* @return Resultado da função, indicando erro ou leitura completa
*/
enum readline_result my_readline(char *buffer, size_t *size, FILE *file)
{
enum readline_result result = READLINE_PENDING_CHARS;
if(buffer == NULL || size == NULL || *size == 0)
return READLINE_INVALID_PARAM;
char *basebuf = buffer;
char *endbuf = buffer + *size;
for(;buffer < endbuf; buffer++) {
int c = fgetc(file);
if(c == EOF || c == '\n') {
result = (c == '\n') ? READLINE_OK :
(feof(file)) ? READLINE_EOF
: READLINE_FILE_ERR;
break;
}
*buffer = (char)c;
}
*buffer = '\0';
*size = (buffer - basebuf);
return result;
}
//Versão de `fgets` seguindo o padrão
enum readline_result fgets_readline(char *buffer, size_t *size, FILE *file)
{
if(buffer == NULL || size == NULL)
return READLINE_INVALID_PARAM;
char *result = fgets(buffer, *size, file);
unsigned char had_newline = 0;
if(result != NULL) {
*size = strlen(buffer);
//Remove o "\n"
had_newline = (buffer[*size-1] == '\n');
buffer[*size-1] = '\0';
*size--;
} else {
*size = 0;
}
if(feof(file))
return READLINE_EOF;
if(result == NULL)
return ferror(file) ? READLINE_FILE_ERR : READLINE_INVALID_PARAM;
else
return had_newline ? READLINE_OK : READLINE_PENDING_CHARS;
}
Essas funções repassam todos possíveis casos de erro como retorno da função além do tamanho, lidando propriamente com todos os casos problemáticos, a ideia de utilizar fgetc foi parcialmente inspirada pelo código fonte do .NET Core.
Sequências de Escape VT-100
O terminal VT-100 e seus sucessores apresentavam funções extras usando as chamadas sequências de escape.
Se olharmos na tabela ASCII, veremos que o código 0x1B (27), é utilizado para representar o “escape”, que normalmente sinaliza o início de um comando especial.
Ao enviar um comando de sequência de escape pela stdout, um programa pode sinalizar ao terminal uma ação especial.
Utilizando as extensões de sistemas operacionais modernos em conjunto com as sequências de escape do VT-100 é possível :
- Posicionar o cursor
- Alterar visibilidade do cursor
- Alterar formato do cursor
- Modificar o scroll do terminal
- Inserir/remover linhas e caracteres ou limpar a tela
- Mudar a cor do texto e do fundo
- Obter informações do terminal como a posição do cursor
No Windows, as sequências de terminal VT-100 só foram adotadas recentemente, desde o Windows 10, pois antes era necessário chamar várias funções para manipular propriedades específicas do terminal, a própria Microsoft aconselha que essas sequências sejam utilizadas em código moderno para garantir uma compatibilidade maior com sistemas baseados em UNIX como Linux e macOs.
Muitos cursos de C ensinam a limpar a tela do terminal utilizando system("cls"), este comando só funciona no Windows e ainda é extremamente ineficiente, pois a função system abre um novo processo do shell para executar o comando e espera até que ele finalize.
Utilizar as sequências de escape garante uma compatibilidade com mais sistemas operacionais, maior performance, além de permitir que os comandos sejam embarcados em arquivos e acionados ao escrevê-los no terminal.
Para utilizar a maioria das sequências de escape suportadas no Windows, Linux e macOs, podemos utilizar uma biblioteca própria feita pelo autor deste guia denominada vt100.h.
Para limpar a tela de forma similar a system("cls"), utilize a macro VT100_CLEAR_SEQUENCE, que realiza as 3 ações de mover o cursor, limpar a tela atual e o scroll.